Multi-channel Pose-aware Convolution Neural Networks for Multi-view Facial Expression Recognition
Multi-channel Pose-aware Convolution Neural Networks for Multi-view Facial Expression Recognition
大体浏览
我们知道识别多角度的面部表情是比较困难的,本文提出Multi-channel Pose-aware Convolution Neural Networks(MPCNN)来充分利用有限的数据,对多角度的面部表情进行识别。MPCNN包含三个部分:
- multi-channel feature extraction
- jointly multi-scale feature fusion
- pose-aware recognition
网络结构如图所示:
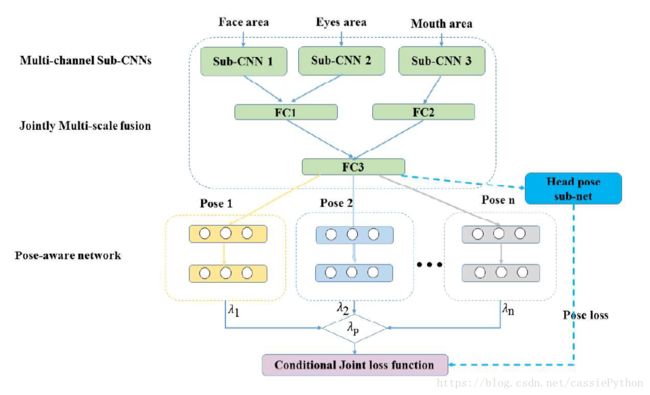
multi-channel feature extraction就是图中的Multi-channel Sub-CNNs,它由3个sub-CNNs组成,功能就是从不同的area中学习convolutional features;
jointly multi-scale feature fusion的作用是将convolutional features进行组合以获得更高层次的feature;
pose-aware recognition,利用特定的角度的识别网络,对上一层得到的特征进行识别,此外Head pose sub-net用于解决pose variance。jointly multi-scale feature fusion得到的特征会输入到所有的Pose-aware network中,对每一个Pose-aware network的输出设置一个权重 λ λ 。 λp λ p 表示是哪一种角度的概率,用于计算下面的Conditional Joint loss function。图中虚线部分表示只在训练时使用。
我们现在脑海中浮现出一些问题:
- Face area,Eyes area,Mouth area是如何得到的;
- Sub-CNNs得到的feature是如何进行组合(fusion)的;
- Head pose sub-net到底是用来做什么的,即为什么要有它的存在;
- Pose-aware networks最后的权重的设置,即为什么要设置这些权重,怎么设置;
- Pose loss和Condition Joint loss是什么鬼
在下面一节中,我们来关注这些问题。
细节掌握
1. multi-channel feature extraction:
通常我们使用CNNs对整幅图进行特征的提取,这里作者使用CNNs来对面部不同的区域和尺寸进行特征的提取(称为scale-normalized extrators)。定义 (M1;M2;M3) ( M 1 ; M 2 ; M 3 ) 表示3通道sub-CNNs。每个通道的输入数据来源于不同的区域和尺寸。这样做的好处是可以有效的利用有限的数据,而且特征提前会更加robust。
我们先来看 M1 M 1 :用于对整个面部区域进行特征提取。首先会将输入图片归一化为200 × × 200的尺寸。 M1 M 1 包含3个卷积层,3个最大池化层(交替存在),之后再有三个池化层。对于卷积层,filter的size是5 × × 5,channel分别是32,64,64。
我们再来看 M2 M 2 :用于对眼睛区域进行特征提取,该区域大概占整幅图的1/3,输入图片归一化为140 × × 140,filter的size是5 × × 5,channel分别是16,32,32。
最后来看 M3 M 3 :用于对嘴部区域进行特征提取,同样大概占整幅图的1/3,输入图片归一化为140 × × 140,filter的size是5 × × 5,channel分别是16,32,32。
这样我们就解决了上面第一个问题:Face area,Eyes area,Mouth area是如何得到的。
2. jointly multi-scale feature fusion:
使用两层fusion layers来组合不同尺寸和不同通道的特征(即图中的FC1,FC2和FC3)
目的:为了更好的利用有限的数据,提高特征表示的能力,减少全连接层的神经元个数(如果不进行特征的组合,针对不同的channel需要不同的全连接层,从而会需要更多的神经元个数)。
我们来看下Multi-scale fusion的伪代码。

这个非常简单,和图中一样,Sub-CNN1和Sub-CNN2的输出特征进行concat,然后FC1和FC2的输出特征进行concat(怀疑论文中把concat写成了contat)。但是有个问题,为什么作者要这样concat呢?面部特征和眼部特征组合,然后再把嘴部特征组合?作者在论文中并没有给出说明。
这样我们解决了第二个问题:Sub-CNNs得到的feature是如何进行组合(fusion)的。
3. pose-aware recognition:
pose-aware recognition networks包含两部分:
- multiple pose-specific recognition branches;
- a pose estimation sub-network。
前者的作用是通过减小pose conditional expression recognition loss和pose estimation loss来进行表情的识别。
给定角度(pose) p p ,pose conditional expression recognition loss为 L(e|p) L ( e | p ) 。表示pose为 p p 的训练集样本的真是标记与预测值带来的损失。 L(e|p) L ( e | p ) 定义为:
其中 NB N B 表示训练时的mini-batch的数据量, yp∈{0,1}E y p ∈ { 0 , 1 } E 表示面部表情的labels, E E 表示表情的种类数。 y^p∈RE y ^ p ∈ R E 表示在pose为 p p 条件下网络得出的预测值。
对于pose estimation sub-network,pose estimation loss定义为:
其中 P^∈{0,1}P P ^ ∈ { 0 , 1 } P 表示pose labels, P P 表示pose的种类数。 P^∈RP P ^ ∈ R P 表示pose estimation sub-network的预测值。
通常情况下的思路是单独分别优化pose estimation sub-network和pose conditional expression recognition。但是本文是end-to-end的方式,将两者的损失同时进行优化。Pose estimation loss Lp L p 用于指导pose-specific recognition branch从conditional joint loss中进行学习。这个condition joint loss,即两种损失的组合,定义为:
其中 λp∈[0,1] λ p ∈ [ 0 , 1 ] 表示head pose p p 的概率,用于平衡不同的pose的贡献,这个值由pose estimaiton sub-network提供。换言之,pose estimation sub-network输出了一张图片属于哪种view(角度)的概率,利用这个概率作为权重,可以衡量对expression recognition network的影响,由此减少了pose variance的影响。 λhpe λ h p e 是一个经验值,设置为0.5。
至此,我们已经解决了前面所说的所有问题。下面给出更清楚的网络结构。
网络结构如图所示:
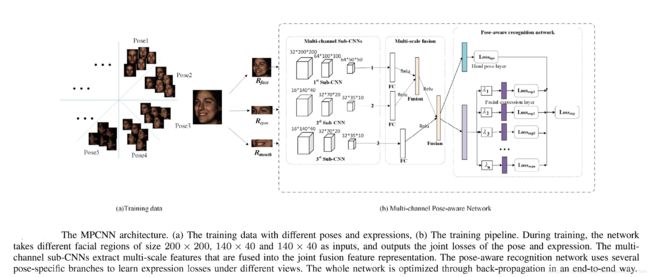
4. test过程:
这里我们来看下这个网络是如何进行预测的,即对于测试集图片如何得到最终的预测结果。测试过程如下图所示:
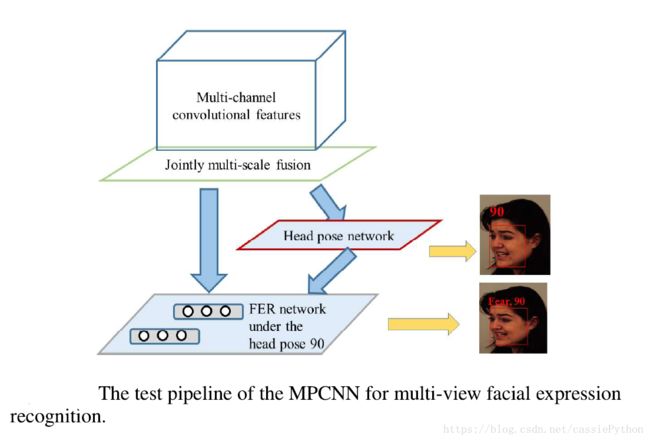
该过程分为三步:
- multi-channel convolutional feature extraction
- joint fusion feature representation
- pose-aware expression recognition
第一步:给定一张测试集的图片,首先与训练时一样,先得到不同的面部区域和尺寸,然后利用已经训练好的multi-channel convolution networks得到特征;
第二步:将该特征输入到joint multi-scale fusion网络(即网络结构图中的FC层),得到组合的特征(1536维的特征),该特征用于判断角度,同时输入到下面的pose-aware 网络中;
第三步:根据已知的角度,输入到特定的(对应的)pose-aware expression network中,得到最终的结果。