交叉熵、相对熵及KL散度通俗理解
原文转载自http://blog.csdn.net/u012162613/article/details/44239919
本文是《Neural networks and deep learning》概览 中第三章的一部分,讲machine learning算法中用得很多的交叉熵代价函数。
1. 从方差代价函数说起
代价函数经常用方差代价函数(即采用均方误差MSE),比如对于一个神经元(单输入单输出,sigmoid函数),定义其代价函数为:
其中y是我们期望的输出,a为神经元的实际输出【 a=σ(z), where z=wx+b 】。
在训练神经网络过程中,我们通过梯度下降算法来更新w和b,因此需要计算代价函数对w和b的导数:
然后更新w、b:
w <—— w - η* ∂C/∂w = w - η * a *σ′(z)
b <—— b - η* ∂C/∂b = b - η * a * σ′(z)
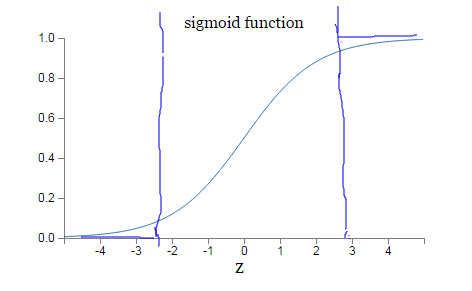
因为sigmoid函数的性质,导致σ′(z)在z取大部分值时会很小(如下图标出来的两端,几近于平坦),这样会使得w和b更新非常慢(因为η * a * σ′(z)这一项接近于0)。
2. 交叉熵代价函数(cross-entropy cost function)
为了克服这个缺点,引入了交叉熵代价函数(下面的公式对应一个神经元,多输入单输出):
其中y为期望的输出,a为神经元实际输出【a=σ(z), where z=∑Wj*Xj+b】
与方差代价函数一样,交叉熵代价函数同样有两个性质:
- 非负性。(所以我们的目标就是最小化代价函数)
- 当真实输出a与期望输出y接近的时候,代价函数接近于0.(比如y=0,a~0;y=1,a~1时,代价函数都接近0)。
另外,它可以克服方差代价函数更新权重过慢的问题。我们同样看看它的导数:
可以看到,导数中没有σ′(z)这一项,权重的更新是受σ(z)−y这一项影响,即受误差的影响。所以当误差大的时候,权重更新就快,当误差小的时候,权重的更新就慢。这是一个很好的性质。
3. 总结
- 当我们用sigmoid函数作为神经元的激活函数时,最好使用交叉熵代价函数来替代方差代价函数,以避免训练过程太慢。
- 不过,你也许会问,为什么是交叉熵函数?导数中不带σ′(z)项的函数有无数种,怎么就想到用交叉熵函数?这自然是有来头的,更深入的讨论就不写了,少年请自行了解。
- 另外,交叉熵函数的形式是−[ylna+(1−y)ln(1−a)]而不是 −[alny+(1−a)ln(1−y)],为什么?因为当期望输出的y=0时,lny没有意义;当期望y=1时,ln(1-y)没有意义。而因为a是sigmoid函数的实际输出,永远不会等于0或1,只会无限接近于0或者1,因此不存在这个问题。
4. 还要说说:log-likelihood cost
对数似然函数也常用来作为softmax回归的代价函数,在上面的讨论中,我们最后一层(也就是输出)是通过sigmoid函数,因此采用了交叉熵代价函数。而深度学习中更普遍的做法是将softmax作为最后一层,此时常用的是代价函数是log-likelihood cost。
In fact, it’s useful to think of a softmax output layer with log-likelihood cost as being quite similar to a sigmoid output layer with cross-entropy cost。
其实这两者是一致的,logistic回归用的就是sigmoid函数,softmax回归是logistic回归的多类别推广。log-likelihood代价函数在二类别时就可以化简为交叉熵代价函数的形式。具体可以参考UFLDL教程
5. 熵与KL散度
链接:https://www.zhihu.com/question/41252833/answer/108777563
熵的本质是香农信息量 (log1p ) 的期望。
现有关于样本集的2个概率分布p和q,其中p为真实分布,q非真实分布。按照真实分布p来衡量识别一个样本的所需要的编码长度的期望(即平均编码长度)为: H(p)=∑ i p(i)∗log1p(i) ,如果使用错误分布q来表示来自真实分布p的平均编码长度,则应该是: H(p,q)=∑ i p(i)∗log1q(i) 。 因为用q来编码的样本来自分布p,所以期望H(p,q)中概率是p(i)。H(p,q)我们称之为“交叉熵”。
比如含有4个字母(A,B,C,D)的数据集中,真实分布p=(1/2, 1/2, 0, 0),即A和B出现的概率均为1/2,C和D出现的概率都为0。计算H(p)为1,即只需要1位编码即可识别A和B。如果使用分布Q=(1/4, 1/4, 1/4, 1/4)来编码则得到H(p,q)=2,即需要2位编码来识别A和B(当然还有C和D,尽管C和D并不会出现,因为真实分布p中C和D出现的概率为0,这里就钦定概率为0的事件不会发生啦)。
可以看到上例中根据非真实分布q得到的平均编码长度H(p,q)大于根据真实分布p得到的平均编码长度H(p)。事实上,根据Gibbs’ inequality可知,H(p,q)>=H(p)恒成立,当q为真实分布p时取等号。我们将由q得到的平均编码长度比由p得到的平均编码长度多出的bit数称为“相对熵”: D(p||q)=H(p,q)−H(p)=∑ i p(i)∗logp(i)q(i) , 其又被称为KL散度(Kullback–Leibler divergence,KLD) Kullback–Leibler divergence。它表示2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小,特别地,若2者相同则熵为0。注意,KL散度的非对称性。
比如TD-IDF算法就可以理解为相对熵的应用:词频在整个语料库的分布与词频在具体文档中分布之间的差异性。
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
PS:通常“相对熵”也可称为“交叉熵”,因为真实分布p是固定的,D(p||q)由H(p,q)决定。当然也有特殊情况,彼时2者须区别对待。
注:转载的这篇博文对于信息熵的举列子里,信息熵的求解中对数是以2为底的,即是 log 2 。
关于信息熵和相对熵这个问题,知乎上ID为CyberRep的答主答的挺好,链接:https://www.zhihu.com/question/41252833
参考:
转自:https://zhuanlan.zhihu.com/p/29321631