MIT JOS LAB4学习笔记
Lab4
Part A: 多处理器支持和协作式多任务
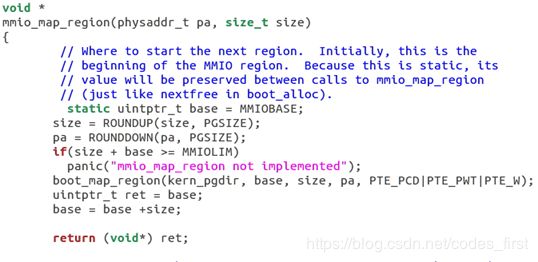
练习 1 :实现在 kern/pmap.c 中的 mmio_map_region 方法。你可以看看 kern/lapic.c 中的 lapic_init 开头部分,了解一下它是如何被调用的。你还需要完成接下来的练习,你的 mmio_map_region 才能够正常运行。
lapic_init()函数的一开始就调用了该函数,将从lapicaddr 开始的4kB物理地址映射到虚拟地址,并返回其起始地址。注意到,它是以页为单位对齐的,每次都映射一个页的大小。

练习 2:阅读 kern/init.c 中的 boot_aps() 和 mp_main() 方法,和 kern/mpentry.S 中的汇编代码。确保你已经明白了引导 AP 启动的控制流执行过程。接着,修改你在 kern/pmap.c 中实现过的 page_init() 以避免将 MPENTRY_PADDR 加入到 free list 中,以使得我们可以安全地将 AP 的引导代码拷贝于这个物理地址并运行。你的代码应当通过我们更新过的 check_page_free_list() 测试,不过可能仍会在我们更新过的 check_kern_pgdir() 测试中失败,我们接下来将解决这个问题。

修改 kern/pmap.c中的page_init()将MPENTRY_PADDR(0x7000)这一页不要加入到page_free_list。

问题 1:逐行比较 kern/mpentry.S 和 boot/boot.S。牢记 kern/mpentry.S 和其他内核代码一样也是被编译和链接在 KERNBASE 之上运行的。那么,MPBOOTPHYS 这个宏定义的目的是什么呢?为什么它在 kern/mpentry.S 中是必要的,但在 boot/boot.S 却不用?换句话说,如果我们忽略掉 kern/mpentry.S 哪里会出现问题呢?
提示:回忆一下我们在 Lab 1 讨论的链接地址和装载地址的不同之处。
1.kern/mpentry.S 与 boot/boot.S 有以下差别:
没有 Enable A20 的部分
GDT 相关的地址都用 MPBOOTPHYS 宏包装了一下
栈设置在了 mpentry_kstack
跳转到入口 mp_main
2.MPBOOTPHYS 宏的作用:
MPBOOTPHYS 的作用是将高地址变为地址。
因为 kern/mpentry.S 都链接到了高位的虚拟地址,但是实际上装载在低位的物理地址,所以 MPBOOTPHYS 要把这个高位的地址映射到低位的地址。boot/boot.S 装载在低位并且链接也在低位,所以就不需要这样的宏。
练习 3:修改位于 kern/pmap.c 中的 mem_init_mp(),将每个CPU堆栈映射在 KSTACKTOP 开始的区域,就像 inc/memlayout.h 中描述的那样。每个堆栈的大小都是 KSTKSIZE 字节,加上 KSTKGAP 字节没有被映射的 守护页 。现在,你的代码应当能够通过我们新的 check_kern_pgdir() 测试了。
对于 CPU i, 、物理地址为 'percpu_kstacks[i]',然后映射过去就行。

练习 4 :位于kern/trap.c 中的 trap_init_percpu() 为 BSP 初始化了 TSS 和 TSS描述符,它在 Lab 3 中可以工作,但是在其他 CPU 上运行时,它是不正确的。修改这段代码使得它能够在所有 CPU 上正确执行。(注意:你的代码不应该再使用全局变量 ts。)
每一个 cpu 的 task state segment (TSS)被用来指定每一个 CPU 的内核栈存在的地方,The TSS for CPU i 储存在 cpus[i].cpu_ts,相应的 TSS descriptor 定义在 gdt[(GD_TSS0 >> 3) + i]。先利用cpu_id建立TSS,初始化TSS descriptor,之后加载TSS selector,最后加载IDT(中断描述符表)。

加锁
你应当在以下 4 个位置使用全局内核锁:
- i386_init() 中,在 BSP 唤醒其他 CPU 之前获得内核锁
- mp_main() 中,在初始化完 AP 后获得内核锁,接着调用 sched_yield() 来开始在这个 AP 上运行进程。
- trap() 中,从用户模式陷入(trap into)内核模式之前获得锁。你可以通过检查 tf_cs 的低位判断这一 trap 发生在用户模式还是内核模式(译者注:Lab 3 中曾经使用过这一检查)
- env_run() 中,恰好在回到用户进程之前释放内核锁。不要太早或太晚做这件事,否则可能会出现竞争或死锁。
练习 5:在上述提到的位置使用内核锁,加锁时使用 lock_kernel(), 释放锁时使用 unlock_kernel()。
Lock_kernel()的函数定义如下:

Unlock_kernel()的函数定义如下:

在kern/spinlock.cpp中,
spin_lock()函数的定义如下:

其中,while循环体现了循环等待的思想,
xchg()函数在inc/x86.h中定义,是一个原子性操作,定义如下:

在kern/init.c下的i386_init()中添加代码如下:
![]()
在kern/init.c下的mp_main()中添加代码如下:

在kern/trap.c下的trap()中添加代码如下:

在kern/env.c下的env_run()中添加代码如下:
![]()
问题 2:看起来使用全局内核锁能够保证同一时段内只有一个 CPU 能够运行内核代码。既然这样,我们为什么还需要为每个 CPU 分配不同的内核堆栈呢?请描述一个即使我们使用了全局内核锁,共享内核堆栈仍会导致错误的情形。
在某进程即将陷入内核态的时候(尚未获得锁),其实在 trap() 函数之前已经在 trapentry.S 中对内核栈进行了操作,压入了寄存器信息。如果共用一个内核栈,就可能会导致信息错误。
轮转调度算法
你的下一个任务是修改 JOS 内核以使其能够以 轮转 的方式在多个进程中切换。JOS 的轮转调度算法像这样工作:
- kern/sched.c 中的 sched_yied() 函数负责挑选一个进程运行。它从刚刚在运行的进程开始,按顺序循环搜索 envs[] 数组(如果从来没有运行过进程,那么就从数组起点开始搜索),选择它遇到的第一个处于 ENV_RUNNABLE (参考inc/env.h)状态的进程,并调用 env_run() 来运行它。
- sched_yield() 绝不应当在两个CPU上同时运行同一进程。它可以分辨出一个进程正在其他CPU(或者就在当前CPU)上运行,因为这样的进程处于 ENV_RUNNING 状态。
- 我们已经为你实现了新的系统调用 sys_yield(),用户进程可以调用它来触发内核的 sched_yield() 方法,自愿放弃 CPU,给其他进程运行。
练习 6:按照以上描述,实现 sched_yield() 轮转算法。不要忘记修改你的 syscall() 将相应的系统调用分发至 sys_yield() (译者注:以后还要添加新的系统调用,同样不要忘记修改 sys_yield())。
确保你在 mp_main 中调用了 sched_yield()。
修改你的 kern/init.c 创建三个或更多进程,运行 user/yield.c。
在kern/sched.c中添加代码如下:

在kern/syscall.c中添加新的系统调用如下:
![]()
在kern/init.c中运行的用户进程修改如下:
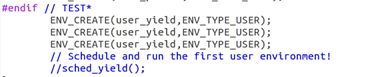
运行 user/yield.c,结果如下:


问题 3:在你实现的 env_run() 中你应当调用了 lcr3()。在调用 lcr3() 之前和之后,你的代码应当都在引用 变量 e,就是 env_run() 所需要的参数。 在装载 %cr3 寄存器之后, MMU 使用的地址上下文立刻发生改变,但是处在之前地址上下文的虚拟地址(比如说 e )却还能够正常工作,为什么?
在env.c的env_settup_vm()中,代码如下:

使用内核的页目录赋值,所以两个页目录的e的地址映射到同一物理地址。
问题 4:无论何时,内核在从一个进程切换到另一个进程时,它应当确保旧的寄存器被保存,以使得以后能够恢复。为什么?在哪里实现的呢?
在进程陷入内核时,会保存当前的运行信息,这些信息都保存在内核栈上。而当从内核态回到用户态时,会恢复之前保存的运行信息。保存发生在 kern/trapentry.S,恢复发生在 kern/env.c env_pop_tf()。
创建其他进程的系统调用
尽管你的内核目前能够运行多个用户进程并在其中切换,但仍受限于只能运行由内核创建的进程。现在,你将实现必要的系统调用,使得用户进程也可以创建和启动其他新的用户进程。
UNIX 提供了 fork() 系统调用作为创建进程的原型,UNIX 的 fork() 拷贝整个调用进程(父进程)的地址空间来创建新的进程(子进程),在用户空间唯一可观察到的区别是它们的 进程ID(process ID) 和 父进程ID(parent process ID)(分别是调用 getpid 和 getppid 返回的)。在父进程中, fork() 返回子进程 ID,但在子进程中,fork() 返回0。默认情况下,每个进程的地址空间是私有的,内存修改对另一方不可见。
你将提供一系列不同的、更原始的系统调用来创建新的用户进程。通过这些系统调用,你将能够完全在用户空间实现类似 Unix 的 fork()作为其他创建进程方式的补充。你将会为 JOS 实现的新的系统调用包括:
sys_exofork:
该系统调用创建一个几乎完全空白的新进程:它的用户地址空间没有内存映射,也不可以运行。这个新的进程拥有和创建它的父进程(调用这一方法的进程)一样的寄存器状态。在父进程中,sys_exofork会返回刚刚创建的新进程的envid_t(或者一个负错误代码,如果进程分配失败)。在子进程中,它应当返回0。(因为子进程开始时被标记为不可运行,sys_exofork 并不会真的返回到子进程,除非父进程显式地将其标记为可以运行以允许子进程运行。
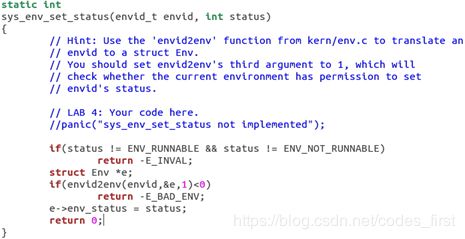
sys_env_set_status:
将一个进程的状态设置为 ENV_RUNNABLE 或 ENV_NOT_RUNNABLE。这个系统调用通常用来在新创建的进程的地址空间和寄存器状态已经初始化完毕后将它标记为就绪状态。
sys_page_alloc:
分配一个物理内存页面,并将它映射在给定进程虚拟地址空间的给定虚拟地址上。
sys_page_map:
从一个进程的地址空间拷贝一个页的映射 (不是页面的内容) 到另一个进程的地址空间,新进程和旧进程的映射应当指向同一个物理内存区域,使两个进程得以共享内存。
sys_page_unmap:
取消给定进程在给定虚拟地址的页映射。
对于所有以上提到的接受 Environment ID 作为参数的系统调用,JOS 内核支持用 0 指代当前进程的惯例。这一惯例在 kern/env.c 的 envid2env() 函数中被实现。
我们在测试程序 user/dumbfork.c 中提供了一种非常原始的 Unix 样式的 fork()。它使用上述系统调用来创建并运行一个子进程,子进程的地址空间就是父进程的拷贝。接着,这两个进程将会通过上一个练习中实现的系统调用 sys_yield 来回切换。 父进程在切换10次后退出,子进程切换20次。
练习 7:在 kern/syscall.c 中实现上面描述的系统调用。你将需要用到在 kern/pmap.c 和 kern/env.c 中定义的多个函数,尤其是 envid2env()。此时,无论何时你调用 envid2env(),都应该传递 1 给 checkperm 参数。确定你检查了每个系统调用参数均合法,否则返回 -E_INVAL。 用 user/dumbfork 来测试你的 JOS 内核,在继续前确定它正常的工作。
在 user/dumbfork.c 中,核心是 duppage() 函数。它利用 sys_page_alloc() 为子进程分配空闲物理页,再使用sys_page_map() 将该新物理页映射到内核 (内核的 env_id = 0) 的交换区 UTEMP,方便在内核态进行 memmove 拷贝操作。在拷贝结束后,利用 sys_page_unmap() 将交换区的映射删除。
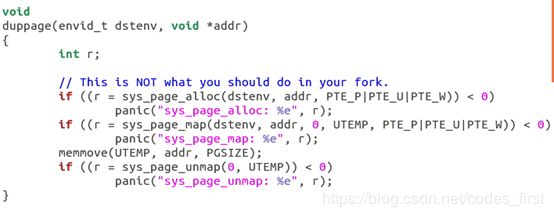
sys_exofork():该函数主要是分配了一个新的进程,但是没有做内存复制等处理。值得注意的就是如何使子进程返回0。
sys_exofork()是一个非常特殊的系统调用,它的定义与实现在 inc/lib.h 中,而不是 lib/syscall.c 中。并且,它必须是 inline 的。

它的返回值是 %eax 寄存器的值。
在kern/syscall.c中,sys_exofork():该系统调用创建一个几乎完全空白的新进程

sys_env_set_status: 用来在新创建的进程的地址空间和寄存器状态已经初始化完毕后将它标记为就绪状态。
sys_page_alloc:分配一个物理内存页面,并将它映射在给定进程虚拟地址空间的给定虚拟地址上。

sys_page_map:从一个进程的地址空间拷贝一个页的映射 (不是页的内容) 到另一个进程的地址空间,新进程和旧进程的映射应当指向同一个物理内存区域,使两个进程得以共享内存。
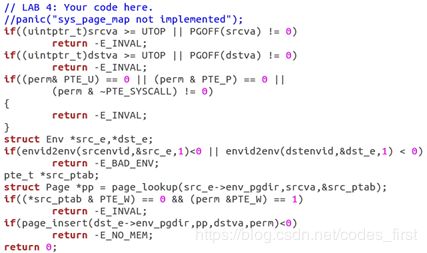
sys_page_unmap:取消给定进程在给定虚拟地址的页映射。

最后,在syscall()中添加代码如下:

运行结果如下:
![]()
Part B: 写时复制的 Fork
设置缺页处理函数
为了处理自己的缺页,用户进程需要向 JOS 内核注册一个 page fault handler entry point。 用户进程通过我们新引入的 sys_env_set_pgfault_upcall 系统调用注册它的缺页处理入口。我们也在 Env 结构体中添加了一个新的成员,env_pgfault_upcall,来记录这一信息
为了实现写时复制,首先要实现用户程序页面错误处理功能。基本流程是:
- 1)用户进程通过 set_pgfault_handler(handler) 设置页面错误处理函数。
- 2)函数set_pgfault_handler中为用户程序分配异常栈,通过系统调用sys_env_set_pgfault_upcall 设置通用的页面错误处理调用入口。
- 3)当用户进程发生页面错误时,陷入内核。内核先判断该进程是否设置了 env_pgfault_upcall,如果没有设置,则报错。如果设置了,则切换用户进程栈到异常栈,设置异常栈内容,然后设置EIP为 env_pgfault_upcall 地址,切回用户态执行 env_pgfault_upcall 函数(即_pgfault_upcall)。
- 4)env_pgfault_upcall作为页面错误处理函数的入口函数,它在用户态运行。先调用步骤1中注册的页面错误处理函数,然后再恢复进程在页面错误之前的栈内容,并切回常规栈,跳转到页面错误之前的地方继续运行。
练习 8:实现 sys_env_set_pgfault_upcall 系统调用。因为这是一个危险的系统调用,不要忘记在获得目标进程信息时启用权限检查。
通过修改相应的struct Env的'env_pgfault_upcall'字段,为'envid'设置页面错误upcall。 当'envid'导致页面错误时,内核会将错误记录推送到异常堆栈,然后转移到'func'。成功时返回0,错误时返回<0。 错误是:-E_BAD_ENV如果环境envid当前不存在,或者调用者没有更改envid的权限。

练习 9:实现在 kern/trap.c 中的 page_fault_handler 方法,使其能够将缺页分发给用户模式缺页处理函数。确认你在写入异常堆栈时已经采取足够的预防措施了。(如果用户进程的异常堆栈已经没有空间了会发生什么?)
首先需要理解用户级别的页错误处理的步骤是:
进程A(正常栈) - >内核 - >进程A(异常栈) - >进程A(正常栈)
page_fault_handler函数的实现方式就是先检查处理函数的地址空间是否存在,如果不存在就应将引发错误的env摧毁掉,否则再判断env运行在用户栈还是异常栈,如果是用户栈就将当前状态压入异常栈,是异常栈就隔一段空位再压栈。
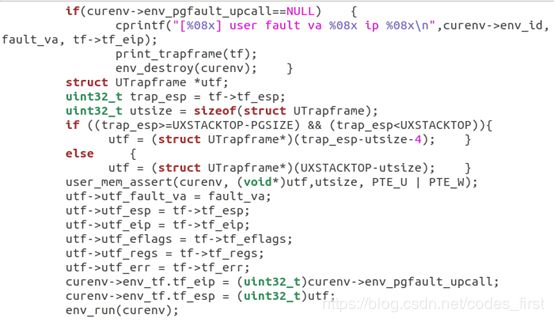
用户模式缺页入口点
接下来,你需要实现汇编例程(routine),来调用 C 语言的缺页处理函数,并从异常状态返回到一开始造成缺页中断的指令继续执行。这个汇编例程 将会成为通过系统调用 sys_env_set_pgfault_upcall() 向内核注册的处理函数。
练习 10:实现在 lib/pfentry.S 中的 _pgfault_upcall 例程。返回到一开始运行造成缺页的用户代码这一部分很有趣。你在这里将会直接返回,而不是通过内核。最难的部分是同时调整堆栈并重新装载 EIP。
运行处理程序,切换回正常栈

练习 11:完成在 lib/pgfault.c 中的 set_pgfault_handler() 。
这是用来指定缺页异常处理方式的函数。需要区分清楚handler,_pgfault_handler,_pgfault_upcall三个变量。
- handler 是传入的用户自定义页错误处理函数指针。
- _pgfault_upcall是一个全局变量,在lib/pfentry.S中完成的初始化。它是页错误处理的总入口,页错误除了运行页面错误处理程序,还需要切换回正常栈。
- _pgfault_handler 被赋值为处理程序,在会_pgfault_upcall中被调用,是页错误处理的一部分
先检查handler 函数是否已被设置过,如果没有就先为handler函数分配一块空间,然后将handler函数设置成自己想要的处理函数。

实现写时复制的 fork
练习 12:实现在 lib/fork.c 中的 fork,duppage和pgfault。 用 forktree 程序来测试你的代码。它应当产生下面的输出,其中夹杂着 new env, free env 和 exiting gracefully 这样的消息。下面的这些输出可能不是按照顺序的,进程ID也可能有所不同:
1000: I am ''
1001: I am '0'
2000: I am '00'
2001: I am '000'
1002: I am '1'
3000: I am '11'
3001: I am '10'
4000: I am '100'
1003: I am '01'
5000: I am '010'
4001: I am '011'
2002: I am '110'
1004: I am '001'
1005: I am '111'
1006: I am '101'
fork() :从主函数 fork() 入手,其大体结构可以仿造 user/dumbfork.c 写,但是有关键几处不同:设置 page fault handler,即 page fault upcall 调用的函数;duppage 的范围不同,fork() 不需要复制内核区域的映射;为子进程设置 page fault upcall,因为 sys_exofork() 并不会复制父进程的 e->env_pgfault_upcall 给子进程。

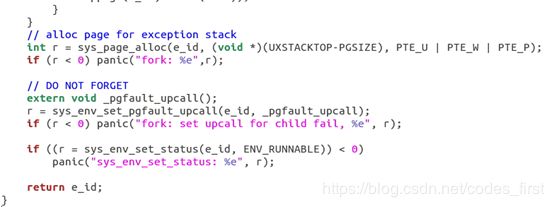
duppage() :复制父、子进程的页面映射。因为sys_page_map() 页面的权限有要求,所以要修正一下权限。

pgfault() :这是 _pgfault_upcall 中调用的页错误处理函数。在调用之前,父子进程的页错误地址都引用同一页物理内存,该函数作用是分配一个物理页面使得两者独立。
首先分配一个页面,映射到交换区 PFTEMP 这个虚拟地址,然后通过 memmove() 函数将 addr 所在页面拷贝至 PFTEMP,此时有两个物理页保存了同样的内容。再将 addr 也映射到 PFTEMP 对应的物理页,最后解除了 PFTEMP 的映射,此时就只有 addr 指向新分配的物理页了,如此就完成了错误处理。


通过 make run-forktree 验证结果。

Part C: 抢占式多任务和进程间通信(IPC)
练习 13:修改 kern/trapenrty.S 和 kern/trap.c 来初始化一个合适的 IDT 入口,并为 IRQ 0-15 提供处理函数。接着修改 在 kern/env.c 中的 env_alloc()以确保用户进程总是在中断被打开的情况下运行。
一些宏定义:

在kern/trapentry.S中加入:
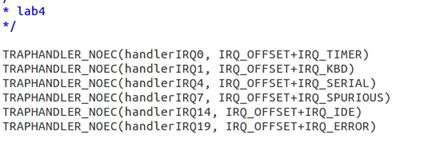
首先声明处理函数,之后使用SETEGATE设置表项。


当调用用户中断处理函数时,处理器从来不会将 error code 压栈,也不会检查IDT 入口的描述符特权等级,所以在trapentry.S中使用TRAPHANDLER_NOEC(),当某个中断发生时,根据偏移量将对应的中断号压栈,然后开始执行相应的中断处理函数(call trap):
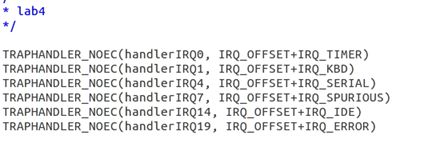
确保用户进程总是在中断被打开的情况下运行,保证 FL_IF 被置位,如果这个进程运行时出现中断,中断就可以到达处理器并被相应的中断处理代码所处理。所以在kern/env.c的env_alloc()中加入:
![]()
练习 14:修改内核的 trap_dispatch() 函数,使得其每当收到时钟中断的时候,它会调用 sched_yield() 寻找另一个进程并运行。
添加时钟中断的分支:

进程间通信 (IPC)
练习 15:实现 kern/syscall.c 中的 sys_ipc_recv 和 sys_ipc_try_send。在实现它们前,你应当读读两边的注释,因为它们协同工作。当你在这些例程中调用 envid2env 时,你应当将 `checkperm 设置为 0,这意味着进程可以与任何其他进程通信,内核除了确保目标进程ID有效之外,不会做其他任何检查。
接下来在 lib/ipc.c 中实现 ipc_recv 和 ipc_send。
sys_ipc_recv(void *dstva) :
功能:将当前进程挂起,放弃CPU,准备接受其他进程发来的消息
实现方式:设置env_ipc_recving、env_ipc_dstva、env_status,执行系统调用sys_yield()

sys_ipc_try_send(envid_t envid, uint32_t value, void *srcva, unsigned perm):
功能:试着发送消息,目标进程的id不存在、目标进程未开始接受、传递的页映射有问题 等原因都会导致发送失败。若发送成功,则更新目标进程,使其变为就绪态,不再接受消息。
实现方式:先判断发送的条件是否全满足,若都满足,更新目标进程的env_ipc_recving、enc_ipc_from、env_ipc_value等
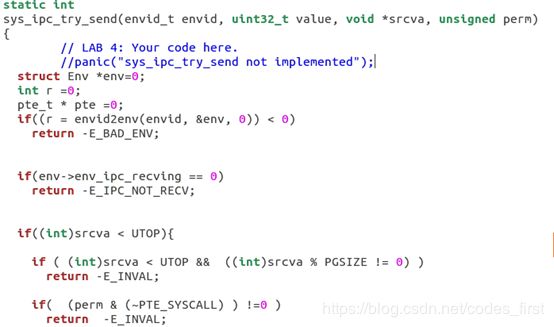

然后在kern/syscall.c中添加新的系统调用如下:

ipc_recv(envid_t *from_env_store, void *pg, int *perm_store):
功能:接受发送者发来的value并返回它,获取发送进程的id,页权限
实现方式:执行系统调用,挂起当前进程,如果接收者想要共享页(pg非空),则将接收方共享页的虚拟地址设为pg,准备接收,修改from_env_store、perm_store
(如果发送者发来了共享页,perm_store和发送者的相同;发送者未发送页,则perm_store=0,权限为内核)

ipc_send(envid_t to_env, uint32_t val, void *pg, int perm):
功能:向目标进程发送value和内存页(如果pg非空)
实现方式:循环调用sys_ipc_try_send(),直到发送成功,同时调用sys_yield(),避免一直占用CPU,像spin一样被kill。

测试:
make run-pingpong
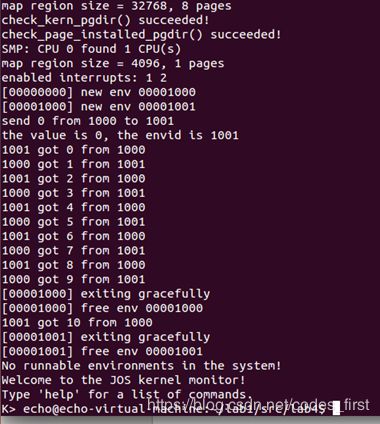
make grade:
