反信用卡欺诈分类
import pandas as pd
from imblearn.over_sampling import SMOTE
from sklearn.preprocessing import StandardScaler
from sklearn.cross_validation import train_test_split
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn import metrics
from sklearn import tree
import xgboost as xgb
from sklearn.neural_network import MLPClassifier
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils.np_utils import to_categorical
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dense, Activation
import numpy as np
from keras.utils import np_utils
df = pd.read_csv(r"C:\Users\ljy\Desktop\Credit-Card-Fraud-Detection-using-Autoencoders-in-Keras-master\data\creditcard.csv")
print(df.head())
print(df.isnull().sum())
print ("Fraud")
print (df.Amount[df.Class == 1].describe())
print ()
print ("Normal")
print (df.Amount[df.Class == 0].describe())
f, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(12,4))
bins = 30#宽度
ax1.hist(df.Amount[df.Class == 1], bins = bins)
ax1.set_title('Fraud')
ax2.hist(df.Amount[df.Class == 0], bins = bins)
ax2.set_title('Normal')
plt.xlabel('Amount ($)')
plt.ylabel('Number of Transactions')
plt.yscale('log')
plt.show()
df['Amount_max_fraud'] = 1
df.loc[df.Amount <= 2125.87, 'Amount_max_fraud'] = 0#设置一个新的特征’Amount_max_fraud’,让他在2125.87以下设置为0,以上设置为1,
print(df.head())
df['normAmount'] = StandardScaler().fit_transform(df['Amount'].values.reshape(-1, 1))#归一化处理
df = df.drop(['Time', 'Amount'], axis=1)
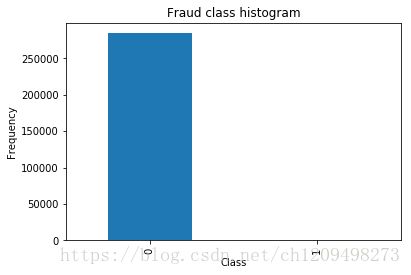
count_classes = pd.value_counts(df['Class'], sort = True).sort_index()
print(type(count_classes))
count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")
plt.show()
def data_prepration(x):
x_features= x.ix[:,x.columns != "Class"]
x_labels=x.ix[:,x.columns=="Class"]
x_features_train,x_features_test,x_labels_train,x_labels_test = train_test_split(x_features,x_labels,test_size=0.3)
print("length of training data")
print(len(x_features_train))
print("length of test data")
print(len(x_features_test))
return(x_features_train,x_features_test,x_labels_train,x_labels_test)
data_train_X,data_test_X,data_train_y,data_test_y=data_prepration(df)
os = SMOTE(random_state=0)
os_data_X,os_data_y=os.fit_sample(data_train_X.values,data_train_y.values.ravel())
'''print(pd.value_counts(os_data_y))
columns = data_train_X.columns
print(os_data_X)
os_data_X = pd.DataFrame(data=os_data_X,columns=columns )
print(len(os_data_X))
os_data_y= pd.DataFrame(data=os_data_y,columns=["Class"])
# 现在检查下抽样后的数据
print("length of oversampled data is ",len(os_data_X))
print("Number of normal transcation",len(os_data_y[os_data_y["Class"]==0]))
print("Number of fraud transcation",len(os_data_y[os_data_y["Class"]==1]))
print("Proportion of Normal data in oversampled data is ",len(os_data_y[os_data_y["Class"]==0])/len(os_data_X))
print("Proportion of fraud data in oversampled data is ",len(os_data_y[os_data_y["Class"]==1])/len(os_data_X))
print(os_data_X)'''
'''
newtraindata=pd.concat([os_data_X,os_data_y],axis=1)
newtestdata=pd.concat([data_test_X,data_test_y],axis=1)
newtraindata.to_csv('../train.csv',sep=',')
newtestdata.to_csv('../test.csv',sep=',')'''
def do_metrics(y_test,y_pred):
print("metrics.accuracy_score:")
print(metrics.accuracy_score(y_test, y_pred))
print("metrics.confusion_matrix:")
print(metrics.confusion_matrix(y_test, y_pred))
print("metrics.precision_score:")
print(metrics.precision_score(y_test, y_pred))
print("metrics.recall_score:")
print (metrics.recall_score(y_test, y_pred))
print ("metrics.f1_score:")
print (metrics.f1_score(y_test,y_pred))
#4172print('sequence len:',seq_len)
seq_length=30
X = np.reshape(os_data_X, (len(os_data_X), 1, seq_length))
y=y = np_utils.to_categorical(os_data_y)
model = Sequential()
model.add(LSTM(32, input_shape=(X.shape[1], X.shape[2])))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X, y, nb_epoch=500, batch_size=1, verbose=2)
scores = model.evaluate(data_test_X.values,data_test_y.values.ravel(), verbose=0)
print("Model Accuracy: %.2f%%" % (scores[1]*100))
'''clf = MLPClassifier(solver='lbfgs',
alpha=1e-5,
hidden_layer_sizes=(5, 2),
random_state=1)
clf.fit(os_data_X,os_data_y)
y_pred = clf.predict(data_test_X)
do_metrics(data_test_y,y_pred)
metrics.accuracy_score:
0.970155542291
metrics.confusion_matrix:
[[82769 2539]
[ 11 124]]
metrics.precision_score:
0.0465640255351
metrics.recall_score:
0.918518518519
metrics.f1_score:
0.0886347390994'''
'''xgb_model = xgb.XGBClassifier().fit(os_data_X,os_data_y)
y_pred = xgb_model.predict(data_test_X)
do_metrics(data_test_y,y_pred)
metrics.accuracy_score:
0.98748873518
metrics.confusion_matrix:
[[84237 1053]
[ 16 137]]
metrics.precision_score:
0.11512605042
metrics.recall_score:
0.895424836601
metrics.f1_score:
0.204020848846
'''
'''clf = tree.DecisionTreeClassifier()
clf.fit(os_data_X,os_data_y)
y_pred = clf.predict(data_test_X)
do_metrics(data_test_y,y_pred)
clf
metrics.accuracy_score:
0.997249628407
metrics.confusion_matrix:
[[85094 209]
[ 26 114]]
metrics.precision_score:
0.352941176471
metrics.recall_score:
0.814285714286
metrics.f1_score:
0.492440604752'''
'''
metrics.accuracy_score:
0.972156876514
metrics.confusion_matrix:
[[82940 2357]
[ 22 124]]
metrics.precision_score:
0.049979846836
metrics.recall_score:
0.849315068493
metrics.f1_score:
0.0944042634183
gnb = GaussianNB()
gnb.fit(os_data_X,os_data_y)
y_pred = gnb.predict(data_test_X)
do_metrics(data_test_y,y_pred)'''
Time V1 V2 V3 ... V27 V28 Amount Class
0 0.0 -1.359807 -0.072781 2.536347 ... 0.133558 -0.021053 149.62 0
1 0.0 1.191857 0.266151 0.166480 ... -0.008983 0.014724 2.69 0
2 1.0 -1.358354 -1.340163 1.773209 ... -0.055353 -0.059752 378.66 0
3 1.0 -0.966272 -0.185226 1.792993 ... 0.062723 0.061458 123.50 0
4 2.0 -1.158233 0.877737 1.548718 ... 0.219422 0.215153 69.99 0
[5 rows x 31 columns]
Time 0
V1 0
V2 0
V3 0
V4 0
V5 0
V6 0
V7 0
V8 0
V9 0
V10 0
V11 0
V12 0
V13 0
V14 0
V15 0
V16 0
V17 0
V18 0
V19 0
V20 0
V21 0
V22 0
V23 0
V24 0
V25 0
V26 0
V27 0
V28 0
Amount 0
Class 0
dtype: int64
Fraud
count 492.000000
mean 122.211321
std 256.683288
min 0.000000
25% 1.000000
50% 9.250000
75% 105.890000
max 2125.870000
Name: Amount, dtype: float64
Normal
count 284315.000000
mean 88.291022
std 250.105092
min 0.000000
25% 5.650000
50% 22.000000
75% 77.050000
max 25691.160000
Name: Amount, dtype: float64

Time V1 V2 ... Amount Class Amount_max_fraud
0 0.0 -1.359807 -0.072781 ... 149.62 0 0
1 0.0 1.191857 0.266151 ... 2.69 0 0
2 1.0 -1.358354 -1.340163 ... 378.66 0 0
3 1.0 -0.966272 -0.185226 ... 123.50 0 0
4 2.0 -1.158233 0.877737 ... 69.99 0 0
[5 rows x 32 columns]
C:/Users/ljy/Desktop/test.py:51: DeprecationWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
See the documentation here:
http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated
x_features= x.ix[:,x.columns != "Class"]
C:/Users/ljy/Desktop/test.py:52: DeprecationWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
See the documentation here:
http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated
x_labels=x.ix[:,x.columns=="Class"]
length of training data
199364
length of test data
85443
C:/Users/ljy/Desktop/test.py:99: UserWarning: The `nb_epoch` argument in `fit` has been renamed `epochs`.
0.970155542291
Epoch 1/500
- 420s - loss: 0.0115 - acc: 0.9963
Epoch 2/500
- 415s - loss: 0.0038 - acc: 0.9991
Epoch 3/500
- 408s - loss: 0.0034 - acc: 0.9993
Epoch 4/500
- 408s - loss: 0.0032 - acc: 0.9993
Epoch 5/500
- 417s - loss: 0.0032 - acc: 0.9994
Epoch 6/500
ERROR: execution aborted