Apollo进阶课程㉖丨Apollo规划技术详解——Understand More on the MP Difficulty
原创: 阿波君 Apollo开发者社区 7月31日

EM是一个在已知部分相关变量的情况下,估计未知变量的迭代技术,EM的算法流程如下:
初始化分布参数;
重复直到收敛。
重复直到收敛的步骤如下:
E步骤:根据隐含数据的假设值,给出当前的参数的极大似然估计;
M步骤:重新给出未知变量的期望估计,应用于缺失值。
约束问题的核心有三点:第一是目标函数的定义,目标函数比较清晰,对于后面的求解更有帮助。第二是约束,比如路网约束、交规、动态约束等。第三是约束问题的优化,比如动态规划、二次规划等。
上周阿波君为大家详细介绍了「进阶课程㉕Apollo规划技术详解——Optimization Inside Motion Planning」。先从对动态规划和二次规划的基本概览出发,然后详细地讲解了二次规划问题的求解方法,通常使用启发式方法。
本周阿波君将继续与大家分享Apollo规划技术详解——Understand More on the MP Difficulty的相关课程。下面,我们一起进入进阶课程第26期。
目录
1.Apollo EM规划框架
2.优化决策问题
3.非线性优化问题
4.规划问题如何解决
5.强化学习和数据驱动方法
本节主要介绍 Apollo 中的 EM planner 。在前面的课程中,我们提到优化问题的三个方面:目标函数、约束条件和求解方法。那么在实际过程中无人车怎样去抽象约束呢?先看一个简单的例子,如下图所示。
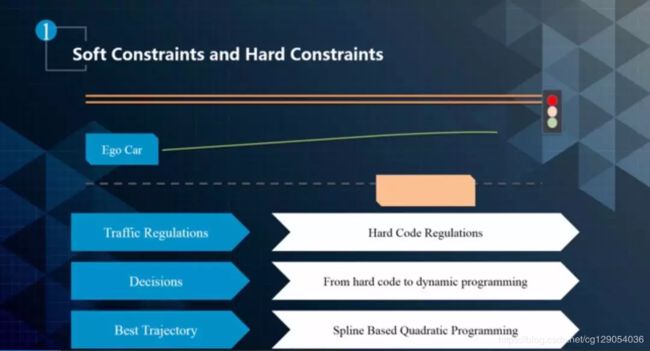
▲硬性限制和软性限制
在这个场景中,有三类约束,第一个叫做 Rraffic Regulation,第二个是 Decisions,第三个是 Best Trajectory 。这些限制又分为硬限制和软限制,例如交通规则属于硬性限制。
1.Apollo EM规划框架
在 Apollo 中,我们设计了一个 EM 规划框架来处理不同的场景,如下图所示,展示处理一个换道场景。在蓝线和红线交点处发现前方有车辆行驶缓慢,可能要进行换道处理。如果只是简单的看到旁边没有车就换道,可能会导致危险发生。在 Apollo EM 规划框架中,我们会对换道和继续在本车道行驶分别规划出一条轨迹,只有换道之后的 Trajectory 要比本车道的 Trajectory 好的情况下才换道。在 Apollo 的 EM planner中,决定哪个道比较好的模块叫做 Reference Line Decider,中间的并行模块是通过 Path Speed Iterative 的方式并行实现的。

▲ Apollo EM 规划框架
2.优化决策问题
优化决策问题本身是一个 3D optimization 问题,其中包含了三个维度,需要生成 SLT 。三维空间的优化相对比较复杂,常用的方法有两种:一种就是离散化的方式去处理。另一种方法是 Expectation Maximization(期望最大化)。其基本思想是降维处理,先在一个维度上进行优化,然后在优化的基础上再对其它维度进行优化,并持续迭代以获得局部最优解。

▲ 3D optimization 问题
对于无人车,Apollo 上的 EM planner 对 Path-Speed 进行迭代优化。首先,生成一条 Optimal Path ,在最优路径的基础上生成 Optimal Speed Profile 。在下一个迭代周期,在优化后的 Speed 的基础上,进一步优化 Path,依次类推。它分了四步走,其中分为两步 E step 和 M step 。这种算法的缺点是不一定能收敛到全局最优解。
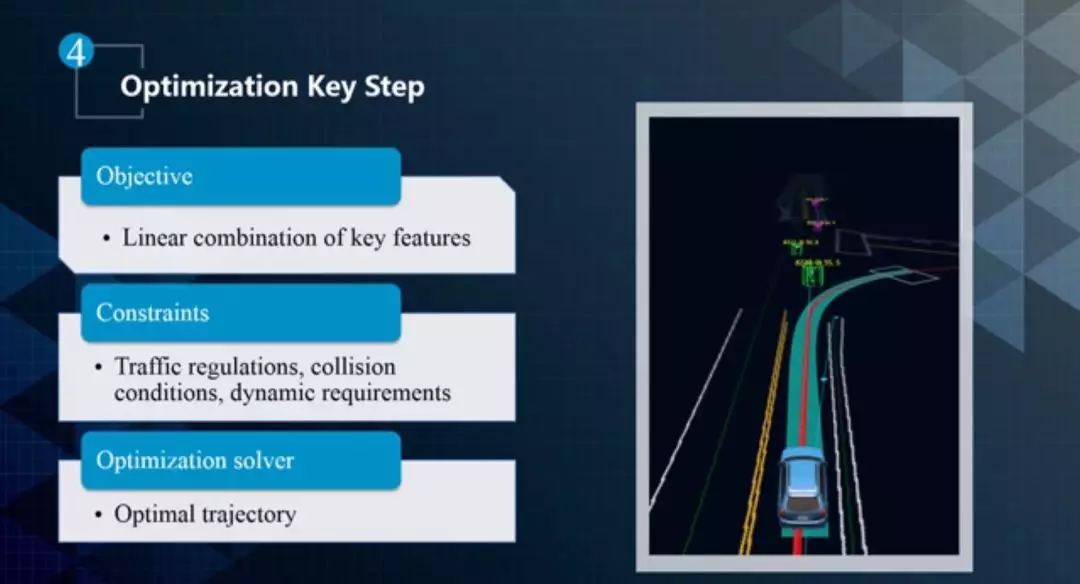
▲优化问题的关键步骤
优化问题的关键步骤包括: Objective Functional、Constraint、Solver。目标函数是一些关键特征的线性组合。约束主要包括交通灯、碰撞以及动态需求等。优化求解方法的目的是找到最佳路径,包括前面讲的动态规划+二次规划的启发式方法。
3.非线性优化问题

▲非线性优化问题的步骤
对于非线性优化问题,通常都是分两步走,一是动态规划,先找一个粗略解。然后再是二次规划,从粗略解出发,找出一个最优解。以路径规划为例,假设前方有一个障碍物,首先做出从左边还是右边的避让决策,然后通过 QP 生成一条平滑的曲线去避让障碍物。对于速度而言,先通过动态规划的方式给出一个粗略的解,然后再通过二次规划的方式给出一个更平滑的解。

![]() ▲路径规划优化
▲路径规划优化
具体来讲,在决策规划里如何动态规划 Path 呢?先确定主车的位置,然后往前排撒若干点,基于撒点网络得到一个代价最低的路径,这时候的路径不够平滑。

▲利用二次规划方法,生成一条平滑的轨迹
然后利用二次规划方法,按照问题抽象、模型建立和优化求解的步骤生成一条平滑的轨迹。
对于速度的优化,同样是类似的,如下图所示。

▲速度规划优化
4.规划问题如何解决
对于逆行的处理,首先根据当前 Speed Profile 去估计当前逆行障碍物的位置,然后再修正 Path,根据修正之后的 Path 再来处理 Speed,例如需要减速。减速之后,估计需要重新改变路径,依此类推,直到得到理想的规划轨迹。

▲规划问题如何解决逆行
目前,百度 Apollo 无人车项目的规划模块进展如下图所示,支持在城市和高速等环境下的多种驾驶场景处理,包括直行、转向、路口、停车。

▲百度Apollo无人车规划模块进展
5.强化学习和数据驱动方法
决策问题通常用 POMDP 加上一些机器学习的技术来解决。在前面我们已经介绍过,解决好规划问题,需要把两个方面做好,一个是数据闭环(Data Driven),另一个是基于规则的方法。数据驱动是在基于规则的闭环里面的小闭环。Rule Based 的方法可以对遇到的新案例,很快给出解决方案。
在基于规则的方法的基础上,对问题形成一定的认识,通过把问题抽象成更加通用的问题,定义目标函数来进一步优化问题。数据驱动的方法就是通过大量的案例统计分析,得到模型,使得遇到类似问题的时候,不需要过多的考虑,直接套用数据驱动的模型获得结果, Data Driven 的方法其实就是基于经验的方法,只不过这些经验是模型通过大量的样本数据学习得到的。