自旋锁&CLH锁&MCS锁学习记录

阅读原文请访问我的博客 BrightLoong's Blog
本篇文章主要记录自旋锁、CLH锁、MCS锁的学习所得。关于自旋锁和CLH锁、MCS锁,网上已经有很多内容,而且很类似;学习就是学习前人经验,理解、总结,化为己用,因此,虽然网上有很多相关的内容,我也是参考了这些内容,我依然选择记录下了自己的理解,方便自己查阅。
一. 自旋锁
自旋锁(SpinLock):多个线程,当一个线程尝试获取锁的时候,如果锁被占用,就在当前线程循环检查锁是否被释放,这个时候线程并没有进入休眠或者挂起。
代码实现
下面是自旋锁的简单实现:
package io.github.brightloong.concurrent.lock;
import java.util.concurrent.atomic.AtomicReference;
/**
* Created by BrightLoong on 2018/6/13.
* 自旋锁
*/
public class SpinLock {
//AtomicReference,CAS,compareAndSet保证了操作的原子性
private AtomicReference owner = new AtomicReference();
public void lock() {
Thread currentThread = Thread.currentThread();
// 如果锁未被占用,则设置当前线程为锁的拥有者,设置成功返回true,否则返回false
// null为期望值,currentThread为要设置的值,如果当前内存值和期望值null相等,替换为currentThread
while (!owner.compareAndSet(null, currentThread)) {
}
}
public void unlock() {
Thread currentThread = Thread.currentThread();
// 只有锁的拥有者才能释放锁,只有上锁的线程获取到的currentThread,才能和内存中的currentThread相等
owner.compareAndSet(currentThread, null);
}
}
- 使用AtomicReference保存当前获取到锁的线程,保证了compareAndSet操作的原子性,关于CAS请参考——Java中CAS学习记录
缺点
- 非公平锁,并不能保证线程获取锁的顺序。
- 保证各个CPU的缓存(L1、L2、L3、跨CPU Socket、主存)的数据一致性,通讯开销很大,在多处理器系统上更严重。
- 没法保证公平性,不保证等待进程/线程按照FIFO顺序获得锁。
二. CLH锁
CLH锁:Craig, Landin, and Hagersten (好吧,这是三个人的名字),它是基于链表实现的自旋锁,它不断的轮询前驱的状态,如果前驱释放锁,它就结束自旋转。
实现
CLH锁实现如下:
- 线程持有自己的node变量,node中有一个locked属性,true代表需要锁,false代表不需要锁。
- 线程持有前驱的node引用,轮询前驱node的locked属性,true的时候自旋,false的时候代表前驱释放了锁,结束自旋。
- tail始终指向最后加入的线程。
运行原理
其运行用下图做一个说明:
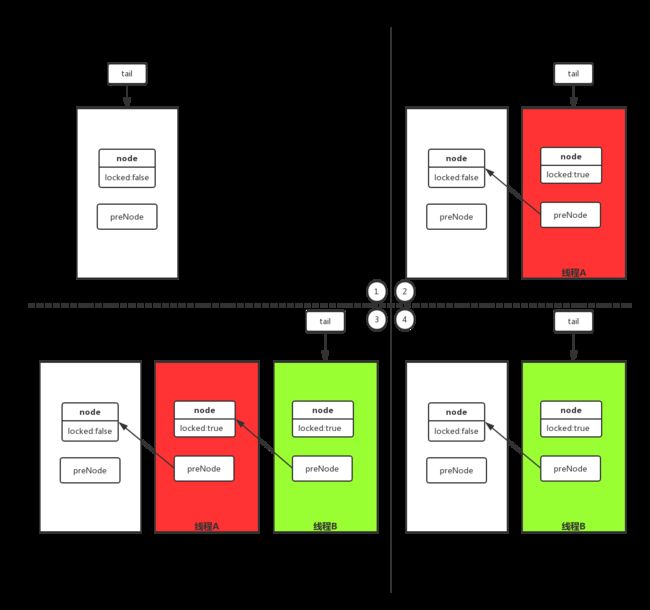
- 初始化的时候tail指向一个类似head的节点,此时node的locked属性为false,preNode为空。
- 当线程A进来的时候,线程A持有的node节点,node的locked属性为true,preNode指向之前的head节点。
- 当线程B进来的时候,线程B持有的node节点,node的locked属性为true,preNode指向线程A的node节点,线程B的node节点locked属性为true,线程A轮询线程B的node节点的locked状态,为true自旋。
- 线程A执行完后释放锁(修改locked属性为false),线程B轮询到线程A的node节点locked属性为false,结束自旋。
代码实现
CLH自旋锁代码实现:
package io.github.brightloong.concurrent.lock;
import java.util.concurrent.atomic.AtomicReference;
/**
* Created by BrightLoong on 2018/6/13.
* CLH自旋锁,前驱自旋
*/
public class CLHLock {
//指向最后加入的线程
AtomicReference tail = new AtomicReference();
//当前线程持有的节点,使用ThreadLocal实现了变量的线程隔离
ThreadLocal node;
//前驱节点,使用ThreadLocal实现了变量的线程隔离
ThreadLocal preNode = new ThreadLocal();
public CLHLock() {
//初始化node
node = new ThreadLocal() {
//线程默认变量的值,如果不Override这个函数,默认值为null
@Override
protected Node initialValue() {
return new Node();
}
};
//初始化tail,指向一个node,类似一个head节点,并且该节点locked属性为false
tail.set(new Node());
}
public void lock() {
//因为上面提到的构造函数中initialValue()方法,所以每个线程会有一个默认的值
//并且node的locked属性为false.
Node myNode = node.get();
//修改为true,表示需要获取锁
myNode.locked = true;
//获取这之前最后加入的线程,并把当前加入的线程设置为tail,
// AtomicReference的getAndSet操作是原子性的
Node preNode = tail.getAndSet(myNode);
//设置当前节点的前驱节点
this.preNode.set(preNode);
//轮询前驱节点的locked属性,尝试获取锁
while (preNode.locked) {
}
}
public void unlock() {
//解锁很简单,将节点locked属性设置为false,
//这样轮询该节点的另一个线程可以获取到释放的锁
node.get().locked = false;
//当前节点设置为前驱节点,也就是上面初始化提到的head节点
node.set(preNode.get());
}
private class Node{
//默认不需要锁
private boolean locked = false;
}
}
- Node中只有一个locked属性,默认false
- ThreadLocal
node,当前线程的节点,ThreadLocal实现了变量的线程隔离,关于ThreadLocal可以参考——ThreadLocal源码分析 - ThreadLocal
preNode,前驱节点
优点
- 是公平锁,FIFO
- CLH队列锁的优点是空间复杂度低(如果有n个线程,L个锁,每个线程每次只获取一个锁,那么需要的存储空间是O(L+n)
缺点
介绍缺点前先说一下NUMA和SMP两种处理器结构
SMP(Symmetric Multi-Processor),即对称多处理器结构,指服务器中多个CPU对称工作,每个CPU访问内存地址所需时间相同。其主要特征是共享,包含对CPU,内存,I/O等进行共享。SMP的优点是能够保证内存一致性,缺点是这些共享的资源很可能成为性能瓶颈,随着CPU数量的增加,每个CPU都要访问相同的内存资源,可能导致内存访问冲突,可能会导致CPU资源的浪费。常用的PC机就属于这种。
NUMA(Non-Uniform Memory Access)非一致存储访问,将CPU分为CPU模块,每个CPU模块由多个CPU组成,并且具有独立的本地内存、I/O槽口等,模块之间可以通过互联模块相互访问,访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致存储访问NUMA的由来。NUMA优点是可以较好地解决原来SMP系统的扩展问题,缺点是由于访问远地内存的延时远远超过本地内存,因此当CPU数量增加时,系统性能无法线性增加。
现在说CLH锁的缺点是在NUMA系统结构下性能很差,在这种系统结构下,每个线程有自己的内存,如果前趋结点的内存位置比较远,自旋判断前趋结点的locked域,性能将大打折扣。
另一种实现
CLH自旋锁在网上还有一种使用AtomicReferenceFieldUpdater实现的版本,这里也把代码贴出来,个人认为这种版本相比较上面的那种实现更难理解,在代码中添加了一些注释帮助理解。
package io.github.brightloong.concurrent.lock;
import java.util.concurrent.atomic.AtomicReferenceFieldUpdater;
/**
* Created by BrightLoong on 2018/6/17.
*/
public class CLHLock2 {
public static class CLHNode {
// 默认是在等待锁
private boolean isLocked = true;
}
//tail指向最后加入的线程node
private volatile CLHNode tail ;
//AtomicReferenceFieldUpdater基于反射的实用工具,可以对指定类的指定 volatile 字段进行原子更新。
//对CLHLock2类的tail字段进行原子更新。
private static final AtomicReferenceFieldUpdater UPDATER = AtomicReferenceFieldUpdater
. newUpdater(CLHLock2.class, CLHNode .class , "tail" );
/**
* 将node通过参数传入,其实和threadLocal类似,每个线程依然持有了自己的node变量
* @param currentThread
*/
public void lock(CLHNode currentThread) {
//将tail更新成当前线程node,并且返回前一个节点(也就是前驱节点)
CLHNode preNode = UPDATER.getAndSet( this, currentThread);
//如果preNode为空,表示当前没有线程获取锁,直接执行。
if(preNode != null) {
//轮询前驱状态
while(preNode.isLocked ) {
}
}
}
public void unlock(CLHNode currentThread) {
//compareAndSet,如果当前tail里面和currentThread相等,设置成功返回true,
// 表示之后没有线程等待锁,因为tail就是指向当前线程的node。
// 如果返回false,表示还有其他线程等待锁,则更新isLocked属性为false
if (!UPDATER .compareAndSet(this, currentThread, null)) {
currentThread. isLocked = false ;// 改变状态,让后续线程结束自旋
}
}
}
MCS锁
MCS锁可以解决上面的CLH锁的缺点,MCS 来自于其发明人名字的首字母: John Mellor-Crummey和Michael Scott。
MCS Spinlock 是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,直接前驱负责通知其结束自旋(与CLH自旋锁不同的地方,不在轮询前驱的状态,而是由前驱主动通知),从而极大地减少了不必要的处理器缓存同步的次数,降低了总线和内存的开销。
原理
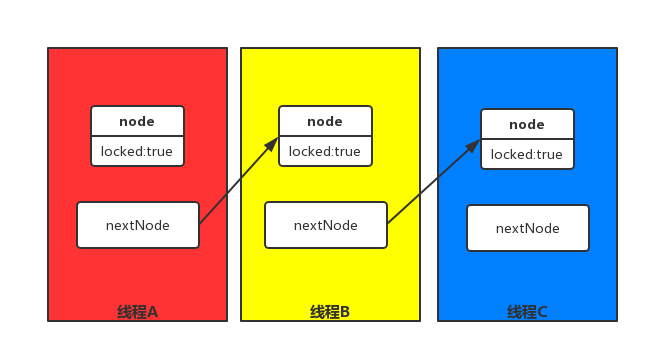
- 每个线程持有一个自己的node,node有一个locked属性,true表示等待获取锁,false表示可以获取到锁,并且持有下一个node(后继者)的引用(可能存在)
- 线程在轮询自己node的locked状态,true表示锁被其他线程暂用,等待获取锁,自旋。
- 线程释放锁的时候,修改后继者(nextNode)的locked属性,通知后继者结束自旋。
代码实现
package io.github.brightloong.concurrent.lock;
import java.util.concurrent.atomic.AtomicReferenceFieldUpdater;
/**
* Created by BrightLoong on 2018/6/17.
*/
public class MCSLock {
public static class MCSNode {
//持有后继者的引用
MCSNode next;
// 默认是在等待锁
boolean locked = true;
}
volatile MCSNode tail;// 指向最后一个申请锁的MCSNode
private static final AtomicReferenceFieldUpdater UPDATER = AtomicReferenceFieldUpdater
.newUpdater(MCSLock.class, MCSNode.class, "tail");
public void lock(MCSNode currentThreadMcsNode) {
//更新tial为最新加入的线程节点,并取出之前的节点(也就是前驱)
MCSNode predecessor = UPDATER.getAndSet(this, currentThreadMcsNode);//step4
//前驱为空表示没有线程占用锁
if (predecessor != null) {
//将当前节点设置为前驱节点的后继者
predecessor.next = currentThreadMcsNode;//step5
//轮询自己的isLocked属性
while (currentThreadMcsNode.locked) {
}
}
}
public void unlock(MCSNode currentThreadMcsNode) {
//UPDATER.get(this) 获取最后加入的线程的node
//如果获取到的最后加入的node和当前node(currentThreadMcsNode)不相同,表示还有其他线程等待锁,直接修改后继者的isLocked属性。
//相同代表当前没其他有线程等待锁,进入下面的处理
if (UPDATER.get(this) == currentThreadMcsNode) {//step1
//这个时候可能会有其他线程又加入了进来,检查时候有人排在自己后面,currentThreadMcsNode.next 表示依然没有染排在自己后面
if (currentThreadMcsNode.next == null) { //step2
//将tail设置为空,如果返回true设置成功,如果返回false,表示设置失败(其他线程加入了进来,使得当前tail持有的节点不等于currentThreadMcsNode)
if (UPDATER.compareAndSet(this, currentThreadMcsNode, null)) {// //step3
// 设置成功返回,没有其他线程等待锁
return;
} else {
// 突然有其他线程加入,需要检测后继者是否有值,因为:step4执行完后,step5可能还没执行完
while (currentThreadMcsNode.next == null) {
}
}
}
//修改后继者的isLocked,通知后继者结束自旋
currentThreadMcsNode.next.locked = false;
currentThreadMcsNode.next = null;// for GC
}
}
}
和CLH锁类似的,我自己用ThreadLocal保存node,而不通过函数传参的方式实现了一个MCS锁,代码如下(大概测试了下没问题,如果有问题希望指出,感谢):
package io.github.brightloong.concurrent.lock;
import java.util.concurrent.atomic.AtomicReferenceFieldUpdater;
/**
* Created by BrightLoong on 2018/6/17.
*/
public class MCSLock2 {
private class MCSNode {
boolean locked = true;
//后继节点
MCSNode next;
}
volatile MCSNode tail;
//AtomicReferenceFieldUpdater来保证tail原子更新
private static final AtomicReferenceFieldUpdater UPDATER = AtomicReferenceFieldUpdater
.newUpdater(MCSLock2.class, MCSNode.class, "tail");
//当前线程持有的节点,使用ThreadLocal实现了变量的线程隔离
ThreadLocal node = new ThreadLocal(){
@Override
protected MCSNode initialValue() {
return new MCSNode();
}
};
public void lock() {
MCSNode myNode = node.get();
MCSNode preNode = UPDATER.getAndSet(this, myNode);
//类似的,preNode == null从tail中没获取到值标志没有线程占用锁
if (preNode != null) {
preNode.next = myNode; //step1
//在自己node的locked变量自旋
while (myNode.locked) {
}
}
}
public void unlock() {
MCSNode myNode = node.get();
MCSNode next = myNode.next;
//如果有后继者,直接设置next.locked = false通知后继者结束自旋.
//如果有执行下面操作
if (next == null) {
//设置成功表示设置期间也没有后继者加入,设置失败表示有后继者加入
if (UPDATER.compareAndSet(this, myNode, null)) {
return;
} else {
//同样的需要等待lock()中step1完成
while (next == null) {
}
}
}
next.locked = false;
next = null; //for CG
}
}
参考
- https://www.cnblogs.com/tonylovett/p/5254765.html
- http://www.360doc.com/content/14/0811/22/1073512_401149458.shtml