决策树(ID3、C4.5、CART)
决策树的思路:
首先决策树是由结点和有向边组成的。
结点分为:内部结点和叶结点。
每个内部结点对应一个特征,每个叶结点对应就是:分类--》一个类;回归--》一个值。
决策树,从根结点开始,进行一个if-then判断。
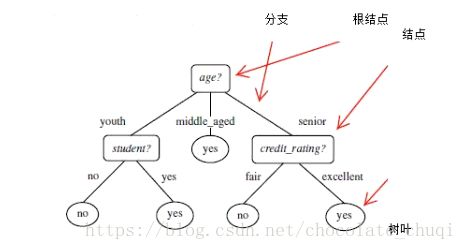
因为根据给定的训练集可以训练出很多个不同的决策树,因此从很多决策树中选出最优是一个NP-HARD问题。决策树学习是一个递归过程,选取一个次优解。
我们希望最后叶结点尽可能在同一类,那就是纯度希望高一点。
问题一:如何据点每一个结点为什么特征?就像上图为什么是age作为根结点而不是student之类的。
这里我们要引入信息熵这个知识点。在信号编码的时候学过,引入信息熵来描述心愿的不确定度。
信息熵: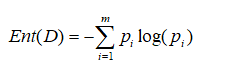
Ent(D)值越小,D的纯度越高。其中pi为该类别样本占比。
那么怎样选取特征呢?我们需要涉及到信息增益。
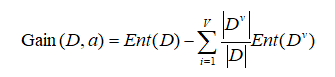
Dv是我接下来用的特征有V个选择,例如age有youth,middle_aged,senior三个选择,V为3.Dv为这个类别的样本数。信息增益就变成了当我加了这个特征以后,我的信息熵减少了多少。不确定信息减少得越多,那得到的信息就越大,所以我们选择一个信息增益最大的,作为结点。
跟着这种方法不断递归判断下去,就会得到我们想要的决策树。
到什么时候结束?两种情况:1.当前结点包含的样本全部都是同一类。2.信息增益小于阈值。
以上就是ID3,注意ID3不能处理连续值。
问题二:为什么ID3已经可以解决问题,还要引出C4.5?
正常我们的数据都会有一个index,可能是user_id、id之类的,如果我们用它作为一个属性,那信息增益就非常好看了。毕竟把样本安装index分,每个分支就只有一个样本。但是问题是木有泛化能力,对测试集毫无预测能力。当然,现实生活中不会有人傻得这么可爱。但是事实证明,信息增益准则会对可取值数目较多的属性有所偏好。
怎样解决?那就对取值数目多的属性进行一定的惩罚。
首先再次引入一个新知识:
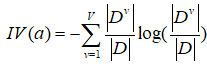 这个加做特征的固定值,取值数目越大IV(a)越大。
这个加做特征的固定值,取值数目越大IV(a)越大。
因此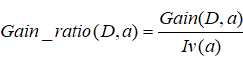
但是坑爹的是,C4.5又会引入一个新问题,就是对取值数目少的有偏向。
所以通常会,先选取信息增益高于平均水平的特征以后,再从中选取增益率高的。
问题三:决策树可不可以做回归?
CART,分类回归树。
先说它的分类。它有一个跟ID3和C4.5不同的是:分类回归是一颗二叉树,每个非叶子结点的结点都有两个子结点。
大家都说CART算法由两步组成:决策树生成和剪枝。
插播一个知识:GINI不纯度
 (一个随机事件变成他的对立事件的概率,所以越低越好)
(一个随机事件变成他的对立事件的概率,所以越低越好)
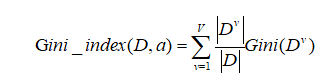
就是看每一个特征,是它和不是它分别的gini算出来,然后合起来计算GINI_INDEX然后找出最小的作为最优的划分点。
但是问题来了:这样不断划分会不会出现过拟合,因为分支过多,这样会把训练及自身的一些特点当做所有数据都有的一般特性。
所以引入了剪枝。剪枝有分预剪枝和后剪枝。
预剪枝
在决策树生成的时候,对每个结点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能力提升,就停止。怎样去判断泛化能力有没有提升。例如:划分前准确率42.9%,划分后准确率71.4%,那接受这个结点。如果划分前71.4%,划分后小于等于71.4%那就不要,禁止划分。
优点:降低了过拟合的风险,减少了训练的时间和测试时间的开销。
缺点:预剪枝有可能会使很多分支没有展开,有一些可能在当前分支不能带来效应,但是在这个分支基础上进行后续划分会带来一定提升。所以可能会带来欠拟合。
后剪枝
后剪枝就相反了。先训练出一个完整的局册数。然后从底部开始。从叶子点对应的结点,判断这个结点没有被剪的时候准确率是多少?剪掉后准确多少?如果剪后有所提升那么久剪掉。
优点:能够在防止过拟合的同时也降低了欠拟合的可能性。
缺点:但是因为后剪枝是在完成整个决策树以后开始的,并且从底层开始慢慢往上剪,所以花费的时间会比预剪枝大。
回归树
这个刚开始的时候我并木有看懂。
第一步,我们会根据连续变量,划分点。例如:2,4,6,8,10.我们会划分出3,5,7,9这四个切分点。然后例如5这个切分点,{2,4}是一个分类为R1,{6,8,10}为一个分类是R2。其实也就是把输入空间划分单元,然后每一个单元都会有他自己对应的固定输出值--他们这个单元的平均值。如果x=2,y=4;x=4,y=8;x=6,y=12;x=8,y=16;x=10,y=20;那么C1=6,C2=16.

然后我们找到这个特征里面平方误差最小的那个作为划分点。
其实就是
![]()
找出最优的切分变量j,最优的切分点s。
然后我们可以得到

然后用残差得到新的x,y对应值。就是例如上列就会变成
X=2,y=-2;x=4,y=2......然后重复。
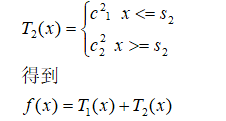
如此类推。直到满足误差要求。
以上也是介绍了怎样对连续值进行选取划分点。
三者比较
|
|
支持 |
|
特征类型 |
缺失值 |
过拟合 |
| ID3 |
分类 |
信息增益 |
离散值 |
无法处理 |
无法处理 |
| C4.5 |
分类 |
信息增益率 |
离散值、连续值 |
可以处理 |
预剪枝、后剪枝 |
| CART |
分类(二叉树)、回归 |
Gini指数、均方差 |
离散值、连续值 |
可以处理 |
预剪枝、后剪枝 |
| 不过他们都存在一个问题就是,都是以单个特征进行划分的。有时候如果是按着一个特征线性组合来进行划分说不定会更好。这个叫做多变量决策树。 还有就是引出随机森林的原因:如果样本有一点点改变,树结构可能会发生比较大的变化。 |
|||||
对于决策树的总结:http://www.cnblogs.com/pinard/p/6053344.html这位大神总结得很到位
首先我们看看决策树算法的优点:
1)简单直观,生成的决策树很直观。
2)基本不需要预处理,不需要提前归一化,处理缺失值。
3)使用决策树预测的代价是O(log2m)O(log2m)。 m为样本数。
4)既可以处理离散值也可以处理连续值。很多算法只是专注于离散值或者连续值。
5)可以处理多维度输出的分类问题。
6)相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
7)可以交叉验证的剪枝来选择模型,从而提高泛化能力。
8) 对于异常点的容错能力好,健壮性高。
我们再看看决策树算法的缺点:
1)决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
2)决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。
3)寻找最优的决策树是一个NP难的问题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
4)有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决。
5)如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
接下来还会总结:决策树的剪枝、决策树的源码、缺失值处理会放在一个大板块进行总结。