Keepalived+Master-Master-Slave组合
master1和master2公用一个VIP。当某个master宕机后,keepalived能自动将VIP漂移到另一个master上。只需要1~3秒即可切换完成,基本能保证服务不中断。
实验环境:
CentOS6.7X86_64
MariaDB10.0.17
Keepalived1.2.21
各节点配置:
Master1:192.168.2.13
Master2:192.168.2.14
VIP:192.168.2.100
Slave:192.168.2.11
Web服务器:192.168.2.11
主要步骤如下:
构建MySQL双主---> 配置Keepalived ---> 模拟节点故障 ---> MHA基础上构建web站点 ---> MHA基础上添加Slave
一、构建双主MySQL
安装MariaDB过程略过,可以直接使用通用二进制包进行安装。
首先确保2台Master是新安装的(不是新安装的话,执行mysql_install_db重新初始化即可),配置起来更方便些。
配置Master1,修改my.cnf,如下:
[mysqld]
....主要修改如下:....
innodb_file_per_table =ON
skip_name_resolve = ON
log-bin=mysql-bin
binlog_format=mixed
server-id=1
log_slave_updates=ON
auto-increment-offset = 1
auto-increment-increment = 2
replicate-ignore-db = test
replicate-ignore-db = mysql
配置Master2,修改my.cnf,如下:
[mysqld]
....主要修改如下:....
innodb_file_per_table =ON
skip_name_resolve = ON
log-bin=mysql-bin
binlog_format=mixed
server-id=2
log_slave_updates=ON
auto-increment-offset = 2
auto-increment-increment = 2
replicate-ignore-db = test
replicate-ignore-db = mysql
在Master1上建立授权用户
> grant replication slave on *.* to 'repluser'@'192.168.2.%' identified by '123456';
> flush privileges;
> show master status;

在Master2上连接到Master1作为自己的主服务器
> change master to master_host='192.168.2.13',
master_user='repluser',
master_password='123456',
master_log_file='mysql-bin.000003',
master_log_pos=22519;
> start slave;
> show slave status\G

在Master2上建立授权用户
> grant replication slave on *.* to 'repluser'@'192.168.2.%' identified by '123456';
> flush privileges;
> show master status;
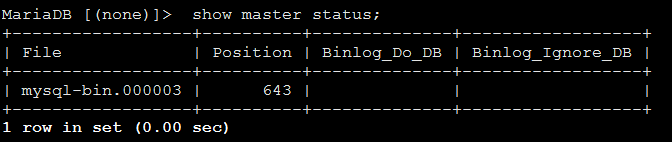
在Master1上连接到Master2作为自己的主服务器
> change master to master_host='192.168.2.14',
master_user='repluser',
master_password='123456',
master_log_file='mysql-bin.000003',
master_log_pos=643;
> start slave;
> show slave status\G
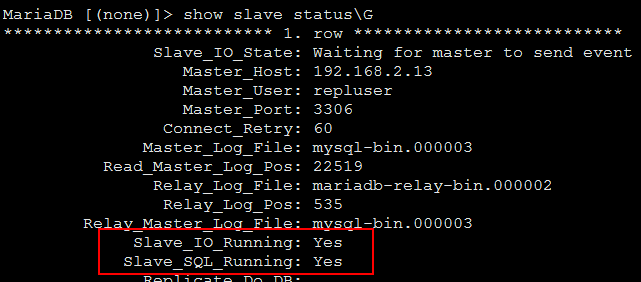
二、安装配置keepalived
编译安装keepalived
在2个节点都如下操作:
tar xf keepalived-1.2.21.tar.gz
cd keepalived-1.2.21
./configure
make && make install
cp /usr/local/etc/rc.d/init.d/keepalived /etc/rc.d/init.d
cp /usr/local/etc/sysconfig/keepalived /etc/sysconfig/
mkdir /etc/keepalived
cp /usr/local/etc/keepalived/keepalived.conf /etc/keepalived
cp /usr/local/sbin/keepalived /usr/sbin/
chkconfig --add keepalived
chkconfig keepalived on
在master1(192.168.2.13)上,修改keepalived的配置文件,如下:
! Configuration File forkeepalived
global_defs {
notification_email {
}
notification_email_from localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MySQL_HA
}
vrrp_instance VI_1 {
state BACKUP # 两台配置此处均是BACKUP
interface eth0 # 网卡,可使用ifconfig查看
virtual_router_id 51
priority 100 # 优先级,另一台改为90,默认VIP飘在在这个节点上
advert_int 1
nopreempt # 不抢占,只在优先级高的机器上设置即可,优先级低的机器不设置
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.2.100 dev eth0 label eth0:1
}
}
virtual_server 192.168.2.100 3306{
delay_loop 2 # 每个2秒检查一次real_server状态
lb_algo rr # 轮询算法
lb_kind DR # LVS算法,直接转发
persistence_timeout 50 # 会话保持时间
protocol TCP
real_server 192.168.2.13 3306 { # 只配置一个real_server,且为本机地址
weight 3
notify_down/home/scripts/MySQL.sh # 检测到服务down后执行的脚本
TCP_CHECK{
connect_timeout10 # 连接超时时间
nb_get_retry 3 # 重连次数
delay_before_retry 3 # 重连间隔时间
connect_port 3306 # 健康检查端口
}
}
}
在master2(192.168.2.14)上,修改keepalived的配置文件,如下:
! Configuration File forkeepalived
global_defs {
notification_email {
}
notification_email_from localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MySQL_HA
}
vrrp_instance VI_1 {
state BACKUP # 两台配置此处均是BACKUP
interface eth0 # 网卡,可使用ifconfig查看
virtual_router_id 51
priority 90 # 优先级,master2这台改为90,当master1无响应,则VIP会飘到这个节点上
advert_int 1
#nopreempt # 不抢占,只在优先级高的机器上设置即可,优先级低的机器设不设置都无所谓
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.2.100 dev eth0 label eth0:1
}
}
virtual_server 192.168.2.100 3306{
delay_loop 2 # 每个2秒检查一次real_server状态
lb_algo rr # 轮询算法
lb_kind DR # LVS算法,直接转发
persistence_timeout 50 # 会话保持时间
protocol TCP
real_server 192.168.2.14 3306 { # 只配置一个real_server,且为本机地址
weight 3
notify_down/home/scripts/MySQL.sh # 检测到服务down后执行的脚本
TCP_CHECK{
connect_timeout10 # 连接超时时间
nb_get_retry 3 # 重连次数
delay_before_retry 3 # 重连间隔时间
connect_port 3306 # 健康检查端口
}
}
}
编写检测服务down后所要执行的脚本
在master1和master2都执行下面的操作:
mkdir /home/scripts/
vim /home/scripts/MySQL.sh 内容如下:
#!/bin/sh
pkill keepalived
注意:
此脚本是上面配置文件notify_down选项所用到的,
keepalived使用notify_down选项来检查real_server的服务状态,当发现real_server服务故障
时,便触发此脚本;我们可以看到,脚本就一个命令,通过pkill keepalived强制杀死
keepalived进程,从而实现了MySQL故障自动转移。
另外,我们不用担心两个MySQL会同时提供数据更新操作,因为每台MySQL上的keepalived的配置里面只有本机MySQL的IP+VIP,而不是两台MySQL的IP+VIP。
在master1和master2上都启动keepalived
/etc/init.d/keepalived start
ps aux|grep keepalived
ifconfig -a
可以看到VIP默认是在master1上的(因为keepalived里配置master1的优先级为100,master2的优先级为90)
三、模拟节点故障
模拟MySQLMaster的写节点故障
我们可以模拟下master的MySQL无法访问了,看看VIP会不会自动漂移。
先查看master1、master2的IP情况,如下图:
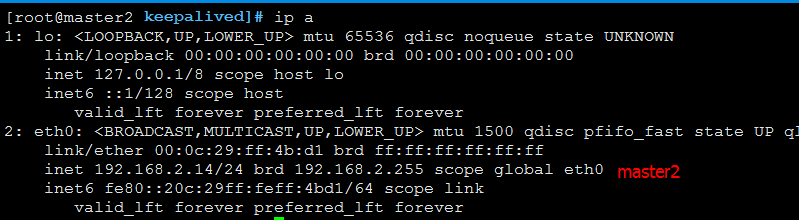
可以看到VIP在master1节点上。我们在master1上执行/etc/init.d/mariadb stop 模拟master1的MySQL进程挂掉的情况。
然后,在maste1和master2上执行
ps aux|egrep "keepalived|mariadb"
ip a
可以看到VIP已经漂移到master2上了。此时,master1上的MariaDB进程挂掉后,keepalived进程也一并被kill了。
至此,实验初步算是完成了。但是这个方案的话,mysql一退出, keepalived也退出了,后面再次修复的话要手动启动keepalived进程,不然就达不到高可用的效果了。不过出于数据安全性、完整性考虑,MySQL和keepalived进程还是应该手动恢复的。
这个方案还有个不足,就是mysql端口和进程都在,但是复制线程却不是Yes状态了,这种只能靠zabbix
或者其它监控工具来监控了。
四、在MHA的基础上构建个web站点
MySQL高可用实现后,不如继续深入下,再基于上面的环境构建个web站点吧,操作如下:
web节点参数:
IP:192.168.2.11
运行有:Nginx+php-fpm
nginx虚拟主机配置如下:
server {
listen 80;
server_name 192.168.2.11;
location / {
root /home/wwwroot/default;
index index.php index.html index.htm;
}
location ~ \.php$ {
root /home/wwwroot/default;
fastcgi_pass unix:/tmp/php-cgi.sock;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
access_log /home/wwwlogs/access.log main;
}
}
/etc/init.d/nginx start 启动nginx服务
/etc/init.d/php-fpm start 启动php-fpm服务
在master1或者master2上执行下面命令,创建个web网站所需的数据库:
> create database metinfo;
> grant all on metinfo.* to'met'@'192.168.2.%' identified by '123456';
> flush privileges;
在浏览器访问http://192.168.2.11 如下图:
注意数据库主机地址要填:192.168.2.100
五、在MHA的基础上添加一个Slave
生产环境中,光靠2个Master是顶不住那么大压力的,因此还需要添加几个Slave节点(假设节点IP 192.168.2.11)。
修改Slave的my.cnf 如下
[mysqld]
....主要修改如下:....
innodb_file_per_table =ON
skip_name_resolve = ON
log-bin=mysql-bin
binlog_format=mixed
server-id = 10
relay_log =mysql-relay.bin
log_slave_updates = 1
read_only = 1
replicate-ignore-db = test
replicate-ignore-db = mysql
在业务低谷时候,先将keepalived进程停掉,防止写入数据。
然后稍等片刻,等2个master之间的数据同步后,在任意master上执行:
> flush tables with read lock;
# mysqldump -uroot -proot -A >all.sql
# scp [email protected]:/root/
在干净的slave上启动MariaDB,并导入all.sql
# mysql -uroot -proot -e 'sourceall.sql;'
导入后,在刚才锁表的master上解除锁
> unlock tables;
操作完成后,在master1和master2上启动keepalived进程,让VIP再次出现。
VIP出现后,然后,在slave上执行:
> change master to master_host='192.168.2.100',
master_user='repluser',
master_password='123456',
master_log_file='mysql-bin.000006',
master_log_pos=326;
> start slave; 启动复制
> show slave status\G
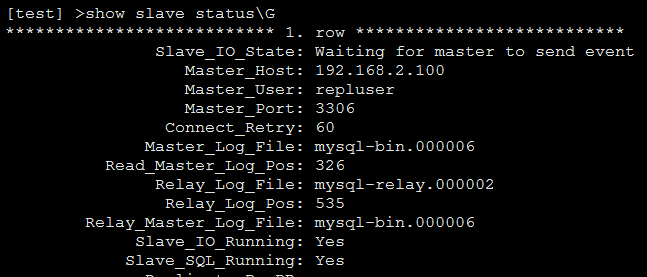
这时候,我们可以在master1或者master2上任意创建库、表、插入数据,然后在slave上都可以看到数据已经正常同步过来了。
脚本change_master.sh内容如下:
#!/bin/bash
# 下面的是Master的虚拟IP,还有授权的账号和密码
VIP="192.168.2.100"
user="root"
passwd="123456"
# 复制账号和密码
repluser="repluser"
replpasswd="123456"
# 本地MySQL管理账号等
host="192.168.2.11"
man_user="root"
man_pass="123456"
# 查看Master的二进制日志信息
FILE=$(/usr/local/mariadb/bin/mysql -u$user -p$passwd -h $VIP -e 'show master status;'|sed -n '2p'|awk '{print$1}')
POS=$(/usr/local/mariadb/bin/mysql -u$user -p$passwd -h $VIP -e 'show masterstatus;'|sed -n '2p'|awk '{print $2}')
# 将本机修改成Slave状态
mysql -u$man_user -p$man_pass -h$host -e "stop slave;"
mysql -u$man_user -p$man_pass -h$host -e "reset slave all;"
mysql -u$man_user -p$man_pass -h$host -e "change master to master_user='${repluser}',master_host='${VIP}',master_password='${replpasswd}',master_log_file='${FILE}',master_log_pos=${POS};"
mysql -u$man_user -p$man_pass -h$host -e "start slave;"
# 输出执行结果
REPL_STATUS=$(mysql -e 'show slave status\G'|sed -n '12,13p'|grep-c "Yes")
if [[ $REPL_STATUS != 2 ]];then
echo-e "\033[31mChange Status to Slave,Failed!\033[0m"
else
echo-e "\033[32mChange Status to Slave,Success!\033[0m"
fi
脚本monitor_slave.sh内容如下:
#!/bin/bash
# Description: 每2秒钟检测从节点的状态,如果状态不是2个Yes,则执行上面的change_master.sh脚本
while true;do
{
if[[ `mysql -uroot -e 'show slave status\G'|grep -c "Yes"` != 2 ]] ;then
echo-e "\033[30mwill auto change slave status $(date "+%F %T")\033[0m" >> /tmp/slave.log
/bin/bash change_master.sh
else
echo-e "\033[32mHealth Status: OK $(date "+%F %T")\033[0m" >> /tmp/slave.log
fi
}
sleep 2
done
nohup sh monitor_slave.sh &
将监控进程运行在后台,不断监控slave的同步状态,如果发现同步线程不是2个Yes,则自动执行change_master.sh,重新配置主从关系。
假设我们还有一个配置好的slave,IP为192.168.2.15。那么现在的情况是:
Master1:192.168.2.13
Master2:192.168.2.14
VIP:192.168.2.100
Slave1:192.168.2.12
Slave2:192.168.2.15
Web服务器:192.168.2.11
haproxy的安装配置
演示用法而已,我们就将haproxy安装到192.168.2.12上,能验证效果即可。
软件版本:
haproxy-1.5.4-2 【haproxy1.6配置文件和以往的有点不一样,这里没有用最新的】
yum install haproxy -y
cd /etc/haproxy
vim haproxy.cfg 修改配置文件,修改好的配置文件如下:
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode tcp
log global
option dontlognull
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
## 定义一个监控页面,监听在1080端口,并启用了验证机制
listen stats
mode http
bind 0.0.0.0:1080
stats enable
stats hide-version
stats uri /haproxy
stats realm Haproxy\ Statistics
stats auth admin:123456
stats admin if TRUE
listen mysql
bind 0.0.0.0:3336
mode tcp
option mysql-check user haproxy_check # 定义了一个用于后端的mysql健康检查的用户[主要:这个用户要在后端的slave上存在才行]
balance roundrobin
server slave1 192.168.2.12:3306 weight 1check inter 1s rise 2 fall 2
server slave2 192.168.2.15:3306 weight 1check inter 1s rise 2 fall 2
在各个mysqlslave节点上创建账号
创建允许haproxy连接到数据库的账号获取其运行状态
> GRANT PROCESS ON *.* TO'haproxy_check'@'192.168.2.%';
> flush privileges;
再创建一个访问的账号,一会要通过它连接haproxy的3336节点尝试访问slave,以便验证是否能负载均衡
> GRANT ALL ON *.* TO'lirl'@'192.168.2.%' identified by '123456';
> flush privileges;
启动haproxy
/etc/init.d/haproxy start
浏览器访问http://192.168.2.12:1080/haproxy
输入用户名admin 密码123456 进到下面的界面:
一、环境说明
1、操作系统内核版本:2.6.9-78.ELsmp
2、Keepalived软件版本:keepalived-1.1.20.tar.gz
二、环境配置
1、主Keepalived服务器IP地址 192.168.111.223
2、备Keepalived服务器IP地址 192.168.111.100
3、Keepalived虚拟IP地址 192.168.111.150
三、软件下载地址
http://www.keepalived.org/software/keepalived-1.1.20.tar.gz
四、安装流程
1、上传Keepalived至/home/目录
2、解压Keepalived软件
[root@localhost home]# tar -zxvf keepalived-1.1.20.tar.gz
[root@localhost home]# cd keepalived-1.1.20
[root@localhost keepalived-1.1.20]# ln -s /usr/src/kernels/2.6.9-78.EL-i686/usr/src//linux
[root@localhost keepalived-1.1.20]# ./configure
遇到错误提示:configure: error: Popt libraries is required
这个错误是因为没有安装popt的开发包导致的,解决方法也很简单,只要yum install popt-devel 就可以安装好popt的开发包了。
重新./configure
没有遇到跳过这一步
3、提示
4、编译以及编译安装
[root@localhost keepalived-1.1.20]# make && make install
5、将types.h调用的部分注释掉即可解决4出现的问题
vi/usr/src/kernels/2.6.9-78.EL-i686/include/linux/types.h
到158行操作如下
#endif
6、重新编译以及编译安装
[root@localhost keepalived-1.1.20]# make && make install
7、修改配置文件路径
[[email protected]]#cp/usr/local/etc/rc.d/init.d/keepalived/etc/rc.d/init.d/
[[email protected]]# cp /usr/local/etc/sysconfig/keepalived /etc/sysconfig/
[root@localhost keepalived-1.1.20]# mkdir /etc/keepalived
[[email protected]]#cp /usr/local/etc/keepalived/keepalived.conf/etc/keepalived/
[root@localhost keepalived-1.1.20]# cp /usr/local/sbin/keepalived /usr/sbin/
8、设置为服务,开机启动
[root@localhost keepalived-1.1.20]# vi /etc/rc.local
五、主Keepalived配置
1、修改配置文件
[root@localhost keepalived-1.1.20]# vi /etc/keepalived/keepalived.conf
六、备Keepalived配置
1、修改配置文件
七、启动服务
八、查看网卡信息
1、主Keepalived网卡信息
九、验证测试
1、在主服务器上新建一个网页,内容为 192.168.111.223
2、在备用服务器上新建一个网页,内容为 192.168.111.100
3、启动主备服务器的http服务和Keepalived服务
4、通过浏览数,输入虚拟IP地址 192.168.111.150
页面显示为 192.168.111.223
5、关闭主服务器的Keepalived服务,通过浏览器输入IP地址192.168.111.150
页面显示为 192.168.111.100
6、再次启动主服务器的Keepalived服务,通过浏览器输入IP地址192.168.111.150
页面显示为 192.168.111.223