import pandas as pd
from matplotlib import pyplot as plt
fec = pd.read_csv('D:\python program\pydata-book-2nd-edition\datasets\\fec\P00000001-ALL.csv')
'''
获取全部候选人名单
unique_cands = fec.cand_nm.unique()
'''
#利用字典添加党派关系
parties = {
'Bachmann, Michelle':'Republican',
'Romney, Mitt':'Republican',
'Obama, Barack':'Democrat',
"Roemer, Charles E. 'Buddy' III":'Republican',
'Pawlenty, Timothy' : 'Republican',
'Johnson, Gary Earl' : 'Republican',
'Paul, Ron' : 'Republican',
'Santorum, Rick' : 'Republican',
'Cain, Herman' : 'Republican',
'Gingrich, Newt' : 'Republican',
'McCotter, Thaddeus G' : 'Republican',
'Huntsman, Jon' : 'Republican',
'Perry, Rick' : 'Republican'
}
#将党派添加为一个新列
fec['party'] = fec.cand_nm.map(parties)#名字映射党派
#只显示赞助的及出资额为正的数据
fec = fec[fec.contb_receipt_amt > 0]
#只包含重要信息的子集,即obama和romney的竞选信息
fec_sub = fec[fec.cand_nm.isin(['Obama, Barack','Romney, Mitt'])]
'''根据职业和雇主统计赞助信息。基于职业的赞助信息统计'''
'''
获取赞助的职业及数量
fec.contbr_occupation.value_counts()
'''
#许多职业涉及相同的基本工作类型,清理数据
occ_mapping = {
'INFORMATION REQUESTED' : 'NOT PROVIDED',
'INFORMATION REQUESTED PER BEST EFFORTS' : 'NOT PROVIDED',
'INFORMATION REQUESTED (BEST EFFORTS)' : 'NOT PROVIDED',
'C.E.O.' : 'CEO'
}
#dict.get允许没有映射关系的也能通过,如果没有提供相关映射,则返回x
f = lambda x: occ_mapping.get(x,x)
fec.contbr_occupation = fec.contbr_occupation.map(f)
#同理清理雇主数据
emp_mapping = {
'INFORMATION REQUESTED PER BEST EFFORTS' : 'NOT PROVIDED',
'INFORMATION REQUESTED' : 'NOT PROVIDED',
'SELF' : 'SELF-EMPLOYED',
'SELF EMPLOYED' : 'SELF-EMPLOYED'
}
f = lambda x: emp_mapping.get(x,x)
fec.contbr_employer = fec.contbr_employer.map(f)
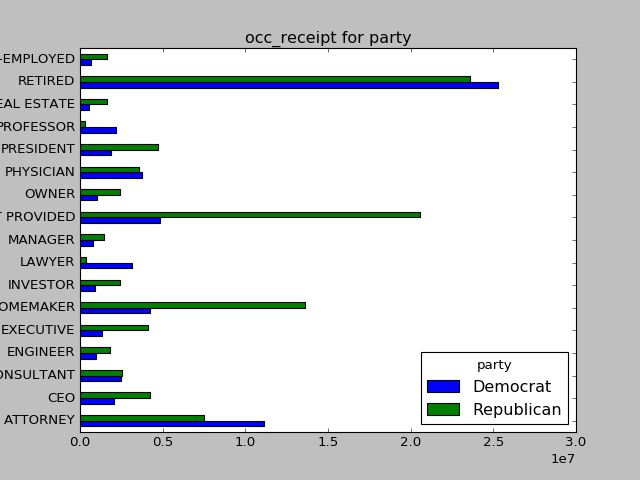
#根据党派和职业对数据进行聚合
by_occupation = fec.pivot_table('contb_receipt_amt',index='contbr_occupation',columns='party',aggfunc='sum')
#过滤掉总出资额低于200万美元的数据
over_2mm = by_occupation[by_occupation.sum(1) > 2000000]
#柱状图
over_2mm.plot(kind='barh',title='occ_receipt for party')
plt.show()
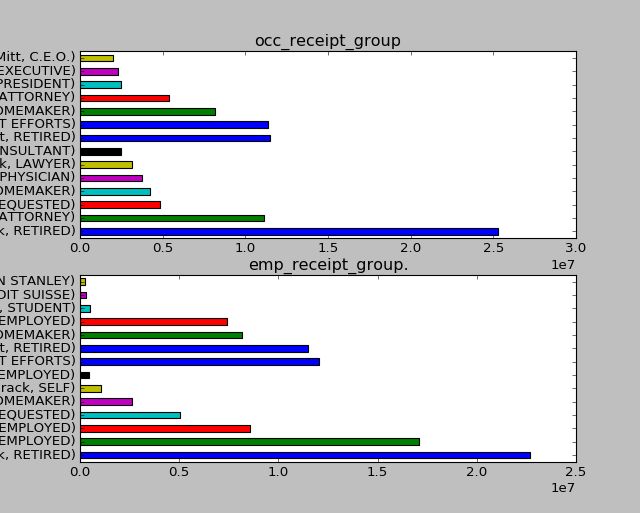
'''分析对Obama和Romney总出资额最高的职业和企业'''
#求取最大值
def get_top_amounts(group,key,n=5):
totals = group.groupby(key)['contb_receipt_amt'].sum()
#根据key对totals降序
return totals.sort_values(ascending=False)[:n]
#根据雇主和职业聚合
grouped = fec_sub.groupby('cand_nm')
#职业,前7个
occ_receipt_group = grouped.apply(get_top_amounts,'contbr_occupation',n=7)
#雇主,前7个
emp_receipt_group = grouped.apply(get_top_amounts,'contbr_employer',n=7)
#画图
fig,axes = plt.subplots(2,1)
occ_receipt_group.plot(kind='barh',ax=axes[0],title='occ_receipt_group')
emp_receipt_group.plot(kind='barh',ax=axes[1],title='emp_receipt_group.')
plt.show()
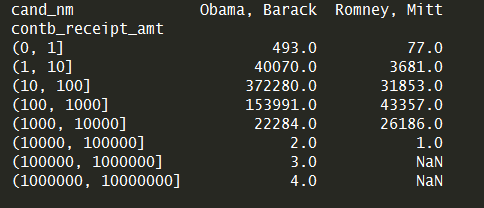
'''对出资额分组
分析两位候选人各种赞助额的比例
'''
#
利用
cut
函数根据出资额的大小将数据离散化到多个面元中bins
= np.array([
0
,
1
,
10
,
100
,
1000
,
10000
,
100000
,
1000000
,
10000000])labels
= pd.cut(fec_sub.contb_receipt_amt
,bins)
#
面元标签
#
根据候选人和面元标签对数据分组grouped
= fec_sub.groupby([
'cand_nm'
,labels])
print(grouped.size().unstack(
0))
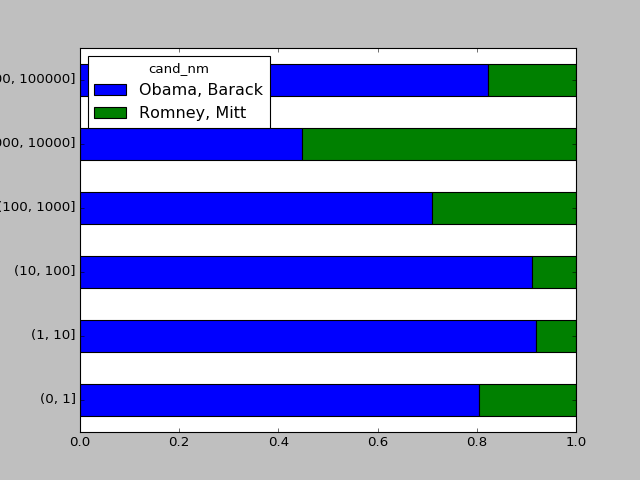
#对出资额求和,并在面元内规格化
bucket_sums = grouped.contb_receipt_amt.sum().unstack(0)
#print(bucket_sums)
#将得到的数据按比例
normed_sums = bucket_sums.div(bucket_sums.sum(axis=1),axis=0)
#print(normed_sums)
#排除两个最大的
normed_sums[:-2].plot(kind='barh',stacked=True)
plt.show()
'''根据州统计赞助信息'''
#根据候选人和州对数据聚合
grouped = fec_sub.groupby(['cand_nm','contbr_st'])
totals = grouped.contb_receipt_amt.sum().unstack(0).fillna(0)
totals = totals[totals.sum(1) > 100000]
#print(totals)
#各行除以总赞助额,得到各候选人在各州的总赞助额比例
percent = totals.div(totals.sum(1),axis=0) #跟sum(axis=1)一样
print(percent)
