ucore lab3 操作系统实验
LAB3实验报告
知识准备
(主要依据理论课知识以及学堂在线上清华大学教学视频)
1.虚拟存储的相关概念:
虚拟存储是一种内存管理技术指的是在非连续内存分配的基础上,将一部分内容放到外存里的做法,从而可以使在内存中保留更多进程并且可以允许进程比主存的全部空间还大。
虚拟存储的需求背景:
程序规模的增长速度远大于存储器容量发展速度,导致系统时常出现内存不够用的情况。
我们想拥有有容量更大、速度更快、价格更便宜的非易失性存储器,但根据储存器的层次结构我们知道,容量大的存储器访问速度就慢,访问速度快的存储器价格就比较昂贵。因此需要用一种技术使这些存储器的搭配处于合理状态,使得既满足容量与速度需求,又尽可能低成本。
交换与覆盖技术
覆盖技术是指依据程序的逻辑结构,将程序划分为若干个功能相对独立的模块,将不会同时执行的模块可以共享同一块内存,按时间先后运行。可以将常用功能的代码和数据常驻内存,不常用功能的代码数据放在其他程序模块中,只在需要使用时将其装入内存。交换技术可以实现允许进程内存比主存全部空间还大的情况。但覆盖技术增大了程序编程的复杂性,程序的设计开销大大增加,本质上是一种以时间换空间的策略。
交换技术可以增加正在运行或者需要运行的程序的内存,实现方法为将暂时不运行的程序放到外存。通常使用于内存空间不够或者很可能不够的情况,交换区大小的设置应当满足可以存访所有用户进程的所有内存映像的拷贝;当然,通过采用动态地址映射的方法,当程序再次换入时不需要一定放置在原地址。
覆盖发生在运行程序的内部模块间,只能发生于没有调用关系的模块间。而交换是以进程为单位,发生在内存的进程之间。
局部性原理
程序在执行过程中的一个较短时期,所执行的指令地址和指令的操作数地址,分别局限于一定区域。
时间局部性:一条指令的一次执行和下次执行,一个数据的一次访问和下次访问都集中在一个较短时期内。
空间局部性:当前指令和临近的几条指令,当前访问的数据和临近的几个数据都集中在一个较小范围内。
分支局部性:一条跳转指令的两次执行,很可能跳到相同的内存位置。
因此根据程序局部性原理,我们认为程序所执行的指令以及访问的数据都有很好的集中特征,因此如果知道这些局部区域的位置,将其放入内存,将别的不常用的放在外存中,这样可以使得系统不会因为频繁的内存与外存间的换入换出导致性能大幅度下降。
虚拟存储的实现
思路:将不常用的部分内存块暂存到外存中
原理:装载程序时,只将当前指令执行所需要的部分页面或段装入内存;指令执行中发生缺页或者缺段时,操作系统将相应的页或段调入内存;操作系统将内存中暂时不用的页或段保存到外存。
实现方式:虚拟页式管理和虚拟段式管理
虚拟页式存储
将每次交换的单位设置为页即可。实现方式为在页式存储管理的基础上,增加请求调页和页面置换算法。
思路:当程序要装载到内存运行时,只装入部分页面,就启动程序运行。程序在运行中发生代码或数据不在内存时,则向系统发出缺页异常请求。操作系统处理缺页异常时,将外存中相应的页面调入内存使进程可以继续运行。
虚拟页式存储中的页表项结构: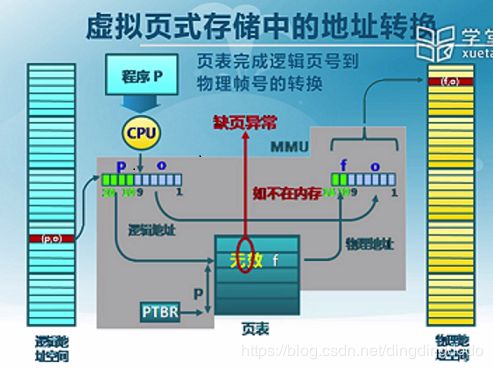
逻辑地址通过页表转换到物理地址对应的帧,加上偏移量即可找到正确的物理地址空间。
当页表中发现要访问的页不在内存时,引发缺页异常,操作系统将调度一个磁盘操作将要访问的外存中的页调度到内存中的帧,并刷新页表,然后重新执行该指令。
具体页表项的组成(增添了一些标记位):
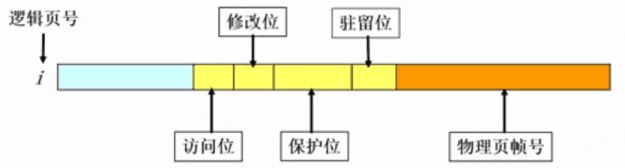
- 驻留位:表示该页是否在内存(1表示在该页内存,该页有效可以访问;0表示该页在外存,访问该页会引发缺页异常)
- 修改位:表示在内存中的该页是否被修改过(用于回收该物理页时,判断是否需要将其内容写回外存)
- 访问位:表示该页面是否被访问过(主要用于页面置换算法)
- 保护位: 表示该页的允许访问方式(可读?可写?可执行?等)
缺页异常处理
发生缺页异常,操作系统将调度一个磁盘操作将要访问的外存中的页调度到内存中的帧,并刷新页表,然后重新执行该指令。 如下:
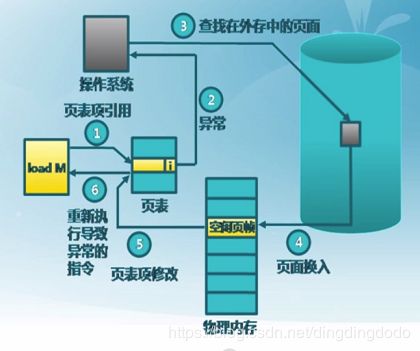
如果内存中有空闲的物理页面,则直接分配一个空闲物理帧即可。否则需要根据页面置换算法选择被替换的物理页帧以及对应的逻辑页,根据逻辑页的修改位判断该页是否被修改过,如果修改过需要将其写回外存。之后将这个逻辑页的驻留位置为0。将要访问的页装入给其分配的物理页帧,修改其驻留位为1并修改相应的物理页帧号。最后重新执行该指令。
虚拟页式存储管理的性能:
EAT(有效访问时间)=访存时间*(1-p)+缺页异常处理时间 *缺页率p
2.页面置换算法
当出现缺页异常时,需要调入新页面而内存已满时,置换算法来选择被置换的物理页面。置换算法的设计目标是尽可能减少页面的换入换出次数,把未来不再访问或短期不访问的页面调出。页面置换算法通常分为局部页面置换算法和全局页面置换算法,局部置换算法的置换页面的选择范围仅限于当前进程占用的物理页面内,全局置换算法的置换页面的选择范围是所有可换出的物理页面。
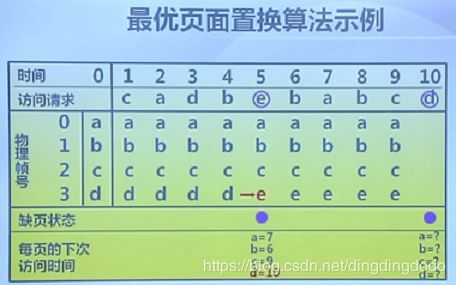
最优页面置换算法(OPT)
当需要调入一页必须淘汰一个旧页时,置换的页是以后不会访问或最长时间不会使用的页。该算法是最优的算法,缺页最少,但是是理想情况下的算法,由于不能预测之后要访问的页以及每个页面距离下次访问的时间,故操作系统是不能实现的,但通常作为一个标准衡量别的算法的性能。下面是一个例子(理解下面这个过程即可):
先进先出算法(FIFO)
当需要调入一页必须淘汰一个旧页时,总是淘汰最先调入内存的那一页,或者说在主存中驻留时间最长的那一页。该算法实现较为简单,只需要维护一个位于所有内存中的逻辑页面链表,链表元素按照驻留时间排序,链首最长,如果出现缺页时将链首页面进行置换,新页面加到链尾即可。但是该算法性能较差,可能会将经常调用的页面调出,可能导致Belady异常(页错误率可能会随着所分配的帧数的增加而增加)。下面是一个例子(理解该例子即可):
最近最少使用算法(LRU)
当需要调入一页必须淘汰一个旧页时,总是淘汰最近一段时间内最长没有被引用的页面进行置换。根据程序局部性原理,那些刚被使用过的页面,可能马上还要被使用,而较长时间里没有使用的页面,可能不会马上使用到。实现:当发生缺页时,计算内存中每个逻辑页面的上一次访问时间,选择上一次使用到当前时间最长的页面。具体实现时候可以维护一个按最近一次访问时间排序的页面链表,链表首节点是最近刚使用过的页面,尾节点是最久未使用的页面,访问内存时,找到相应的页面并把它移到链首,缺页时置换链表尾节点的页面。
可以认为这是最优置换算法的一种近似,算法性能较好,但实现非常复杂。下面是一个例子:

时钟置换算法
当需要调入一页必须淘汰一个旧页时,淘汰最近的时间段没有访问的页面。可以认为是FIFO与LRU的一种折中方案,考虑之前的访问情况,但不是考虑之前所有的访问情况。通过对过去一段时间页面的访问情况进行统计即可,为了实现该算法,通常在页表项中增加访问位,当装入内存时,访问位初始化为0,访问页面时访问位置为1;且各页面组织成环形链表,指针总是指向最先调入的页。访问页面时,在页表项记录页面访问情况;缺页时,从指针处开始顺序查找未被访问的页面进行置换,访问位为0的话置换该页,如果为1向下继续找。例子:
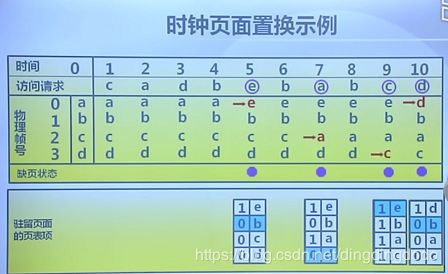
最不常用算法
当需要调入一页必须淘汰一个旧页时,淘汰最近访问次数最少的页。实现:每个页面设置一个页面计数,访问页面时访问次数加1,缺页时只需要置换计数最小的页面。例子: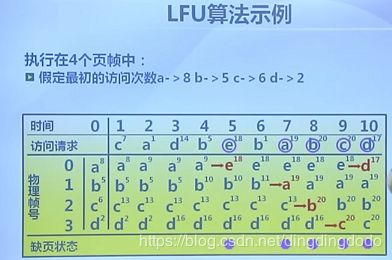
实验过程
进行实验之前,我们查看一些lab3新增的一些重要的数据结构和函数:
查看vmm.h可知有两个重要的数据结构vma_struct和mm_struct,描述了ucore模拟应用程序运行所需的合法内存空间 。当访问内存产生page fault异常时,可获得访问的内存的方式(读或写)以及具体的虚拟内存地址,从而ucore就可以查询此地址,看是否属于vma_struct数据结构中描述的合法地址范围中,如果在,则可根据具体情况进行请求调页/页换入换出处理;如果不在,则报错。代码介绍:
vma_struct是用来描述应用程序对虚拟内存“需求”的数据结构:
//虚拟内存空间
struct vma_struct
{
//虚拟内存空间属于的进程
struct mm_struct *vm_mm;
//描述了一个连续地址的虚拟内存空间的起始位置和结束位置,这两个值都应该是PGSIZE 对齐的,
//而且描述的是一个合理的地址空间范围(即严格确保 vm_start < vm_end的关系
uintptr_t vm_start;
uintptr_t vm_end;
//虚拟空间的属性(读/写/可执行)
uint32_t vm_flags;
//双向链表,从小到大将虚拟内存空间连起来
list_entry_t list_link;
};
//需要说明的是vm_flags表示虚拟内存空间属性,共三种:
#define VM_READ 0x00000001 //只读
#define VM_WRITE 0x00000002 //可读写
#define VM_EXEC 0x00000004 //可执行
mm_struct则更像是一个包含所有虚拟内存空间的共同属性的结构体:
//描述一个进程的虚拟地址空间,每个进程的pcb有一个指针指向该结构体
struct mm_struct {
//双向链表头,链接了所有属于同一页目录表的虚拟内存空间
list_entry_t mmap_list; // linear list link which sorted by start addr of vma
//指向当前正在使用的虚拟内存空间,
struct vma_struct *mmap_cache; // current accessed vma, used for speed purpose
//mm_struct数据结构所维护的页表
pde_t *pgdir; // the PDT of these vma
//记录mmap_list 里面链接的 vma_struct的个数
int map_count; // the count of these vma
//指向用来链接记录页访问情况的链表头(用于置换算法)
void *sm_priv; // the private data for swap manager
};
//补充:
//mmap_cache变量可以使程序更好地利用操作系统执行的“局部性”原理,现阶段使用地虚拟内存空间接下来很可能还用到,所以如果直接用到地话直接调用mmap_cache将很好地提高效率。
//通过访问pgdir可以查找某虚拟地址对应的页表项是否存在以及页表项的属性
与vma_struct和mm_struct相关的函数:(仅对函数作用做介绍,不介绍具体实现)
//创一个mm_struct并初始化,(创建时调用了kmalloc,故删除前需要释放)
struct mm_struct *mm_create(void)
// vma的创建并初始化,根据参数vm_start、vm_end、vm_flags完成初始化
struct vma_struct *vma_create(uintptr_t vm_start, uintptr_t vm_end, uint32_t vm_flags)
//根据mm以及addr找到vma ,找到的vma满足(vma->vm_start <= addr <= vma_vm_end)
struct vma_struct *find_vma(struct mm_struct *mm, uintptr_t addr)
//在这里具体实现函数时,每次首先判断mmap_cache所指的虚拟内存空间是否为所找,如果不是则从头开始寻找。
//这里便是对mmap_cache利用局部性原理的很好例子!
//向mm的mmap_list的插入一个vma,按地址插入合适位置
void insert_vma_struct(struct mm_struct *mm, struct vma_struct *vma)
//删除一个mm struct,kfree掉占用的空间
void mm_destroy(struct mm_struct *mm)
在lab3中,为了实现虚拟内存管理,lab2中的Page结构体进行了改进:
struct Page {
int ref; // page frame's reference counter
uint32_t flags; // array of flags that describe the status of the page frame
unsigned int property; // the num of free block, used in first fit pm manager
list_entry_t page_link; // free list link
//增添了两个变量:pra_page_link以及pra_vaddr,用于页替换算法
list_entry_t pra_page_link; // used for pra (page replace algorithm)
uintptr_t pra_vaddr; // used for pra (page replace algorithm)
};
练习1:给未被映射的地址映射上物理页(需要编程)
完成do_pgfault(mm/vmm.c)函数,给未被映射的地址映射上物理页。设置访问权限 的时候需要参考页面所在 VMA 的权限,同时需要注意映射物理页时需要操作内存控制 结构所指定的页表,而不是内核的页表。注意:在LAB2 EXERCISE 1处填写代码。执行
make qemu
后,如果通过check_pgfault函数的测试后,会有“check_pgfault() succeeded!”的输出,表示练习1基本正确。请在实验报告中简要说明你的设计实现过程。
实现:
页访问机制的实现:
当启动分页机制以后,如果一条指令或数据的虚拟地址所对应的物理页框不在内存中或者访问的类型有错误,就会发生 页错误异常。产生页面异常的原因主要有:
- 目标页面不存在(页表项全为0,即该线性地址与物理地址尚未建立映射或者已经撤销);
- 相应的物理页面不在内存中(页表项非空,但Present标志位=0,比如在swap分区或磁盘文件上)
- 访问权限不符合(此时页表项P标志=1,比如企图写只读页面)
页访问异常,需要做的事情:
- 页访问异常会将产生页访问异常的线性地址存入 cr2 寄存器中,并且给出错误码 error_code 说明是页访问异常的具体原因
- uCore OS 会将其存入 struct trapframe中tf_err,等到中断服务例程调用页访问异常处理函数(do_pgfault()) 时,再判断具体原因
- 若不在某个VMA的地址范围内 或 不满足正确的读写权限 则是非法访问
- 若在此范围且权限也正确,则认为是合法访问,只是没有建立虚实对应关系,应分配一页并修改页表,完成虚拟地址到物理地址的映射,刷新TLB,最后再调用iret 重新执行引发页访问异常的那条指令
- 若是在外存中,则将其换入内存刷新TLB, 然后退出中断服务例程,重新执行引发页访问异常的那条指令
产生页访问异常后,CPU把引起页访问异常的线性地址装到寄存器CR2中,并给出了出错码errorCode,说明了页访问异常的类型。ucore OS会把这个值保存在struct trapframe 中tf_err成员变量中。而中断服务例程会调用页访问异常处理函数do_pgfault进行具体处理。
do_pgfault函数主要是对page fault进行处理,查看do_pgfault函数以及相关注释可知:
该函数有三个参数,第一个是一个mm_struct变量,该变量保存了所使用的PDT,合法的虚拟地址空间(使用链表组织),以及与后文的swap机制相关的数据;而第二个参数是产生page fault的时候硬件产生的error code,用于帮助判断发生page fault的原因;第三个参数则是出现page fault的线性地址(保存在cr2寄存器中的线性地址)。
该函数实现时,先查询mm_struct中的合法的虚拟地址链表,用于确定当前出现page fault的线性地址是否合法,如果合法则继续执行调出物理页,否则直接返回;接下来根据error code判断是否出现了越权行为(包括:读取没有读权限的内存、写没有写权限的内存、所读内容在内存中却读失败等);之后根据合法虚拟地址产生对应物理页权限;如果页表项为0,说明尚未分配物理页,这里便是该练习所要完成的内容:
通过函数get_pte来获取出错的线性地址对应的虚拟页起始地址对应到的页表项,如果所需物理页没有被分配,则利用pgdir_alloc_page函数分配物理页。
具体code:
/*LAB3 EXERCISE 1: YOUR CODE*/
// 获取当前发生缺页的虚拟页对应的PTE
ptep = get_pte(mm->pgdir,addr,1);
struct Page *page = NULL;
if (*ptep == 0) // 如果需要的物理页是没有分配而不是被换出到外存中
{
// 分配物理页,并且与对应的虚拟页建立映射关系
page = pgdir_alloc_page(mm->pgdir,addr,perm);
if (page == NULL)
{
//模仿上面的代码,进行报错提示
cprintf("pgdir_alloc_page in do_pgfault failed\n");
goto failed;
}
}
else
{
/*LAB3 EXERCISE 2: YOUR CODE */
}
......
查看make qemu结果:
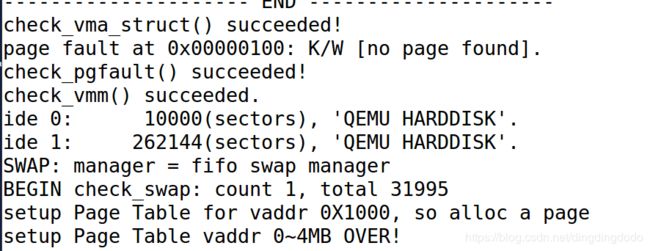
可知实现正确。
请回答如下问题:
-
请描述页目录项(Pag Director Entry)和页表(Page Table Entry)中组成部分对ucore实现页替换算法的潜在用处。
首先我们查看PTE的组成部分(在vs上搜索PTE,找到mmu.h,看到关于PTE的一些宏定义):
/*PTE的一些宏定义*/ //表示当前物理页是否存在 #define PTE_P 0x001 //对应物理页面是否可写 #define PTE_W 0x002 //对应物理页面用户态是否可以访问 #define PTE_U 0x004 //对应物理页面在写入时是否同时将更低级储存设备写入 #define PTE_PWT 0x008 //对应物理页面是否能被放入高速缓存 #define PTE_PCD 0x010 //对应物理页面是否被访问 #define PTE_A 0x020 //脏位,对应物理页面是否被写入 #define PTE_D 0x040 //对应物理页面的页面大小 #define PTE_PS 0x080 //必须为零的部分 #define PTE_MBZ 0x180 // Bits must be zero //用户可自定义的部分 #define PTE_AVAIL 0xE00 -
实际上,我们在lab2中已经回答了PTE以及PDE的组成。在此我们利用上次的PTE的组成以及作用:
地址 名称 在ucore中的对应以及潜在作用 31:12 Physical Page Address 对应物理页的起始物理地址,用于定位物理也的位置 11:9 Avail PTE_AVAIL,保留给OS使用 8 Global 7 0 PTE_MBZ 6 Dirty PTE_D,脏位,用于确认数据是否有效 5 Accessed PTE_A,用于确认对应页表是否被使用 4 Cache Disabled PTE_PCD, 用于cache 3 Write Through PTE_PWT, 用于cache 2 User/Supervisor PTE_U,用于确认用户态下是否可以访问对应的物理页 1 Read/Write PTE_W,用于确认对应的物理页是否可写 0 Present PTE_P,用于确认页表项所对应的物理页是否存在
因此我们可以认为,分页机制的实现确保了虚拟地址和物理地址之间的对应关系。一方面,通过查找虚拟地址是否存在于一二级页表中可知发现该地址是否是合法的;同时可以通过修改映射关系实现页替换操作。另一方面,在实现页替换时涉及到换入换出:换入时需要将某个虚拟地址对应的磁盘的一页内容读入到内存中,换出时需要将某个虚拟页的内容写到磁盘中的某个位置。而页表项可以记录该虚拟页在磁盘中的位置,为换入换出提供磁盘位置信息,页目录项则是用来索引对应的页表。
同时,我们可知PDE和PTE均保留了一些位给操作系统使用,具体可以应用在页替换算法时。present位为0时CPU不使用PTE上内容,这时候这些位便会闲置,可以将闲置位用于保存别的信息,例如页替换算法被换出的物理页在交换分区的位置等。同时,需要注意到dirty位,操作系统根据脏位可以判断是否对页数据进行write through。
如果ucore的缺页服务例程在执行过程中访问内存,出现了页访问异常,请问硬件要做哪些事情?
&首先调用中断机制,引起中断
&保存现场:将发生错误的线性地址保存在cr2寄存器中;并在中断栈中依次压入
EFLAGS,CS, EIP。并且把访问异常码error code保存到中断栈;
&根据中断描述符表查询到对应页访问异常的ISR,跳转到对应的ISR处执行,实 现缺页服务例程
练习2:补充完成基于FIFO的页面替换算法(需要编程)
完成vmm.c中的do_pgfault函数,并且在实现FIFO算法的swap_fifo.c中完成map_swappable和swap_out_vistim函数。通过对swap的测试。注意:在LAB2 EXERCISE 2处填写代码。执行
make qemu
后,如果通过check_swap函数的测试后,会有“check_swap() succeeded!”的输出,表示练习2基本正确。
请在实验报告中简要说明你的设计实现过程。
回答:
首先看一下gitbook上对FIFO的介绍:
先进先出(First In First Out, FIFO)页替换算法:该算法总是淘汰最先进入内存的页,即选择在内存中驻留时间最久的页予以淘汰。只需把一个应用程序在执行过程中已调入内存的页按先后次序链接成一个队列,队列头指向内存中驻留时间最久的页,队列尾指向最近被调入内存的页。这样需要淘汰页时,从队列头很容易查找到需要淘汰的页。FIFO算法只是在应用程序按线性顺序访问地址空间时效果才好,否则效率不高。因为那些常被访问的页,往往在内存中也停留得最久,结果它们因变“老”而不得不被置换出去。FIFO算法的另一个缺点是,它有一种异常现象(Belady现象),即在增加放置页的页帧的情况下,反而使页访问异常次数增多
实际上,仅仅对算法实现原理了解不足以实现页面置换机制,我们还需要考虑一些问题(问题的回答为自己的思考以及gitbook或者CSDN上的引用):
-
哪些页可以被换出?
基本原则:只有映射到用户空间且被用户程序直接访问的页面才能被交换,而被内核直接使用的内核空间的页面不能被换出。
避免将OS用到的数据和代码换出导致系统速度大幅度下降甚至导致系统崩盘。
-
一个虚拟的页如何与硬盘上的扇区建立对应关系?
[如果一个页被置换到了硬盘某8个扇区,该PTE的最低位–present位应该为0 (即 PTE_P 标记为空,表示虚实地址映射关系不存在),接下来的7位暂时保留,可以用作各种扩展;而原来用来表示页帧号的高24位地址,恰好可以用来表示此页在硬盘上的起始扇区的位置(其从第几个扇区开始)。为了在页表项中区别 0 和 swap 分区的映射,将 swap 分区的一个 page 空出来不用,也就是说一个高24位不为0,而最低位为0的PTE表示了一个放在硬盘上的页的起始扇区号:
swap_entry_t ------------------------- | offset | reserved | 0 | ------------------------- 24 bits 7 bits 1 bit -
何时进行换入和换出操作?
当ucore或应用程序访问地址所在的页不在内存时,就会产生page fault异常,引起调用do_pgfault函数,此函数会判断产生访问异常的地址属于check_mm_struct某个vma表示的合法虚拟地址空间,且保存在硬盘swap文件中(即对应的PTE的高24位不为0,而最低位为0),则是执行页换入的时机,将调用swap_in函数完成页面换入
ucore目前大致有两种换出策略,即积极换出策略和消极换出策略。积极换出策略是指操作系统周期性地(或在系统不忙的时候)主动把某些认为“不常用”的页换出到硬盘上,从而确保系统中总有一定数量的空闲页存在,这样当需要空闲页时,基本上能够及时满足需求;消极换出策略是指,只是当试图得到空闲页时,发现当前没有空闲的物理页可供分配,这时才开始查找“不常用”页面,并把一个或多个这样的页换出到硬盘上。
ucore实现的是消极换出策略,在ucore调用alloc_pages函数获取空闲页时,此函数如果发现无法从物理内存页分配器获得空闲页,就会进一步调用swap_out函数换出某页,实现一种消极的换出策略。
-
如何设计数据结构以支持页替换算法?
我们可知Page中增添了pra_page_link变量,该变量可用来构造按页的第一次访问时间进行排序的一个链表,这个链表的开始表示第一次访问时间最近的页,链表结尾表示第一次访问时间最远的页。
当一个物理页 (struct Page) 需要被 swap 出去的时候,首先需要确保它已经分配了一个位于磁盘上的swap page(由连续的8个扇区组成)。我们可以看一下swap_manager结构体,基本是一个完整的框架:
非常类似于LAB2的物理内存管理的结构体,用该方法非常方便调用不同的算法实现,且方便调试
struct swap_manager { const char *name; /* 全局的初始化 */ int (*init) (void); /* 初始化之前的数据*/ int (*init_mm) (struct mm_struct *mm); /* 结合定时产生的中断,可以实现一种积极的换页策略 */ int (*tick_event) (struct mm_struct *mm); /* 用于记录页访问情况相关属性 */ int (*map_swappable) (struct mm_struct *mm, uintptr_t addr, struct Page *page, int swap_in); /* 当页面被标记为shared时,将调用这个例程从交换管理器中删除addr条目 */ int (*set_unswappable) (struct mm_struct *mm, uintptr_t addr); /* 挑选需要换出的页 */ int (*swap_out_victim) (struct mm_struct *mm, struct Page **ptr_page, int in_tick); /* 检查函数 */ int (*check_swap)(void); };
下面具体实现FIFO算法:
实际上完成FIFO算法主要在于三个函数(非常容易,再根据注释即可完成):
//FIFO算法的初始化
static int _fifo_init_mm(struct mm_struct *mm)
{
list_init(&pra_list_head);
mm->sm_priv = &pra_list_head;
cprintf(" mm->sm_priv %x in fifo_init_mm\n",mm->sm_priv);
return 0;
}
//用于记录页访问情况相关属性,即维护FIFO的队列情况
//就是将当前的物理页面插入到FIFO算法中维护的可被交换出去的物理页面链表中的末尾
static int _fifo_map_swappable(struct mm_struct *mm, uintptr_t addr,
struct Page *page, int swap_in)
{
list_entry_t *head=(list_entry_t*) mm->sm_priv;
list_entry_t *entry=&(page->pra_page_link);
assert(entry != NULL && head != NULL);
//record the page access situlation
/*LAB3 EXERCISE 2: YOUR CODE*/
//(1)link the most recent arrival page at the back of the pra_list_head qeueue.
// 将当前指定的物理页插入到链表的末尾
list_add_before(head, entry);
return 0;
}
//将链表头的物理页面取出,然后删掉对应的链表项
static int
_fifo_swap_out_victim(struct mm_struct *mm, struct Page ** ptr_page, int in_tick)
{
list_entry_t *head=(list_entry_t*) mm->sm_priv;
assert(head != NULL);
assert(in_tick==0);
/* Select the victim */
/*LAB3 EXERCISE 2: YOUR CODE*/
//(1) unlink the earliest arrival page in front of pra_list_head qeueue
//(2) set the addr of addr of this page to ptr_page
// 取出链表头,即最早进入的物理页面
list_entry_t *le = list_next(head);
// 确保链表非空
assert(le != head);
// 找到对应的物理页面的Page结构
struct Page *page = le2page(le, pra_page_link);
// 从链表上删除取出的即将被换出的物理页面
list_del(le);
*ptr_page = page;
return 0;
}
然后补全do_pgfault,使其可以完成当所需的页不在内存时实现换入换出。根据函数的注释我们可知:
实现的流程如下:
- 判断当前是否对交换机制进行了正确的初始化;
- 将虚拟页对应的物理页从外存中换入内存;
- 给换入的物理页和虚拟页建立映射关系;
- 将换入的物理页设置为允许被换出;
根据注释很容易实现代码:
else
{
if (swap_init_ok)
{
// 判断是否当前交换机制正确被初始化
struct Page *page = NULL;
// 将物理页换入到内存中
swap_in(mm, addr, &page);
// 将物理页与虚拟页建立映射关系
page_insert(mm->pgdir, page, addr, perm);
// 同时在物理页中维护其对应到的虚拟页的信息,
page->pra_vaddr = addr;
// 设置当前的物理页为可交换的
swap_map_swappable(mm, addr, page, 1);
}
else
{
cprintf("no swap_init_ok but ptep is %x, failed\n",*ptep);
goto failed;
}
}
至此我们运行make qemu,查看结果:
至此我们运行make qemu,查看结果:
................
check_vma_struct() succeeded!
page fault at 0x00000100: K/W [no page found].
check_pgfault() succeeded!
check_vmm() succeeded.
ide 0: 10000(sectors), 'QEMU HARDDISK'.
ide 1: 262144(sectors), 'QEMU HARDDISK'.
SWAP: manager = fifo swap manager
BEGIN check_swap: count 1, total 31995
setup Page Table for vaddr 0X1000, so alloc a page
setup Page Table vaddr 0~4MB OVER!
set up init env for check_swap begin!
page fault at 0x00001000: K/W [no page found].
page fault at 0x00002000: K/W [no page found].
page fault at 0x00003000: K/W [no page found].
page fault at 0x00004000: K/W [no page found].
set up init env for check_swap over!
write Virt Page c in fifo_check_swap
write Virt Page a in fifo_check_swap
write Virt Page d in fifo_check_swap
write Virt Page b in fifo_check_swap
write Virt Page e in fifo_check_swap
page fault at 0x00005000: K/W [no page found].
swap_out: i 0, store page in vaddr 0x1000 to disk swap entry 2
write Virt Page b in fifo_check_swap
write Virt Page a in fifo_check_swap
page fault at 0x00001000: K/W [no page found].
swap_out: i 0, store page in vaddr 0x2000 to disk swap entry 3
swap_in: load disk swap entry 2 with swap_page in vadr 0x1000
write Virt Page b in fifo_check_swap
page fault at 0x00002000: K/W [no page found].
swap_out: i 0, store page in vaddr 0x3000 to disk swap entry 4
swap_in: load disk swap entry 3 with swap_page in vadr 0x2000
write Virt Page c in fifo_check_swap
page fault at 0x00003000: K/W [no page found].
swap_out: i 0, store page in vaddr 0x4000 to disk swap entry 5
swap_in: load disk swap entry 4 with swap_page in vadr 0x3000
write Virt Page d in fifo_check_swap
page fault at 0x00004000: K/W [no page found].
swap_out: i 0, store page in vaddr 0x5000 to disk swap entry 6
swap_in: load disk swap entry 5 with swap_page in vadr 0x4000
count is 0, total is 7
check_swap() succeeded!
++ setup timer interrupts
100 ticks
100 ticks
100 ticks
..............
符合预期,并与gitbook上所给答案几乎相同,故可以认为正确实现了FIFO算法。
使用make grade查看: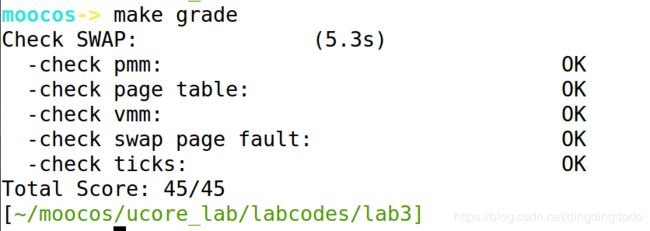
问题:如果要在ucore上实现"extended clock页替换算法"请给你的设计方案,现有的swap_manager框架是否足以支持在ucore中实现此算法?如果是,请给你的设计方案。如果不是,请给出你的新的扩展和基此扩展的设计方案。并需要回答如下问题
(在此较为详细地回答了该问题,因为之后challenge会用到)
首先补充一下时钟页替换算法:
时钟(Clock)页替换算法:是LRU算法的一种近似实现。时钟页替换算法把各个页面组织成环形链表的形式,类似于一个钟的表面。然后把一个指针(简称当前指针)指向最老的那个页面,即最先进来的那个页面。另外,时钟算法需要在页表项(PTE)中设置了一位访问位来表示此页表项对应的页当前是否被访问过。当该页被访问时,CPU中的MMU硬件将把访问位置“1”。当操作系统需要淘汰页时,对当前指针指向的页所对应的页表项进行查询,如果访问位为“0”,则淘汰该页,如果该页被写过,则还要把它换出到硬盘上;如果访问位为“1”,则将该页表项的此位置“0”,继续访问下一个页。该算法近似地体现了LRU的思想,且易于实现,开销少,需要硬件支持来设置访问位。时钟页替换算法在本质上与FIFO算法是类似的,不同之处是在时钟页替换算法中跳过了访问位为1的页。
答:现有的swap_manager框架足以支持在ucore中实现此算法。在练习1已经回答了PTE的组成,在mmu.h通过宏定义的方式定义了PTE组成,其中包括脏位和访问位,因此我们可以根据这两位知道虚拟页是否被访问过以及是否被写过,之后将FIFO的队列式链表改造成环形循环列表,原来的初始化函数不需要改,维护链表的函数_fifo_map_swappable函数需要进行小修改,令每次加入新结点后不仅将其加在最后一个链表项后面,而且要将其指针指向head,形成环形循环链表。
现需要对swap_out_victim进行显著改变:
总是从当前指针开始,对循环链表逐一扫描,通过判断每个链表项所指的物理页状态来决定进行何种操作:
(用
- 如果状态是(0, 0),说明当前数据无效且没有被修改,只需将该物理页面从链表上去下,该物理页面记为换出页 面,且不需要将其写入swap分区;
- 如果状态是(1, 0), 将该物理页对应的虚拟页的PTE中的访问位都置成0,然后指针跳转到下一个物理页面;
- 如果状态是(0, 1),则将该物理页对应的虚拟页的PTE中的dirty位改成0,并且将该物理页写入到外存中,然后指针跳转到下一个物理页;
- 如果状态是(1, 1),则该物理页的所有对应虚拟页的PTE中的访问为置成0,然后指针跳转到下一个物理页面;
基于此即可实现简单的时钟页替换算法
个人认为该算法的核心在于对页的筛选优先于未访问过的,如果access未访问,则将其换出即可,当然,如果出现access未访问但dirty使用的情况(该情况我也不知道为什么出现。。没有访问竟然有修改)则将dirty改成0即可。如果access都访问了,则优先筛选出dirty未使用的情况,因为不需要写回磁盘可以省很多时间。如果前面情况都没有出现,则必须选择<1,1>的情况,这时候把数据写回,access和dirty均置0即可。
回答问题:
-
需要被换出的页的特征是什么?
最早被换入,且最近没有再被访问的页
-
在ucore中如何判断具有这样特征的页?
通过判断是否访问过,对未访问过的物理页FIFO即可
-
何时进行换入和换出操作?
当需要调用的页不在页表中时,并且在页表已满的情况下,会引发PageFault,此时需要进行换入和换出操作。具体是当保存在磁盘中的内存需要被访问时,需要进行换入操作;当位于物理页框中的内存被页面替换算法选择时,需要进行换出操作。
扩展练习 Challenge:实现识别dirty bit的 extended clock页替换算法(需要编程)
实际上,对该算法的基本思想以及实现思想在上一题的练习中已经回答,在此对具体实现进行说明。
数据结构方面,Enhanced Clock算法需要一个环形链表和一个指针,这个可以在原有的双向链表基础上实现。为了方便进行循环访问,将原先的头部哨兵删除,将所有的页面形成一个环形链表。指向环形链表指针也就是Enhanced Clock算法中指向下个页面的指针。
插入操作与FIFO类似,如果环形链表为空,那么这个页面就是整个链表,将指针指向这个页面。否则,只需要将页面插入指针指向的页面之前即可。
换出操作较为复杂,因为需要考虑访问位以及dirty位,实际上是根据
如果状态是(0, 0),说明当前数据无效且没有被修改,只需将该物理页面从链表上去下,该物理页面记为换出页 面,且不需要将其写入swap分区;如果状态是(1, 0), 将该物理页对应的虚拟页的PTE中的访问位都置成0,然后指针跳转到下一个物理页面;如果状态是(0, 1),则将该物理页对应的虚拟页的PTE中的dirty位改成0,并且将该物理页写入到外存中,然后指针跳转到下一个物理页;如果状态是(1, 1),则该物理页的所有对应虚拟页的PTE中的访问为置成0,然后指针跳转到下一个物理页面;
具体实现时,我们首先遍历链表,如果存在<0,0>,则将其置出即可;如果未找到,则再次遍历,此次遍历过程寻找<0,1>,如果是<0,1>,则将其置出,否则将其access位置0;如果仍为找到,则再次判断是否存在<0,0>(这里的<0,0>意味着最初的状态是<1,0>),如果有,则置出;否则再次遍历一遍,如果找到为<0,1>的(这里的<0,1>表示最初是<1,1>),将其置出。基本思想如此,较易实现。
challenge具体代码不在此详述。如需要可CSDN联系
如果给你带来了帮助,可点击关注,博主将继续努力推出好文。