利用DeepStream SDK 3.0突破智能视频分析的限制
翻译自:https://devblogs.nvidia.com/intelligent-video-analytics-deepstream-sdk-3-0
一张图片胜过千言万语,视频有数千张图片。两者都包含通过智能视频分析(IVA)的力量揭示的令人难以置信的洞察力。
NVIDIA DeepStream SDK加速了可扩展IVA应用程序的开发,使开发人员更容易构建核心深度学习网络,而不是从头开始设计端到端应用程序。
DeepStream SDK 2.0在前一篇文章中有详细介绍,它支持将IVA应用程序实现为基于GStreamer多媒体框架的硬件加速插件流水线,如图1所示。这些插件支持视频输入,视频解码,图像预处理,基于TensorRT的推理,跟踪和显示。 SDK提供开箱即用的功能,可快速组装灵活的多流视频分析应用程序。
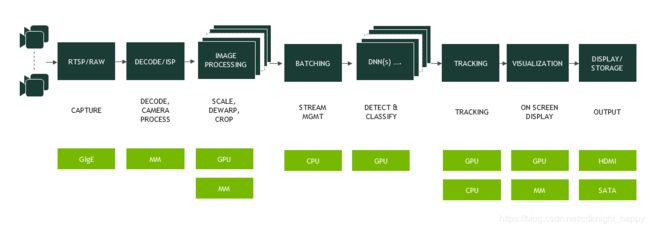 图1 NVIDIA Tesla T4上的DeepStream处理流水线示例
图1 NVIDIA Tesla T4上的DeepStream处理流水线示例
最新的DeepStream SDK 3.0通过提供许多新功能来扩展这些功能。包括对TensorRT 5,CUDA 10和图灵GPU的支持。 DeepStream 3.0应用程序可以作为更大的多GPU集群或容器中的微服务的一部分进行部署。这允许高度灵活的系统架构并开辟新的应用程序功能。
新SDK还支持以下新功能:
- 动态流管理,可以添加和删除流,以及帧速率和分辨率更改;
- 增强了视频流水线中的推理功能,包括支持自定义层,迁移学习和用户定义的检测器的输出解析;
- 使用GPU加速的去扭曲库支持360度相机采集的输入;
- 自定义元数据定义,支持特定应用的丰富见解;
- 易于与流和批量分析系统集成以进行元数据处理;
- 提供了大量的参考应用程序集的源代码;
- NVIDIA的Transfer Learning Toolkit提供了修剪和高效的模型支持;
- 能够使用NVIDIA Nsight系统分析器工具获得详细的性能分析。
本文将详细介绍新功能以及如何构建可扩展的视频分析应用程序。最新的DeepStream 3.0 SDK提供了以下硬件加速插件,使实现变得简单,如表1所示。
表1 DeepStream的插件列表
| 插件名称 | 作用 |
|---|---|
| gst-nvvideocodecs | H.264和H.265视频解码 |
| gst-nvstreammux | 流聚合和组批 |
| gst-nvinfer | 基于TensorRT的检测和分类推理 |
| gst-nvtracker | 目标跟踪参考实现 |
| gst-nvosd | 屏幕显示,用于突出显示对象和添加文本信息 |
| gst-tiler | 视频帧从多源渲染到2D网格阵列 |
| gst-eglglessink | 加速基于X11/EGL的展示 |
| gst-nvvidconv | 缩放,格式转换和旋转 |
| gst-nvdewarp | 反扭曲360度摄像头输入 |
| gst-nvmsgconv | 元数据生成和编码 |
| gst-nvmsgbroker | 传递消息到云端 |
1 视频流处理和管理
DeepStream 3.0增加了一些功能,以促进灵活的流管理。它支持多GPU,允许应用程序为特定工作负载选择不同的GPU。该功能允许在系统中可用的各种GPU之间进行静态和自适应的视频处理调度。可以基于流的数量,视频格式,用于分析的深度学习网络的分组和存储器来分配工作负载。
1.1 动态添加和删除输入源
DeepStream 3.0支持动态添加和删除输入源。
开发人员可以轻松创建新的源代码箱以添加流并将其集成到应用程序中。然后将这些源容器连接到nvstreammux插件的接收器。
nvstreammux插件现在可以创建一个事件来通知新添加的下游组件。该插件支持从实时流水线中删除源的逆流。图2显示了这个过程。
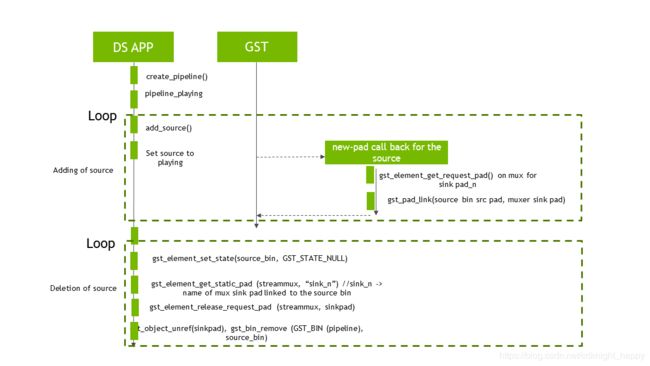 图2.添加或删除流的过程
图2.添加或删除流的过程
1.2 动态分辨率变化,帧率变化,去扭曲
DeepStream 3.0可以在运行时进行分辨率更改。视频解码器重新配置并通知对下游组件的更改,以根据新分辨率集的需要重新初始化。
该应用程序通过设置批量推送时间间隔支持可变帧速率。 nvstreammux插件可以延长低码率视频的等待时间,加快对高码率视频源的帧收集速率。
DeepStream 3.0 SDK还支持使用带鱼眼镜头的360度摄像头。 SDK中包含的gst-nvdewarper插件提供了硬件加速解决方案,可将图像变形并转换为平面投影,如图3所示。减少失真使得这些图像更适合于利用现有的深度学习模型进行处理和观看。目前的插件支持推扫式和垂直平移的基本圆柱投影。
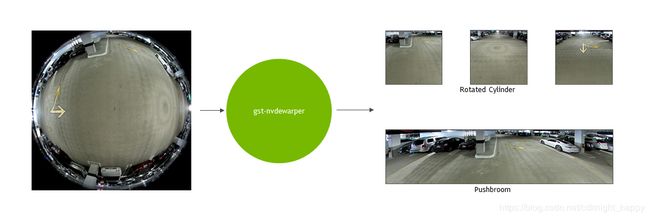 图3. 360度图像及其插件的反扭曲输出
图3. 360度图像及其插件的反扭曲输出
2 推理能力
DeepStream 3.0构建于异构并发深度神经网络功能之上,可用于更复杂的用例。实现基于TensorRT的推理的gst-nvinfer插件现在允许输出层中输出项的数量不受限制。输出类的数量可配置以满足特定的应用程序需求。使用具有噪声的基于密度的的空间聚类算法(DBSCAN)用来对检测器的输出边界框进行聚类。
应用程序现在可以从gst-nvinfer插件的任何推理层访问输入和输出缓冲区。这允许从网络的中间层提取特征以连接到下游深度学习网络或实现定制插件以可视化网络上的激活图。
SDK还允许用户定义用于解析目标检测器输出的自定义函数。这有助于在使用具有不同输出格式的新目标检测模型的结果的后处理过程。
使用TensorRT 5.0定义的IPluginV2接口添加自定义图层可增强SDK的推理灵活性。通过实现SSD和faster R-CNN的网络来说明此功能。推理插件还可以接受ONNX格式的模型和Transfer Learning Toolkit生成的模型。
3 元数据的生成和定制
当DeepStream应用程序分析每个视频帧时,插件会提取信息并将其存储为级联元数据记录的一部分,从而保持记录与源帧的关联。流水线末端的完整元数据集合表示深度学习模型和其他分析插件从框架中提取的完整信息集。DeepStream应用程序可以使用此信息进行显示或作为消息的一部分在外部传输,以进行进一步分析或长期存档。
DeepStream 3.0支持两种主要的元数据类型:
- 由目标检测网络识别的对象的元数据,NvDsObjectParams;
- 有关事件的信息,NvDsEventMsgMeta。
NvDsObjectParams是每帧NvDsFrameMeta结构的一部分,如图4所示。它定义了与帧中检测到的对象相关的各种属性,包括:
- 用于标记对象的坐标和大小的边界框;
- 用于在屏幕上添加的对象的类和属性信息的文本标签;
- 应用程序的开放式字段,用于填充检测到的对象的属性,例如检测到的汽车的品牌,型号和颜色。
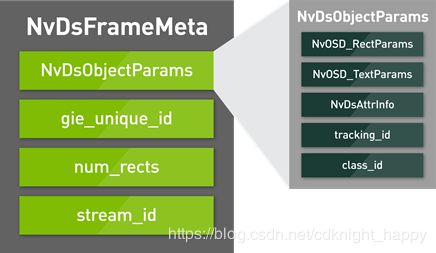 图3 DeepStream3.0的元数据结构
图3 DeepStream3.0的元数据结构
NvDsEventMsgMeta定义了各种事件属性,包括事件类型,定时位置和源。
DeepStream 3.0的一个关键功能是SDK支持的可自定义元数据,为开发人员的自定义神经网络和专有算法启用用户定义的扩展。此自定义数据与DeepStream的流水线体系结构即插即用。
我们建议使用几种技术来实现元数据:
- 使用DeepStream定义的属性NvDsAttrInfo结构可以简单地添加字符串和整数元数据;
- 使用DeepStream定义的Metadata API函数来创建和附加自定义元数据。可以将新的自定义元数据类型添加到NvDsMetaType枚举中,并为自定义元数据定义新结构。将内存分配给自定义元数据,填充元数据信息并使用gst_buffer_add_nvds_meta API将其附加到gstreamer缓冲区。
有关这些的详细信息,请参阅DeepStream 3.0插件手册。
4 消息转换的元数据
DeepStream 3.0提供了将生成的元数据封装为消息并将其发送以供进一步分析的功能。此分析功能对于检测异常,构建位置和移动的长期趋势,构建在云端用于远程查看的信息展示等非常有用。
作为SDK的一部分提供了两个新插件 - gst-nvmsgconv插件接受NvDsEventMsgMeta类型的元数据结构并生成相应的消息。已经定义了一个全面的基于JSON的描述模式,它包含关联对象、发生位置和时间以及基础传感器信息等信息,同时为每个事件属性指定属性。
默认情况下,NvDsEventMsgMeta插件基于DeepStream架构描述生成消息。但是,它还允许用户注册自己的元数据到有效负载转换器功能,以实现额外的可定制性。将自定义元数据描述与用户定义的转换函数结合使用,使用户能够实现完全满足其需求的完全自定义事件描述和消息传递功能。
5 使用后端分析系统的可扩展消息传递
补充消息生成的是gst-nvmsgbroker插件,它使用Apache Kafka协议向Kafka消息代理提供开箱即用的消息传递。Kafka是后端事件分析系统的流水线,包括在云中执行的系统。高消息吞吐量支持与Kafka框架提供的可靠性相结合,使后端架构能够扩展,以支持众多DeepStream应用程序不断发送消息。
gst-nvmsgbroker插件以协议无关的方式实现,并以共享库的形式利用协议适配器。可以修改这些以支持任何用户定义的协议。 SDK的开放接口使其可以非常灵活地扩展和适应特定的部署要求。
图5说明了消息转换和代理插件的组合工作,以将封装检测到的事件的消息传递给后端分析系统。
 图5.可以编码和发送应用程序元数据,以进行进一步的流式处理和批量分析
图5.可以编码和发送应用程序元数据,以进行进一步的流式处理和批量分析
6 性能
作为发布包的一部分,deepstream-app参考应用程序的性能结果突出了Turing的性能改进。图6显示,与上一代Tesla P4相比,在相同流数量、消耗相同功率的情况下,Tesla T4平台上基于DeepStream 3.0的应用程序可提供超过两倍的性能改善。
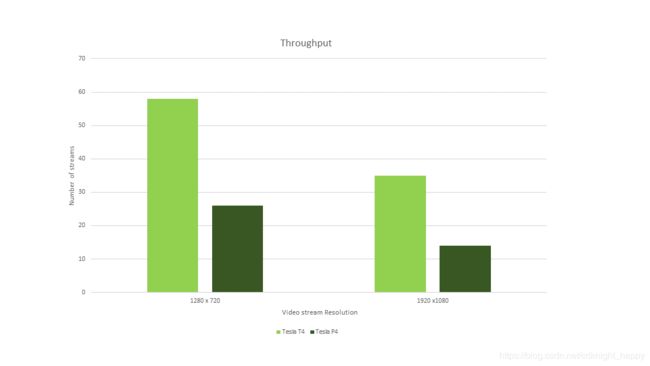 图6. DeepStream参考应用程序的性能测量
图6. DeepStream参考应用程序的性能测量
该应用程序包括一个主检测器,三个分类器和一个跟踪器,如图7中的流程图所示。主检测的批量大小等于流的数量。
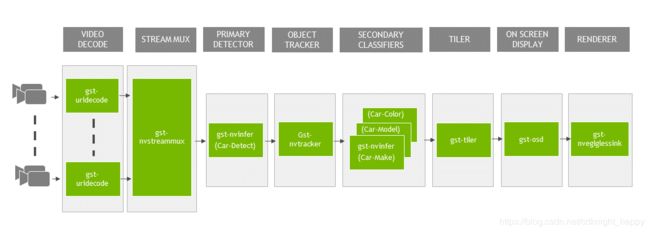 图7. DeepStream参考应用程序图
图7. DeepStream参考应用程序图
7 可度量视频分析
通过基于DeepStream的应用程序在系统层次结构的各个级别实现大规模部署。最新的SDK使用最新的Tesla T4提供实时多流处理功能,进一步增加了支持的流数量。多GPU功能使DeepStream能够定位系统中所有可用的GPU,进一步扩展流的总数以及系统支持的用例的复杂性。Tesla GPU的卓越解码功能及其低功耗可实现数据中心内的高流密度。
容器中的DeepStream提供边缘和数据中心部署的灵活性,可在添加更多视频流时或改变分析任务负载时动态响应需求,如图8所示。
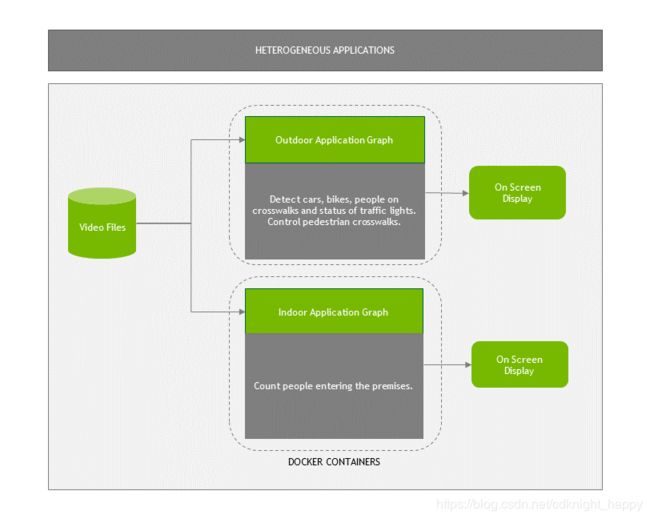 图8.在同一系统上的两个容器中部署DeepStream应用程序
图8.在同一系统上的两个容器中部署DeepStream应用程序
8 在容器中开发
使用DeepStream构建的应用程序现在可以通过Docker容器进行部署,从而实现极其灵活的系统架构,简单的升级和改进的系统可管理性。这些容器可在NVIDIA GPU Cloud(NGC)上使用。