谷歌机器学习速成课程学习笔记
谷歌机器学习速成课程学习笔记
- 谷歌机器学习速成课程学习笔记
- 1 framing
- 2 深入了解
- 3 tensorflow
- 4 pandas
- 5 tensorFlow基本步骤
- 6 泛化
- 7 数据集划分
- 8 特征工程
- 良好的特征:
- 清理数据
- 特征缩放
- 处理极端离群值
- 分箱
- 清查
- 熟悉数据
- 编程训练
- 9 特征组合
- 组合one hot矢量
- 编程练习
- one hot编码
- 分桶(分箱)
- 特征组合:
- 10 L2 正则化
- 11 逻辑回归
- 12 分类
- 各种指标
- 编程练习
- 13 正则化:稀疏性
- 14 神经网络
- 15 机器学习工程
- 离线训练 和 在线训练
- 离线推理 在线推理
- 数据依赖关系
- 16 现实应用
- 17 机器学习准则
1 framing
- 标签:我们要预测的真实事物:y
- 基本线性回归中的y变量
- 特征:描述数据的输入变量: xi x i
- 基本线性回归中的 {x1、x2、x3} { x 1 、 x 2 、 x 3 } 变量
- 样本:数据的特定实例: x x
- 有标签样本:<特征,标签>;(x, y)
- 用于训练模型
- 无标签样本 <特征,?>:(x,?)
- 用于对新数据做出预测
- 模型:可以将样本映射到预测标签: y′ y ′
- 预测由模型内部参数定义,这些内部参数是通过学习得到的
合适的特征应该是具体且可以量化的。漂不漂亮等无法量化,太主观,能否转化为其他具体特征。比如鞋子的颜色、样式等具体的方面。
2 深入了解
- b b (bias)在有的机器学习教材中也写做 w0 w 0
- 损失函数:
均方误差MSE:
MSE=1N∑(x,y∈D)(y−prediction(x))2 M S E = 1 N ∑ ( x , y ∈ D ) ( y − p r e d i c t i o n ( x ) ) 2
除了MSE作为损失函数,也有其他损失函数,MSE不是唯一的,也不是适用于所有情形的最佳损失函数 - 神经网络非凸,落到哪个最小值很大程度上取决于初始值
- 小批量随机梯度下降法
3 tensorflow
结构:
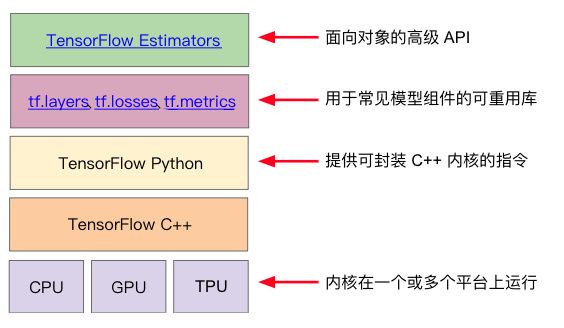
分为:
图协议缓冲区
执行(分布式)图的运行时
前者类似于java编译器,后者类似于JVM
学习高级API:tensorflow.estimators
4 pandas
# coding:utf-8
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
city_names = pd.Series(['San Francisco', 'San Jose', 'Sacramento'])
population = pd.Series([852469, 1015785, 485199])
cities = pd.DataFrame({'City name': city_names, 'Population': population})
print()
print(cities.head())
print()
print(type(cities['City name']))
print()
print(cities['City name'])
cities['Area square miles'] = pd.Series([46.87, 176.53, 97.92])
cities['Population density'] = cities['Population'] / cities['Area square miles']
cities['is wide and has saint name'] = (cities['Area square miles'] > 50) & cities['City name'].apply(
lambda name: name.startswith('San'))
print()
print(cities)
cities_1 = cities.reindex([2, 0, 1]) # 索引不变,位置发生变化
print()
print(cities_1.head()) # cities 不变,生成新的DataFrame
# 一般情况下,在开始创建Series和DataFrame的时候,会按照源数据的顺序添加索引
# 索引一旦生成,就永远不会变,索引是稳定的
# 即使数据的排列顺序发生了变化,也不会改变
cities_2 = cities.reindex(np.random.permutation(cities.index))
# pd.set_option('max_columns', 5)
print()
print(cities_2.head())
cities_3 = cities.reindex([2, 3, 4]) # 允许在reinde中添加新的索引,并填充NaN
print()
print(cities_3.head())
#输出:
/Users/tu/PycharmProjects/myFirstPythonDir/venv/bin/python /Users/tu/PycharmProjects/myFirstPythonDir/mytest/numpyDemo/googlepandas.py
City name Population
0 San Francisco 852469
1 San Jose 1015785
2 Sacramento 485199
<class 'pandas.core.series.Series'>
0 San Francisco
1 San Jose
2 Sacramento
Name: City name, dtype: object
City name ... is wide and has saint name
0 San Francisco ... False
1 San Jose ... True
2 Sacramento ... False
[3 rows x 5 columns]
City name ... is wide and has saint name
2 Sacramento ... False
0 San Francisco ... False
1 San Jose ... True
[3 rows x 5 columns]
City name ... is wide and has saint name
0 San Francisco ... False
2 Sacramento ... False
1 San Jose ... True
[3 rows x 5 columns]
City name ... is wide and has saint name
2 Sacramento ... False
3 NaN ... NaN
4 NaN ... NaN
[3 rows x 5 columns]
Process finished with exit code 05 tensorFlow基本步骤
使用tensorflow estimator训练一个预测房价的线性回归模型
6 泛化
- 过拟合:
模型在训练集数据上损失很低,在测试集数据上很高。因为模型拟合的过于复杂。
为此,机器学习必须有奥卡姆剃刀原则 - 监督学习数据要求:
独立同分布
分布不会发生变化
从同一个分布中抽取样本
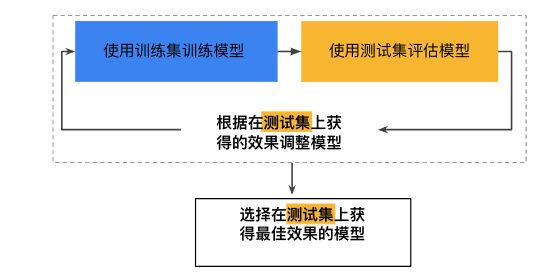
7 数据集划分
将数据集分为训练集和测试集,用训练集训练,测试集评估,根据评估的结果调整超参数,再次用训练集训练,如此反复下去,模型会在测试集上过拟合,测试集也丧失了测试拟合程度的意义。
所以需要再划分:训练集,交叉验证集,测试集

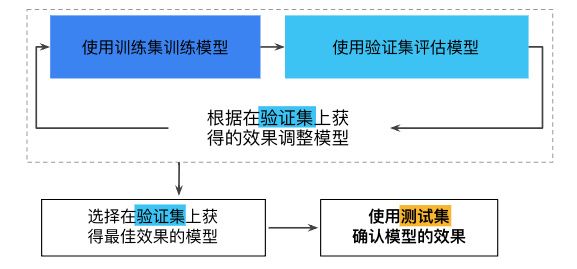
不断用验证集和测试集会导致效果降低。
即,不断地依靠验证集以及之后的测试集的次数越多,最后对于数据是否能泛化到没见过的新数据的信息就越低。
所以需要更多的数据来更新测试集和验证集。
机器学习的调试:
很多时候都是在对数据调试,而不是代码。
- 不随机数据,划分数据集:
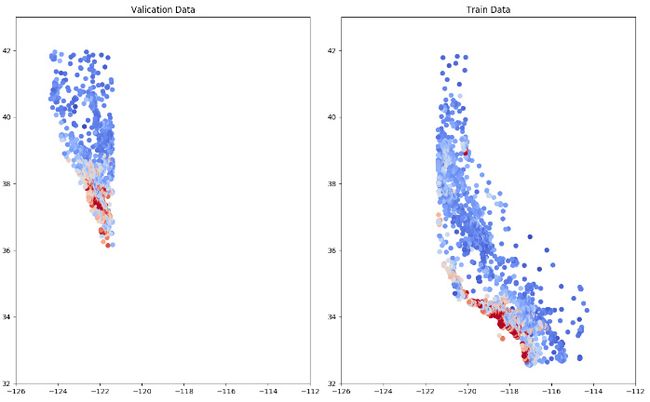
- 随机后划分:
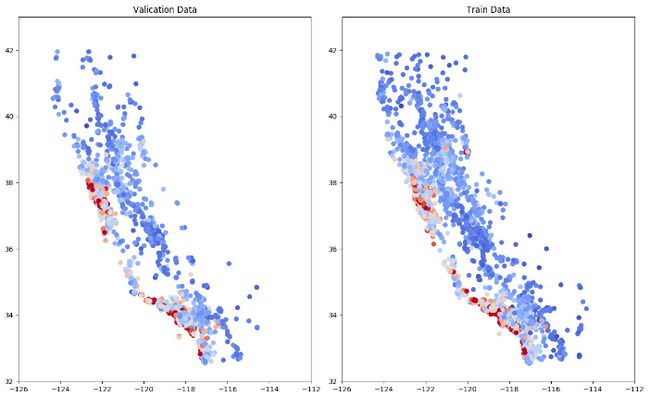
测试集、训练集和交叉验证集的分布一定要大致一致。
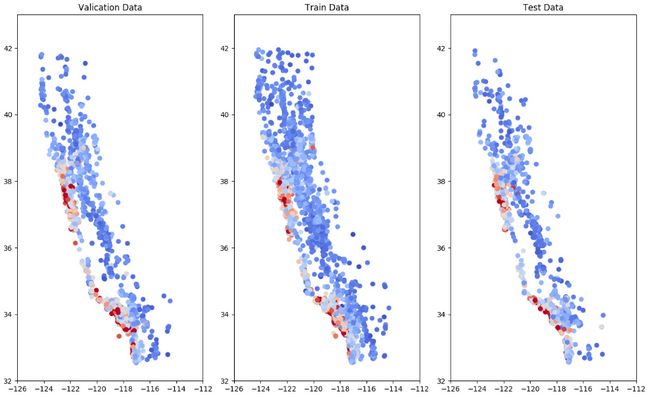
误差在三个数据集上的表现。
测试数据集链接
代码如下:
import math
from IPython import display
from matplotlib import cm
from matplotlib import gridspec
from matplotlib import pyplot as plt
import os
import numpy as np
import pandas as pd
from sklearn import metrics
import tensorflow as tf
from tensorflow.python.data import Dataset
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.logging.set_verbosity(tf.logging.ERROR) # DEBUG INFO WARN ERROR FATAL
pd.options.display.max_rows = 10
pd.options.display.max_columns = 9
pd.options.display.float_format = '{:.1f}'.format
# 加载数据集
california_housing_dataframe = pd.read_csv("california_housing_train.csv", sep=',')
california_housing_test_dataframe = pd.read_csv("california_housing_test.csv", sep=',')
# 随机数据,很重要的一步
california_housing_dataframe = california_housing_dataframe.reindex(
np.random.permutation(california_housing_dataframe.index))
def process_feature(california_housing_dataframe):
selected_feature = california_housing_dataframe[
["longitude", "latitude", "housing_median_age", "total_rooms", "total_bedrooms", "population", "households",
"median_income"]]
processed_feature = selected_feature.copy()
processed_feature['rooms_per_population'] = processed_feature['total_rooms'] / processed_feature['population']
return processed_feature
def process_target(california_housing_dataframe):
output_target = pd.DataFrame()
output_target['median_house_value'] = california_housing_dataframe['median_house_value'] / 1000.0
return output_target
# 数据被分为训练集、验证集
train_examples = process_feature(california_housing_dataframe.head(12000))
train_targets = process_target(california_housing_dataframe.head(12000))
# print("\n训练集:")
# print(train_examples.describe())
# print(train_targets.describe())
validation_examples = process_feature(california_housing_dataframe.tail(5000))
validation_targets = process_target(california_housing_dataframe.tail(5000))
# print('\n交叉验证集:')
# print(validation_examples.describe())
# print(validation_targets.describe())
#
# print('\n没有测试集')
# 检查数据,绘制经纬度图
# plt.figure(figsize=(13, 8))
#
# ax = plt.subplot(1, 2, 1)
# ax.set_title('Valication Data')
# ax.set_autoscaley_on(False)
# ax.set_ylim([32, 43])
# ax.set_autoscalex_on(False)
# ax.set_xlim([-126, -112])
# plt.scatter(validation_examples['longitude'], validation_examples['latitude'], cmap='coolwarm',
# c=validation_targets['median_house_value'] / validation_targets['median_house_value'].max())
#
# ax = plt.subplot(1, 2, 2)
# ax.set_title('Train Data')
# ax.set_autoscaley_on(False)
# ax.set_ylim([32, 43])
# ax.set_autoscalex_on(False)
# ax.set_xlim(-126, -112)
# plt.scatter(train_examples['longitude'], train_examples['latitude'], cmap='coolwarm',
# c=train_targets['median_house_value'] / train_targets['median_house_value'].max())
test_examples = process_feature(california_housing_test_dataframe)
test_targets = process_target(california_housing_test_dataframe)
# 4.定义输入函数
def my_input_fn(features, targets, batch_size=1, shuffle=True, num_epochs=None):
"""
输入函数
:param features: 输入特征
:param targets: 数据标签
:param batch_size: 输出数据的大小
:param shuffle: 随机抽取数据
:param num_epochs:重复的次数
:return:数据和标签
"""
features = {key: np.array(value) for key, value in dict(features).items()}
ds = Dataset.from_tensor_slices((features, targets)) # 2GB限制
ds = ds.batch(batch_size).repeat(num_epochs)
if shuffle:
ds = ds.shuffle(buffer_size=10000)
features, labels = ds.make_one_shot_iterator().get_next()
return features, labels
def construct_feature_columns(input_features):
return set([tf.feature_column.numeric_column(my_feature) for my_feature in input_features])
def train_model(learning_rate, steps, batch_size, train_examples, train_targets, validation_examples,
validation_targets, test_examples, test_targets, periods=10):
steps_per_periods = steps / periods # 每次报告时所走的步长
# 最优化函数
my_optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
my_optimizer = tf.contrib.estimator.clip_gradients_by_norm(my_optimizer, 5.0) # 梯度裁剪
# 模型
linear_regressor = tf.estimator.LinearRegressor(feature_columns=construct_feature_columns(train_examples),
optimizer=my_optimizer)
# 定义输入函数
training_input_fn = lambda: my_input_fn(train_examples, train_targets['median_house_value'], batch_size=batch_size)
prediction_training_input_fn = lambda: my_input_fn(train_examples, train_targets['median_house_value'],
num_epochs=1, shuffle=False)
prediction_validation_input_fn = lambda: my_input_fn(validation_examples, validation_targets['median_house_value'],
num_epochs=1,
shuffle=False)
prediction_test_input_fn = lambda: my_input_fn(test_examples, test_targets['median_house_value'],
num_epochs=1,
shuffle=False)
print('Training model ...')
print('RMSE:')
training_rmse = []
validation_rmse = []
test_rmse = []
for period in range(0, periods):
linear_regressor.train(input_fn=training_input_fn, steps=steps_per_periods)
training_predictions = linear_regressor.predict(input_fn=prediction_training_input_fn)
training_predictions = np.array([item['predictions'][0] for item in training_predictions])
# item是这样的:{'predictions': array([0.015675], dtype=float32)}
validation_predictions = linear_regressor.predict(input_fn=prediction_validation_input_fn)
validation_predictions = np.array([item['predictions'][0] for item in validation_predictions])
test_predictions = linear_regressor.predict(input_fn=prediction_test_input_fn)
test_predictions = np.array([item['predictions'][0] for item in test_predictions])
# 误差
training_root_mean_squared_error = math.sqrt(metrics.mean_squared_error(training_predictions, train_targets))
validation_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(validation_predictions, validation_targets))
test_root_mean_squared_error = math.sqrt(metrics.mean_squared_error(test_predictions, test_targets))
print('period %02d : %.2f' % (period, training_root_mean_squared_error))
training_rmse.append(training_root_mean_squared_error)
validation_rmse.append(validation_root_mean_squared_error)
test_rmse.append(test_root_mean_squared_error)
print('Model training finished.')
plt.figure()
plt.ylabel('RMSE')
plt.xlabel('Periods')
plt.title('Root mean squared error vs. periods')
plt.tight_layout()
plt.plot(training_rmse, label='training')
plt.plot(validation_rmse, label='validation')
plt.plot(test_rmse, label='test')
plt.legend()
plt.show()
return linear_regressor
train_model(learning_rate=0.00003, steps=5000, batch_size=5, train_examples=train_examples, train_targets=train_targets,
validation_examples=validation_examples, validation_targets=validation_targets, test_examples=test_examples,
test_targets=test_targets, periods=100)8 特征工程
将原始数据转换成特征矢量,叫特征工程。
- 数值型特征直接照搬
- 字符串one hot编码:
- 先对字符串数据整理词汇表,同时有一个词汇表中没有的其他类
- 对词汇表进行one hot编码
- 类别数据:布尔类型
良好的特征:
- 避免使用特征值出现频率很少的那种特征,很离散的特征值。比如预测人的时候用身份证号码作为特征,根本就没有重复的身份证号。不适合。
- 含义清晰,人人能懂
- 将异常值从实际的数据中剔除
- 考虑到不稳定性,数据最好是稳定的。
清理数据
即使是少量的异常数据也会破坏掉一个大规模数据集。
特征缩放
- 改善梯度下降速度
- 避免NaN陷阱
- 节省模型精力
处理极端离群值
- 对数缩放,尾巴减小
- 限制数据的范围,尾巴消失,边界出现小峰值
分箱
将浮点数特征分成离散特征(一个矢量),可以均分,也可以按照分位数分;
清查
- 把不可靠样本干掉:
遗漏值:某个样本的一个特征没有特征值
重复样本
错误的标签
错误的特征值
这样的样本都从数据集中筛除
- 检查出不良的数据,用直方图、最大值最小值、均值、中位数、标准差。
- 检查离散特征最常见特征值的列表,看是否符合预期。
熟悉数据
知道预期的数据状态,并检查手上的数据是否满足预期,或者解释为什么不满足预期,检查训练数据和其他来源的数据是否一致。
编程训练
相关系数
范围在[-1, 1]之间。
程序根据相关性来选择特征,同时对某些特征进行了分桶
选择了收入中位数和纬度作为特征
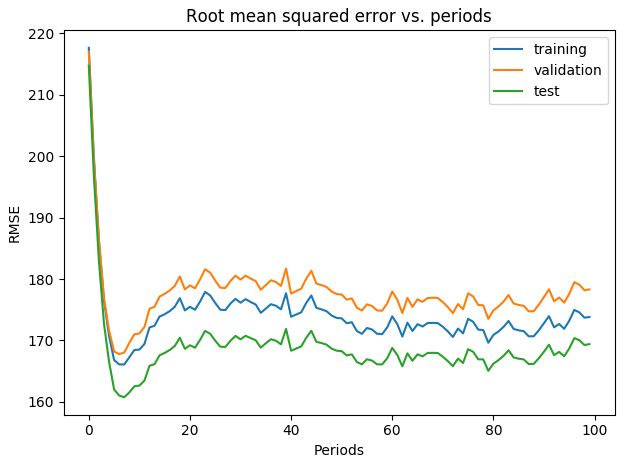
对纬度进行分桶,将浮点数分为整数桶,效果显著
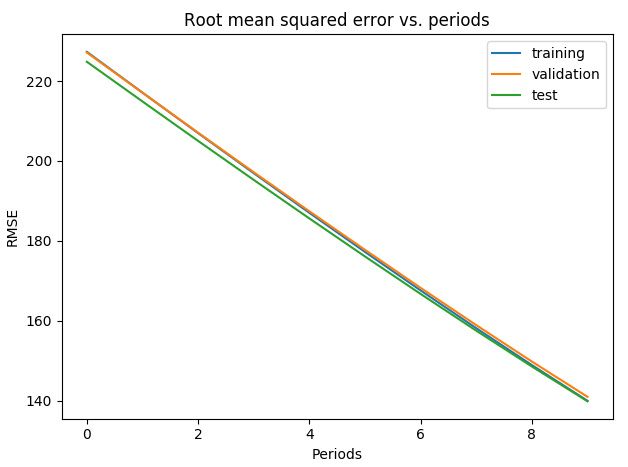
改变学习率(变大),加大学习steps:

对数据进行清理,之后分桶,大大减少了误差
"""
创建一个集合:用更少的特征取得跟复杂特征效果一样好的成果
特征少,模型使用的资源就少,更加易于维护
"""
import math
from IPython import display
from matplotlib import cm
from matplotlib import gridspec
from matplotlib import pyplot as plt
import os
import numpy as np
import pandas as pd
from sklearn import metrics
import tensorflow as tf
from tensorflow.python.data import Dataset
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.logging.set_verbosity(tf.logging.ERROR) # DEBUG INFO WARN ERROR FATAL
pd.options.display.max_rows = 10
pd.options.display.max_columns = 10
pd.options.display.float_format = '{:.1f}'.format
# 加载数据集
california_housing_dataframe = pd.read_csv("california_housing_train.csv", sep=',')
california_housing_test_dataframe = pd.read_csv("california_housing_test.csv", sep=',')
# 随机数据,很重要的一步
california_housing_dataframe = california_housing_dataframe.reindex(
np.random.permutation(california_housing_dataframe.index))
def process_feature(california_housing_dataframe):
selected_feature = california_housing_dataframe[
["longitude", "latitude", "housing_median_age", "total_rooms", "total_bedrooms", "population", "households",
"median_income"]]
processed_feature = selected_feature.copy()
processed_feature['rooms_per_population'] = processed_feature['total_rooms'] / processed_feature['population']
return processed_feature
def process_target(california_housing_dataframe):
output_target = pd.DataFrame()
output_target['median_house_value'] = california_housing_dataframe['median_house_value'] / 1000.0
return output_target
# 数据被分为训练集、验证集
train_examples = process_feature(california_housing_dataframe.head(12000))
train_targets = process_target(california_housing_dataframe.head(12000))
print("\n训练集:")
display.display(train_examples.describe())
print("\n训练集标签:")
display.display(train_targets.describe())
validation_examples = process_feature(california_housing_dataframe.tail(5000))
validation_targets = process_target(california_housing_dataframe.tail(5000))
print('\n交叉验证集:')
display.display(validation_examples.describe())
print("\n交叉验证集标签:")
display.display(validation_targets.describe())
test_examples = process_feature(california_housing_test_dataframe)
test_targets = process_target(california_housing_test_dataframe)
print('\n测试集:')
display.display(test_examples.describe())
print("\n测试集标签:")
display.display(test_targets.describe())
# 检查数据,绘制经纬度图
# plt.figure(figsize=(13, 8))
#
# ax = plt.subplot(1, 3, 1)
# ax.set_title('Valication Data')
# ax.set_autoscaley_on(False)
# ax.set_ylim([32, 43])
# ax.set_autoscalex_on(False)
# ax.set_xlim([-126, -112])
# plt.scatter(validation_examples['longitude'], validation_examples['latitude'], cmap='coolwarm',
# c=validation_targets['median_house_value'] / validation_targets['median_house_value'].max())
#
# ax = plt.subplot(1, 3, 2)
# ax.set_title('Train Data')
# ax.set_autoscaley_on(False)
# ax.set_ylim([32, 43])
# ax.set_autoscalex_on(False)
# ax.set_xlim(-126, -112)
# plt.scatter(train_examples['longitude'], train_examples['latitude'], cmap='coolwarm',
# c=train_targets['median_house_value'] / train_targets['median_house_value'].max())
#
# ax = plt.subplot(1, 3, 3)
# ax.set_title('Test Data')
# ax.set_autoscaley_on(False)
# ax.set_ylim([32, 43])
# ax.set_autoscalex_on(False)
# ax.set_xlim(-126, -112)
# plt.scatter(test_examples['longitude'], test_examples['latitude'], cmap='coolwarm',
# c=test_targets['median_house_value'] / test_targets['median_house_value'].max())
#
# plt.show()
"""
构建良好的特征集
用相关矩阵,找出原始特征之间的相关性
要有与目标有相关性的特征,也要有独立的特征;
"""
correlation_dataframe = train_examples.copy()
correlation_dataframe['target'] = train_targets.copy()
correlation_metrix = correlation_dataframe.corr()
print("\n相关矩阵:")
display.display(correlation_metrix)
'''
longitude latitude 负相关 -0.9
total_rooms total_bedrooms population households 正向关 0.9 1.0
median_income target 正向关 0.7;即与目标相关的特征为median_income
根据相关矩阵,合成特征,移除特征,
'''
# 4.定义输入函数
def my_input_fn(features, targets, batch_size=1, shuffle=True, num_epochs=None):
"""
输入函数
:param features: 输入特征
:param targets: 数据标签
:param batch_size: 输出数据的大小
:param shuffle: 随机抽取数据
:param num_epochs:重复的次数
:return:数据和标签
"""
features = {key: np.array(value) for key, value in dict(features).items()}
ds = Dataset.from_tensor_slices((features, targets)) # 2GB限制
ds = ds.batch(batch_size).repeat(num_epochs)
if shuffle:
ds = ds.shuffle(buffer_size=10000)
features, labels = ds.make_one_shot_iterator().get_next()
return features, labels
def construct_feature_columns(input_features):
return set([tf.feature_column.numeric_column(my_feature) for my_feature in input_features])
def train_model(learning_rate, steps, batch_size, train_examples, train_targets, validation_examples,
validation_targets, test_examples, test_targets, periods=10):
steps_per_periods = steps / periods # 每次报告时所走的步长
# 最优化函数
my_optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
my_optimizer = tf.contrib.estimator.clip_gradients_by_norm(my_optimizer, 5.0) # 梯度裁剪
# 模型
linear_regressor = tf.estimator.LinearRegressor(feature_columns=construct_feature_columns(train_examples),
optimizer=my_optimizer)
# 定义输入函数
training_input_fn = lambda: my_input_fn(train_examples, train_targets['median_house_value'], batch_size=batch_size)
prediction_training_input_fn = lambda: my_input_fn(train_examples, train_targets['median_house_value'],
num_epochs=1, shuffle=False)
prediction_validation_input_fn = lambda: my_input_fn(validation_examples, validation_targets['median_house_value'],
num_epochs=1,
shuffle=False)
prediction_test_input_fn = lambda: my_input_fn(test_examples, test_targets['median_house_value'],
num_epochs=1,
shuffle=False)
print('Training model ...')
print('RMSE:')
training_rmse = []
validation_rmse = []
test_rmse = []
for period in range(0, periods):
linear_regressor.train(input_fn=training_input_fn, steps=steps_per_periods)
training_predictions = linear_regressor.predict(input_fn=prediction_training_input_fn)
training_predictions = np.array([item['predictions'][0] for item in training_predictions])
# item是这样的:{'predictions': array([0.015675], dtype=float32)}
validation_predictions = linear_regressor.predict(input_fn=prediction_validation_input_fn)
validation_predictions = np.array([item['predictions'][0] for item in validation_predictions])
test_predictions = linear_regressor.predict(input_fn=prediction_test_input_fn)
test_predictions = np.array([item['predictions'][0] for item in test_predictions])
# 误差
training_root_mean_squared_error = math.sqrt(metrics.mean_squared_error(training_predictions, train_targets))
validation_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(validation_predictions, validation_targets))
test_root_mean_squared_error = math.sqrt(metrics.mean_squared_error(test_predictions, test_targets))
print('period %02d : %.2f' % (period, training_root_mean_squared_error))
training_rmse.append(training_root_mean_squared_error)
validation_rmse.append(validation_root_mean_squared_error)
test_rmse.append(test_root_mean_squared_error)
print('Model training finished.')
plt.figure()
plt.ylabel('RMSE')
plt.xlabel('Periods')
plt.title('Root mean squared error vs. periods')
plt.tight_layout()
plt.plot(training_rmse, label='training')
plt.plot(validation_rmse, label='validation')
plt.plot(test_rmse, label='test')
plt.legend()
plt.show()
return linear_regressor
'''
longitude latitude 负相关 -0.9
total_rooms total_bedrooms population households 正向关 0.9 ~ 1.0
median_income target 正向关 0.7;即与目标相关的特征为median_income
housing_median_age 与 total_rooms total_bedrooms population households 负相关 -0.3 ~ -0.4
根据相关矩阵,合成特征,移除特征,
'''
# minimal_features = ["latitude", "median_income"]
#
# assert minimal_features, "至少必须有一个特征"
#
# minimal_features_train_examples = train_examples[minimal_features]
# minimal_features_validation_examples = validation_examples[minimal_features]
# minimal_features_test_examples = test_examples[minimal_features]
# plt.scatter(train_examples["latitude"], train_targets['median_house_value'])
# plt.show()
# 分桶
def select_and_transform_features(source_df):
LATITUDE_RANGES = zip(range(32, 42), range(33, 43))
selected_examples = pd.DataFrame()
selected_examples['median_income'] = source_df['median_income'].copy()
for r in LATITUDE_RANGES:
selected_examples['latitude_%d_%d' % r] = source_df['latitude'].apply(
lambda l: 1 if r[0] <= l < r[1] else 0)
return selected_examples
selected_train_examples = select_and_transform_features(train_examples)
selected_validation_examples = select_and_transform_features(validation_examples)
selected_test_examples = select_and_transform_features(test_examples)
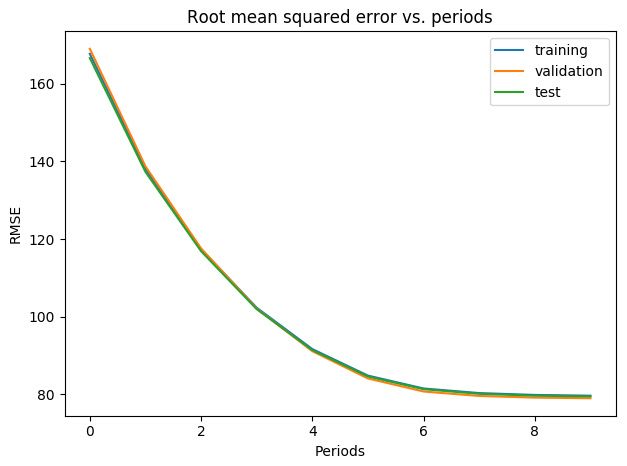
# 减少特征后,学习率降低,运算负担减轻
train_model(learning_rate=0.1, steps=2000, batch_size=5, train_examples=selected_train_examples,
train_targets=train_targets,
validation_examples=selected_validation_examples, validation_targets=validation_targets,
test_examples=selected_test_examples,
test_targets=test_targets, periods=20)9 特征组合
用特征组合+大数据是学习复杂模型的有效策略
神经网络是另外一种策略
组合特征在这里可以理解为就是多项式回归的一些项。区别于线性回归的项。
组合one hot矢量
叫做逻辑连接
特征组合本质上可以表达更加丰富准确的信息。
特征组合可以使得线性回归模型可以拟合非线性数据。
编程练习
FTRL优化算法
my_optimizer = tf.train.FtrlOptimizer(learning_rate=learning_rate)
one hot编码
将离散特征(字符串、枚举、整数)进行one hot 编码
分桶(分箱)
可以将连续特征分桶,进而one hot编码
对全部特征进行分桶的结果:

# 基于分位数的分桶
def get_quantile_based_boundaries(feature_values, num_buckets):
boundaries = np.arange(1.0, num_buckets) / num_buckets
quantile = feature_values.quantile(boundaries) # Series
return [quantile[q] for q in quantile.keys()] # list
def construct_feature_columns():
households = tf.feature_column.numeric_column('households')
longitude = tf.feature_column.numeric_column('longitude')
latitude = tf.feature_column.numeric_column('latitude')
housing_median_age = tf.feature_column.numeric_column('housing_median_age')
total_rooms = tf.feature_column.numeric_column('total_rooms')
total_bedrooms = tf.feature_column.numeric_column('total_bedrooms')
population = tf.feature_column.numeric_column('population')
median_income = tf.feature_column.numeric_column('median_income')
rooms_per_population = tf.feature_column.numeric_column('rooms_per_population')
bucketized_households = tf.feature_column.bucketized_column(households, get_quantile_based_boundaries(
train_examples["households"], 7)) # households分为7个桶
bucketized_longitude = tf.feature_column.bucketized_column(longitude, get_quantile_based_boundaries(
train_examples['longitude'], 10)) # longitude分为10个桶
bucketized_latitude = tf.feature_column.bucketized_column(latitude, get_quantile_based_boundaries(
train_examples["latitude"], 10))
bucketized_housing_median_age = tf.feature_column.bucketized_column(housing_median_age,
get_quantile_based_boundaries(
california_housing_dataframe[
"housing_median_age"], 10))
bucketized_total_rooms = tf.feature_column.bucketized_column(total_rooms, get_quantile_based_boundaries(
train_examples["total_rooms"], 10))
bucketized_total_bedrooms = tf.feature_column.bucketized_column(total_bedrooms, get_quantile_based_boundaries(
train_examples["total_bedrooms"], 10))
bucketized_population = tf.feature_column.bucketized_column(population, get_quantile_based_boundaries(
train_examples["population"], 10))
bucketized_median_income = tf.feature_column.bucketized_column(median_income, get_quantile_based_boundaries(
train_examples["median_income"], 10))
bucketized_rooms_per_population = tf.feature_column.bucketized_column(rooms_per_population,
get_quantile_based_boundaries(
train_examples["rooms_per_population"],
10))
feature_columns = {bucketized_households,
bucketized_longitude,
bucketized_latitude,
bucketized_housing_median_age,
bucketized_total_rooms,
bucketized_total_bedrooms,
bucketized_population,
bucketized_median_income,
bucketized_rooms_per_population}
return feature_columns特征组合:
又叫特征交叉
对连续数据离散化(分桶),之后进行特征组合。
在特征组合之后,对模型仍需要提供原始特征,原始特征可以帮助模型区分包含不同特征交叉的hash存储区域内容
long_x_lat = tf.feature_column.crossed_column(keys=[bucketized_longitude, bucketized_latitude],
hash_bucket_size=1000)
feature_columns = {bucketized_households,
bucketized_longitude,
bucketized_latitude,
bucketized_housing_median_age,
bucketized_total_rooms,
bucketized_total_bedrooms,
bucketized_population,
bucketized_median_income,
bucketized_rooms_per_population,
long_x_lat}
与单纯的分桶相比,特征组合降低了误差。
10 L2 正则化
正则化用来解决过拟合问题,过拟合如下所示:
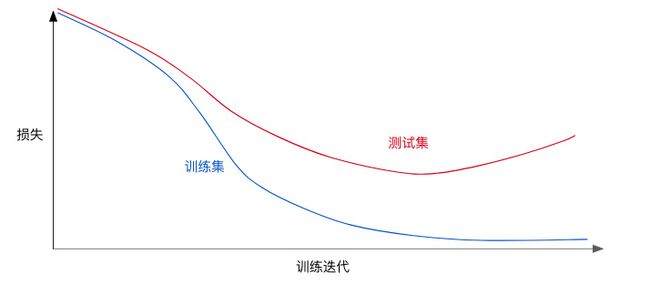
为了防止过拟合,不光要考虑模型的损失,也要考虑模型的复杂度。
L2正则化项和正则化率 λ λ
λ λ 小,容易过拟合
λ λ 大,容易欠拟合
L2正则化对模型的影响:
- 使得权重接近于0
- 使得权重平均值接近于0
- 使得权重呈正态分布
11 逻辑回归
逻辑回归会不断的促使损失趋近于0;所以必须进行:
L2正则化
早停法,限制训练的步数或学习速率
逻辑回归输出的是概率。
12 分类
所以要设置阈值进行分类。
分类会涉及到一些指标:
各种指标
- 混淆矩阵
| 实 | 际 | |
|---|---|---|
| 真正例 | 假正例 | |
| 预 | 预测狼要来——>狼来了 | 预测狼要来——>狼没来 |
| 测 | 假负例 | 真负例 |
| 没预警,结果狼来了 | 没预警,狼也没来 |
即:
| TP | FP |
|---|---|
| FN | TN |
- 准确率
准确率具有误导性:
- 不同类型的错误具有不同的代价
- 分类不平衡,正类别或者负类别很少
accuracy=TP+TNTP+FP+FN+TN a c c u r a c y = T P + T N T P + F P + F N + T N
所有样本中,识别正确的比例
- 精确率:
precision=TPTP+FP p r e c i s i o n = T P T P + F P
预测狼要来,狼来了的比例
在被识别为正例的样本中,确实是正例的比例 - 召回率:
recall=TPTP+FN r e c a l l = T P T P + F N
狼来了,预测出狼要来的比例
也就是看预测漏掉了多少正例
在所有正类别中,被正确识别为正例的比例
精确率和召回率是一对矛盾,随着分类阈值的变化,此消彼长。
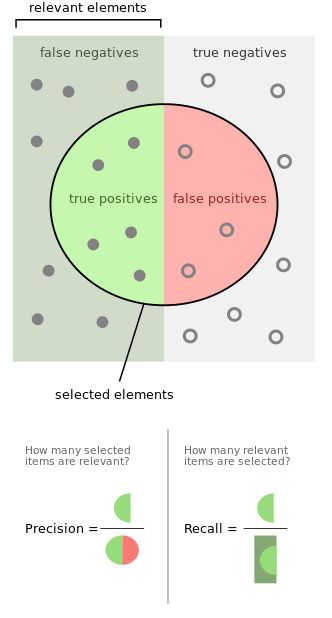
- F1 score是精确率和召回率的 harmonic mean (调和平均数)
F1=21recall+1precision=2precision×recallprecision+recall F 1 = 2 1 r e c a l l + 1 p r e c i s i o n = 2 p r e c i s i o n × r e c a l l p r e c i s i o n + r e c a l l
进一步:
Fβ=(1+β)precision×recall(β2×precision)+recall F β = ( 1 + β ) p r e c i s i o n × r e c a l l ( β 2 × p r e c i s i o n ) + r e c a l l
即可以对精确率和召回率附上不同的权重。 - ROC
receiver operating characteristic:接受者操作特征
真正例率 TPR=TPTP+FN 真 正 例 率 T P R = T P T P + F N
假正例率 FPR=FPFP+TN 假 正 例 率 F P R = F P F P + T N
一个分类的阈值对应一对TPR和FPR,将所有的阈值下的TPR和FPR计算出来,绘制到一张图上,就是ROC:
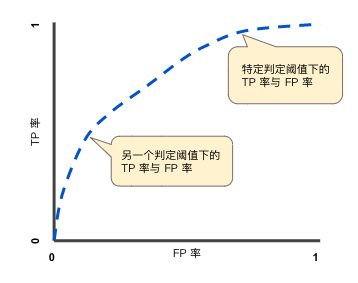
其中,横轴为假正例率;纵轴为真正例率;
我们常用ROC曲线下面积AUC AUC
Area under curve:曲线下面积

ROC曲线下面积表示随机正例样本位于随机负例右侧的概率

即,随机的给出一个正样本,一个负样本,分类器将正样本识别为正样本的概率大于将负样本识别为正样本的概率的概率;
AUC越大,分类的效果越好;
如果AUC达到了1,很有可能不是你的模型无敌,而是你错了,检查一下是否过拟合、是否将label作为feature等情况。预测偏差
预测偏差 = 预测平均值 - 数据集的标签的实际平均值
比如,我们知道垃圾邮件在邮件中出现的概率是1%,如果模型预测的结果是垃圾邮件在邮件中出现的概率是30%,那么这个模型存在较大的预测偏差。
造成的原因可能有:- 特征集不完整
- 训练集样本有偏差
- 数据集混乱
- 造模型的某一步出了问题
- 正则化的过多了
一种办法是给已经训练好的模型加校准层,但:
(1)校准层治标不治本,还是不知道出问题的原因
(2)使得系统更加复杂,也更加脆弱。
- 分桶偏差
我们希望预测偏差尽可能的小,但是统计偏差不是一两个点的事,需要一大堆点来计算,所以可以对整个数据集进行分桶,每一个桶的有一个(预测平均值,实际平均均值),将这些桶的值绘制

希望这些点都位于误差限内;
上边的这个模型一部分预测的很糟糕,可能的原因有:
训练集代表不了整个数据空间,无法表达出数据空间的某个子集
数据集的某个子集比较混乱
正则化太严重
编程练习
逻辑回归
linear_classifier=tf.estimator.LinearClassifier(feature_columns=construct_feature_columns(training_examples),
optimizer=my_optimizer)
13 正则化:稀疏性
正则化有L0正则化,L1正则化,L2正则化。
L2正则化解决过拟合的问题。
L1正则化解决稀疏特征的问题。
如果模型包含大量的稀疏矢量,同时这些稀疏特征进行特征组合,会耗费很大的计算资源。如果能将高维度稀疏特征的权重降为0,就可以节省资源。
L2正则化可以降低权重。
L1正则化可以使得模型中信息缺失的权重正好为0。
14 神经网络
- 梯度消失
- 训练过程中,较低层网络 的 梯度逐渐消失到0,导致训练速度非常缓慢甚至不再训练
- ReLU有助于防止梯度消失
- 梯度爆炸
- 网络权重过大,导致梯度涉及到很多大项乘积,进而导致梯度爆炸; 导致网络难以收敛
- 批处理化可以降低学习速率,有助于防止梯度爆炸
- ReLU单元消失
- 加权低于0,对网络输出无贡献。反向传播也被切断。
- 降低学习速率,有助于防止 ReLU单元消失
- 丢弃正则化
- 名为丢弃的正则化,在梯度下降的时候随机丢一些网络单元。丢的越多,正则化效果越强。
15 机器学习工程
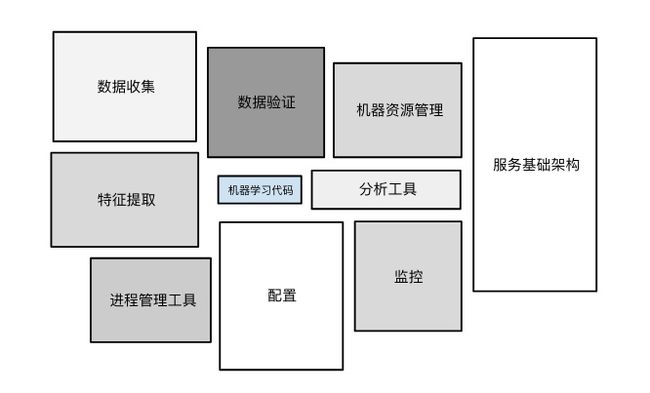
机器学习代码就是自己构建的模型,在整个工程中仅占一部分。
离线训练 和 在线训练

| 离线训练 | 在线训练 |
|---|---|
| 容易构建、测试:可批量训练、批量测试,不断迭代可以达到很好的效果 | 可以随着时间的推移不断的为训练数据添加新的数据,可以定期同步更新到最新版本; 使用渐进式验证,不是批量训练和批量测试 |
| 模型容易过时 | 可以根据变化进行调整,不会过时 |
| 也需要对输入进行监控 | 需要监控、模型回滚、数据隔离功能 |
离线推理 在线推理
离线推理和在线推理都是在线下用数据进行训练,只不过在对新数据进行预测的时候,离线推理是攒一波数据用模型一次预测完存储到表里边,之后线上来的数据直接通过表查询预测的结果,所以如果表里边没有这个数据,那就没有办法预测,但是它对资源的需求低。
在线预测就是来一个线上的数据,我就预测一次,再给线上返回结果。即把训练好的模型放到服务器。所以避免了线上数据没有预测结果的情况。但是耗费资源。
现在流行的是在线学习。模型的训练过程也搬到了线上,线上学习,线上预测。
离线推理:
- 优点:
- 推理成本低
- 可以使用批量方法
- 可以在推送之前对预测进行后期验证
- 缺点:
- 只能对知道的数据进行预测,不适用于存在长尾的情况
- 更新会延迟数小时或者数天
在线推理:
- 优点:
- 适合长尾
- 缺点:
- 计算量大,对延迟敏感,故而限制模型的复杂度
- 监控需求多
现在都是用在线学习
离线推理和在线推理都有不可避免的缺点,但在线学习的实现难度最大。
数据依赖关系
数据对我们的重要性就是传统软件开发中代码对程序员的重要性。
但没有对于数据的单元测试。
模型的好坏取决于输入特征的数据。数据变了,模型也会跟着变。
要不断的测试数据、验证数据、监控数据。
比如:需要移除掉不用或者很少使用的特征。如果一个特征对模型帮助很小,这个特征的输入数据发生了巨变,那么可能会影响到模型。
- 可靠性:
- 数据一直都可以用吗?来源可靠不?(某些数据是不是来自于崩溃的服务器)
版本控制
- 模型是否发生了变化?
- 多久变一次?
- 怎么知道模型发生变化的时间?
必要性
- 这个特征真的值得添加吗?
有时候添加的可以使得模型准确度上升一点的模型除了带来维护负担,添加的特征还可能会意外的失去作用,故而需要监控。
添加有短期收益的特征要慎重。
- 这个特征真的值得添加吗?
相关性
- 特征之间有时候会有相关性,看是否有的特征密不可分,需要采取额外措施。
反馈环
- 模型的结果影响模型的训练数据。
有时候模型的预测结果又会变成自己的训练数据。
有时候一个模型的预测结果会影响另一个模型。
- 模型的结果影响模型的训练数据。
16 现实应用
癌症预测
在癌症预测模型的特征中,含有医院名称,而医院名称和是否患有癌症具有微妙的关系。比如一家肿瘤医院的患者有很大的概率患有癌症。所以模型对这个特征有了很大的权重。
但是在预测新的病人是否患有癌症的时候,缺无法利用此特征。这是很失败的。了解数据所代表的意义,对数据进行合理的拆分
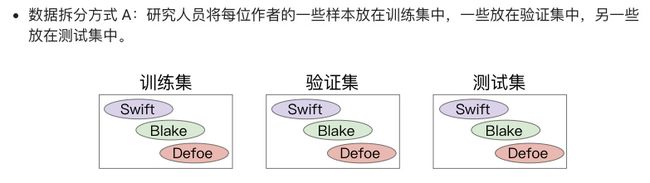
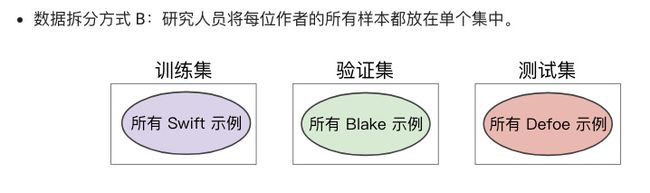
最后A比B的结果好,为什么?
17 机器学习准则
- 确保第一个模型简单易用
- 着重确保数据管道的正确性
- 使用简单、可观测的指标进行训练和验证
- 拥有并监控输入特征
- 将模型配置视为代码,进行审核记录在案
- 记录所有的结果,尤其是失败的结果