全分布 Hadoop 3.2 HA 集群 安装 搭建
1,机器情况确认,安装前暂时把所有机器的防火墙关闭
# 机器情况
# Namenode/resourcemanager,这 3 台 namenode/resourcemanager 之间能够进行 故障切换
192.168.1.110 nn110
192.168.1.111 nn111
192.168.1.120 nn120
# worker/slave
192.168.1.121 worker121 # 同时在上面安装了zookeeper
192.168.1.122 worker122 # 同时在上面安装了zookeeper
192.168.1.123 worker123 # 同时在上面安装了zookeeper2,机器间配置免密,同时配置 /etc/hosts
不赘述,网上很多教程
3,安装Java 8 ,配置环境变量
不赘述
4,Zookeeper部分
-
第一步, 下载zookeeper 安装包。
-
第二步" 解压包
-
第三步:配置conf目录下的zoo.cfg 文件,如果没有这个文件,直接添加,或者把zoo.cfg.template重命名为zoo.cfg,具体配置如下:
-
最后:把这个配好的 zookeeper 拷贝到其他 2 台机器,不要忘记建对应的数据存放目录,然后在目录中建一个名为“myid”的文件,文件写入zoo.cfg中配置的服务id,例如下面的 zoo.cfg 配置,则对应 id 分别为 121、122、123
-
启动: bin/zkServer.sh start ,分别启动这 3 台服务器上的zookeeper。
# =========================================== zoo.cfg 配置开始 ========================
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# 这里配置 zookepper 数据存放目录路径,请提前建好目录
dataDir=/home/chudu/zoo
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
# autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
# autopurge.purgeInterval=1
server.121=192.168.1.121:2888:3888
server.122=192.168.1.122:2888:3888
server.123=192.168.1.123:2888:3888
5,下载并解压 hadoop 包,本博客测试下载的是 3.2 版本
6,配置文件
fs.defaultFS
hdfs://cluster
dfs.nameservices
cluster
hadoop.tmp.dir
/home/chudu/hdfs
ha.zookeeper.quorum
worker121:2181,worker122:2181,worker123:2181
ha.zookeeper.session-timeout.ms
3000
dfs.nameservices
cluster
dfs.namenode.name.dir
/home/chudu/hdfs/name
dfs.datanode.data.dir
/home/chudu/hdfs/data
dfs.permissions.enabled
false
dfs.ha.namenodes.cluster
nn110,nn111,nn120
dfs.namenode.rpc-address.cluster.nn110
nn110:9820
dfs.namenode.rpc-address.cluster.nn111
nn111:9820
dfs.namenode.rpc-address.cluster.nn120
nn120:9820
dfs.namenode.http-address.cluster.nn110
nn110:9870
dfs.namenode.http-address.cluster.nn111
nn111:9870
dfs.namenode.http-address.cluster.nn120
nn120:9870
dfs.ha.automatic-failover.enabled
true
dfs.namenode.shared.edits.dir
qjournal://nn110:8485;nn111:8485;nn120:8485/cluster
dfs.journalnode.edits.dir
/home/chudu/hdfs/journal
dfs.client.failover.proxy.provider.cluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/chudu/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
10000
dfs.namenode.handler.count
100
dfs.replication
2
dfs.datanode.hostname
nn110
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yarn-cluster
yarn.resourcemanager.ha.rm-ids
yn110,yn111,yn120
yarn.resourcemanager.ha.id
yn110
yarn.resourcemanager.zk-address
worker121:2181,worker122:2181,worker123:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.connect.retry-interval.ms
2000
yarn.client.failover-proxy-provider
org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider
yarn.resourcemanager.scheduler.class org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms
5000
yarn.resourcemanager.address.yn110
nn110:8032
yarn.resourcemanager.webapp.address.yn110
nn110:8088
yarn.resourcemanager.scheduler.address.yn110
nn110:8030
yarn.resourcemanager.resource-tracker.address.yn110
nn110:8031
yarn.resourcemanager.admin.address.yn110
nn110:8033
yarn.resourcemanager.ha.admin.address.yn110
nn110:23142
yarn.resourcemanager.address.yn111
nn111:8032
yarn.resourcemanager.webapp.address.yn111
nn111:8088
yarn.resourcemanager.scheduler.address.yn111
nn111:8030
yarn.resourcemanager.resource-tracker.address.yn111
nn111:8031
yarn.resourcemanager.admin.address.yn111
nn111:8033
yarn.resourcemanager.ha.admin.address.yn111
nn111:23142
yarn.resourcemanager.address.yn120
nn120:8032
yarn.resourcemanager.webapp.address.yn120
nn120:8088
yarn.resourcemanager.scheduler.address.yn120
nn120:8030
yarn.resourcemanager.resource-tracker.address.yn120
nn120:8031
yarn.resourcemanager.admin.address.yn120
nn120:8033
yarn.resourcemanager.ha.admin.address.yn120
nn120:23142
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.local-dirs
/home/chudu/hdfs/nodemanager/local
yarn.nodemanager.remote-app-log-dir
/home/chudu/hdfs/nodemanager/remote-app-logs
yarn.nodemanager.log-dirs
/home/chudu/hdfs/nodemanager/logs
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
864000
yarn.log-aggregation.retain-check-interval-seconds
86400
mapreduce.framework.name
yarn
mapreduce.application.classpath
/home/chudu//hadoop-3.2.0/etc/hadoop,
/home/chudu//hadoop-3.2.0/share/hadoop/common/*,
/home/chudu//hadoop-3.2.0/share/hadoop/common/lib/*,
/home/chudu//hadoop-3.2.0/share/hadoop/hdfs/*,
/home/chudu//hadoop-3.2.0/share/hadoop/hdfs/lib/*,
/home/chudu//hadoop-3.2.0/share/hadoop/mapreduce/*,
/home/chudu//hadoop-3.2.0/share/hadoop/mapreduce/lib/*,
/home/chudu//hadoop-3.2.0/share/hadoop/yarn/*,
/home/chudu//hadoop-3.2.0/share/hadoop/yarn/lib/*
yarn.app.mapreduce.am.staging-dir
/home/chudu/hdfs/staging
mapreduce.jobhistory.address
nn110:10020
mapreduce.jobhistory.webapp.address
nn110:19888
mapreduce.jobhistory.joblist.cache.size
15000
# worker 文件配置,注意不是 slave 文件了
worker121
worker122
worker123
7, 配置好的Hadoop程序分发
将上面配置好的 hadoop 程序拷贝到其他机器,注意 hdfs-site.xml 需要修改 dfs.datanode.hostname,值推荐和hadoop机器的 hostname 一致,并且创建对应的目录(hadoop.tmp.dir配置的地址)
8,启动过程
# 先分别启动 3 台服务器上的 zookeeper
./zkServer.sh start
# 分别进入到 3 台 namenode 的 hadoop的安装目录下然后进到sbin 目录下
./hadoop-daemon.sh start journalnode
# 某一台 namenode 的服务器 上 格式化namenode
hadoop namenode -format
# 格式化后,同步内容到其他节点上(需要将 core-site.xml 文件中 hadoop.tmp.dir 指定的目录下 的 name 子目录 到 另外 2 台 namenode 机器的对应位置)
scp -r /home/chudu/hdfs/name nn111:~/hdfs/
scp -r /home/chudu/hdfs/name nn120:~/hdfs/
# 格式化zkfc
./hdfs zkfs -formatZK
# 启动 namenode
# 启动 resourcemanager
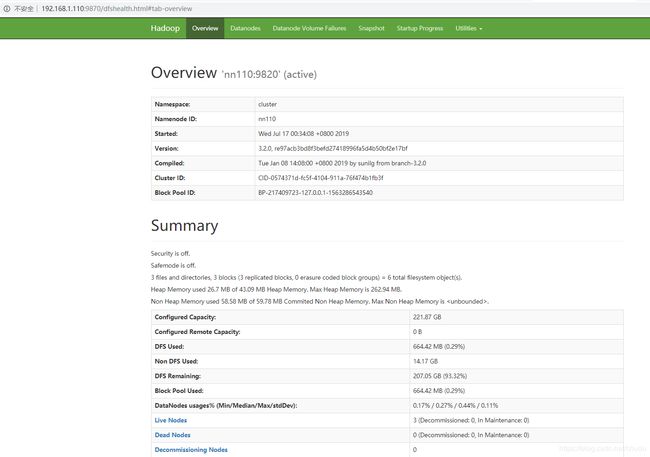
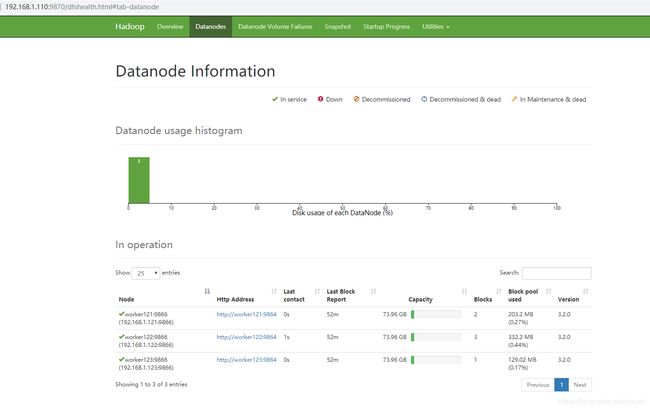
9, Web 访问