目标检测算法trident network引发的思考
文章目录
- 1 SNIP
- 2 Trident network
- 2.1 动机
- 2.2 感受野和目标尺寸的关系
- 2.3 网络结构
- 2.3.1 SPP
- 2.3.2 ASPP
- 2.3.3 RFB net
- 3 总结
- 4 参考资料
最新的目标检测算法“Trident Network”,单模型的mAP刷到了48.4,的确是“state-of-the-art”。笔者看了论文作者Naiyan Wang的知乎解读,感觉解释的很深刻,然后看了同行们的评论,比如有人说怎么和ASPP、SPP、SNIP、RFB-net等很像啊,包括我的帅帅同事。笔者是没有发言权的,因为除了SNIP比较熟悉之外(见上一篇博文),其它的几篇文章不怎么了解。为了弄清楚它们之间的异同,笔者对比着阅读了这几篇文章,有了一些自己的思考,故在这里记录下来,希望能对大家有所帮助。
1 SNIP
本文的主角Trident Network借鉴了这篇文章中的multi-scale思想,所以有必要先梳理一下SNIP中如何做目标检测。网络结构图如下,
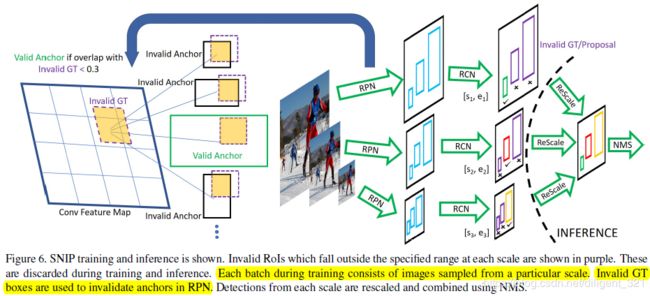
图像信号的前向传播过程包括:图像金字塔 -> 多分支特征提取 -> 分支融合 -> NMS后处理,每部分完成的功能汇总如下,
输入数据:采用图像金字塔对原图做分解,这里使用了3层金字塔。
多分支特征提取(训练阶段):(1)从功能上来讲,对每一层金字塔图像,分别检测不同尺寸的目标,金字塔图像越大,检测的目标尺寸越小;(2)从网络结构上来讲,3个分支进行参数共享,故网络结构完全一致,区别在于目标尺寸的超参数不同。
分支融合(推理阶段):合并不同分支的结果。
NMS后处理:对融合后的预测框做筛选。
缺点:推理阶段需要先生成图像金字塔,然后每一中分辨率的图像过一遍inference过程,所以比较耗时。
关于这篇论文的详细解释,请参见笔者的上一篇博文https://blog.csdn.net/diligent_321/article/details/86495360。
2 Trident network
Trident network,翻译过来就是“三叉戟网络”,该论文的全称为“Scale-Aware Trident Networks for Object Detection”。
2.1 动机
检测任务中存在目标尺寸多样化的问题,为了解决这一问题,涌现了很多经典算法,笔者将部分算法汇总如下,
| 算法名称 | 优缺点 |
|---|---|
| SSD | 优点:速度快; 缺点:因为bottom layers缺少语义信息,只使用upper layers预测目标。而小目标是靠bottom layer预测的,所以SSD对小目标效果差。 |
| FPN | 优点:弥补SSD的bottom layers缺少语义信息的不足,引入了top-down connection,所以对小目标效果有改善; 缺点:bottom layer提取小目标的特征,upper layer提取大目标的特征,导致大目标和小目标的特征的“表达能力”不同,因此算法对大目标和小目标的检测效果不同,这里的“表达能力”指特征所包含的语义信息和细节信息。 |
| SNIP | 优点:精度高; 缺点:采用了图像金字塔,推理速度慢(复杂度为 O ( N 2 ) O(N^{2}) O(N2),比如将原图长宽各放大2倍,则新图像inference计算量为原图的4倍)。 |
总体上来看,作者采用的做法如下,(1)为了使模型对不同尺寸目标的“表达能力”近似,作者借鉴了SNIP的特征提取网络,采用了“scale-aware”的并行结构;(2)为了加快模型的推理速度,作者采用了dilated convolution得到不同感受野的特征图,从而实现检测不同尺度目标的目的,取代了SNIP中的特征金字塔生成不同尺度目标的做法,笔者认为这一点是最大的创新。下面具体讲述这两块的细节,大家感兴趣可以接着往下阅读。
2.2 感受野和目标尺寸的关系
作者在论文第3部分研究了感受野和目标尺寸的关系,所做的实验结果如下表,
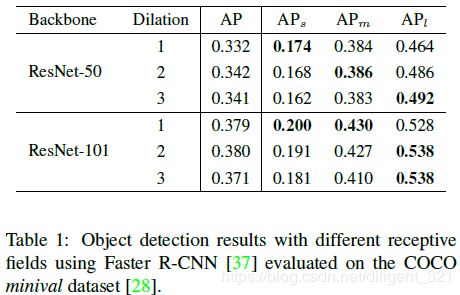
其中, A P s 、 A P m 、 A P l AP_{s}、AP_{m}、AP_{l} APs、APm、APl分别表示small、middle、large目标的AP值。显然,Dilation系数越大,特征对应的感受野越大,对应的目标尺寸越大,大体上呈正相关关系。
ps:这个结论从直觉上来说是可以理解的,因为感受野大小和目标尺寸越接近,越容易回归出检测框。
2.3 网络结构
Trident network的网络结构如下,显然,叫做“三叉戟网络”就名副其实了。由图中可以看出,三个分支从上到下对应的Dilation系数逐渐增大,因此对应的目标尺寸也逐渐增大。即第一个分支用来检测小目标,第二个分支用来检测中等目标,第三个分支用来检测大目标,这种设计方法和2.2部分是一致的。
由于不同分支的网络结构完全相同,仅仅Dilation系数这个超参数不同,作者令三个分支参数共享了。
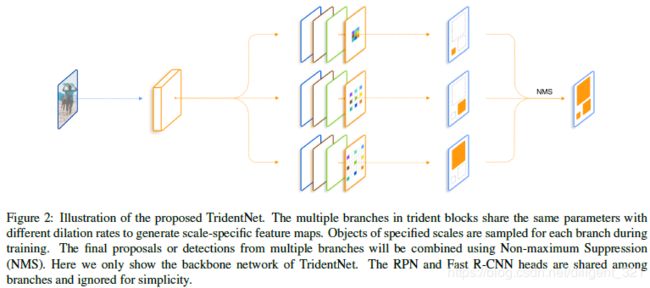 整个网络的训练方式和SNIP基本相同,每个batch包含单一尺度的目标,区别在于SNIP使用了特征金字塔获取不同尺度的目标,用来训练某一个分支,而Trident network直接基于原始数据集中的同一尺度的目标,训练某一个分支。
整个网络的训练方式和SNIP基本相同,每个batch包含单一尺度的目标,区别在于SNIP使用了特征金字塔获取不同尺度的目标,用来训练某一个分支,而Trident network直接基于原始数据集中的同一尺度的目标,训练某一个分支。
大家咋一看可能会觉得,咦,Trident network和其它的一些网络结构很相似,明显创新性不足啊。笔者刚开始也是这么觉得的,但是细细想了之后,发现区别还是挺大的,下面笔者解释它们之间的差异性。
2.3.1 SPP
这篇论文的全称为“Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition”,是何恺明在2014年提出的一种用于解决图像分类的网络框架,其中的SPP模块如下图,

这里采用了三分支的网络结构,每个分支将输入特征图池化成固定尺寸,(ps:大家是不是联想到了faster rcnn中的roi pooling操作,是的,目的是完全一样的,都是为了align输入特征图的维度),然后将不同分支的特征做concate操作,因此网络的输入可以处理不同尺寸的图像了。
总结一下与Trident 的区别:(1)SPP的多分支结构应用于图像分类任务,每个分支的作用和Trident 不同;(2)三个分支的特征最终需要使用concate操作做融合,用于预测输入图像的标签,而Trident 的三个分支的结果是独立的。
2.3.2 ASPP
ASPP的全称为“Atrous Spatial Pyramid Pooling”,它是在DeepLabv2中提出来的,ASPP的网络结构如下图,

这里也使用了多分支的dilation convolution操作,用于提取不同感受野的特征。ASPP中不同分支的特征图,需要使用双线性插值算法上采样达到跟输入图相同的尺寸,然后采用逐像素max pooling策略做特征图的融合,从而得到分隔后的图像。
总结一下与Trident 的区别:(1)用途不同,ASPP的三个分支的特征最终需要使用max pooling操作做融合,用于预测每个像素的标签,而Trident 的三个分支的结果是独立的。
2.3.3 RFB net
RFB net,它的全称为“Receptive Field Block Net for Accurate and Fast Object Detection”,整个的目标检测思路是基于SSD算法框架,如下图,

它的改进之处为:引入了感受野模块,简称为RFB,它的结构如下图,显然,该结构类似于Googlenet中的Inception module,不同分支使用了不同的卷积滤波器,RFB的目的是提取特征图上更加丰富的特征。
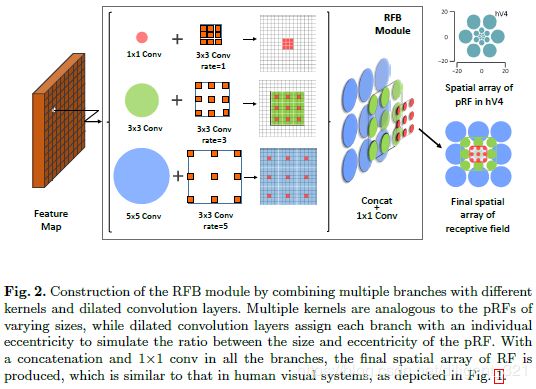
总结一下与Trident 的区别:(1)目的不同。RFB虽然也采用了三分支的结构,且每个分支用到了不同dilation系数的卷积操作,但是最终需要使用concate操作融合这3个分支得到的特征,也即从输入Feature Map中提取更强表达能力的特征。而Trident network的不同分支用于提取输入Feature Map中不同尺寸目标的更强表达能力的特征。
3 总结
同是为了解决目标检测中的多尺度问题,不同的方法采用的思想不同,笔者将其总结如下
(1)SNIP采用了图像金字塔构造多尺度特征,然后用单分支网络学习更深层特征(多输入+单分支);
(2)FPN采用了单一图像作为输入,且使用级联多分支学习输入图像的不同尺度的目标的特征(单输入+级联多分支);
(3)Trident network采用了单一图像作为输入,且使用并行多分支学习输入图像的不同尺度的目标的特征(单输入+并行多分支);
4 参考资料
https://zhuanlan.zhihu.com/p/54334986
https://arxiv.org/abs/1711.08189
https://arxiv.org/abs/1406.4729
https://arxiv.org/abs/1606.00915
https://arxiv.org/abs/1711.07767