从TCP拥塞本质看BBR算法及其收敛性(附CUBIC的改进/NCL机制)
本文试图给出一些与BBR算法相关但却是其之外的东西。
1.TCP拥塞的本质
注意,我并没有把题目定义成网络拥塞的本质,不然又要扯泊松到达和排队论了。事实上,TCP拥塞的本质要好理解的多!TCP拥塞绝大部分是由于其”加性增,乘性减“的特性造成的!也就是说,是TCP自己造成了拥塞!TCP加性增乘性减的特性引发了丢包,而丢包的拥塞误判带来了巨大的代价,这在深队列+AQM情形下尤其明显。
我尽可能快的解释。争取用一个简单的数学推导过程和一张图搞定。
除非TCP端节点之间的网络带宽是均匀点对点的,否则就必然要存在第二类缓存。TCP并无法直接识别这种第二类缓存。正是这第二类缓存的存在导致了拥塞的代价特别严重。我依然用经典的图作为基准来解释:
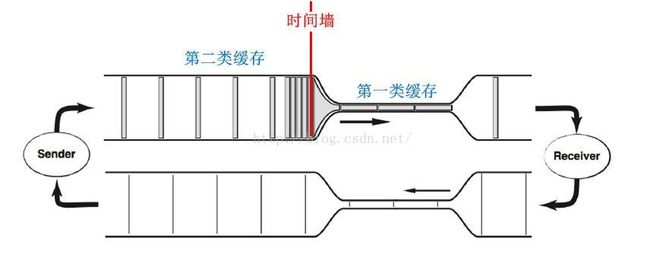
假设TCP端节点之间的BDP为C,那么:
C = C1 + C2 (其中C1是网络本身的管道容量,而C2是节点缓存的容量)
由于路径中最小带宽为B,那么整个链路的带宽将由B决定,在排队未发生时(即没有发生拥塞时),假设测量RTT为rtt0,发送速率为B0=B,则:
C1 = B0*rtt0
C = B0*rtt0 +C2 > B*rtt0
此时,任何事情均为发生,一切平安无事!继续着TCP”加性增“的行为,此时发送端继续线性增加发送速率,到达B1,此时:
B0*rtt0 < B1*rtt1
C是客观的不变量,这会导致C2开始被填充,即开始轻微排队。排队会造成RTT的增加。假设C2已经被加性增特性填充到满载的临界,此时发送带宽为B2,即:
C = B2*rtt2 = B*rtt0 + C2
B2*rtt2是定值,rtt2在增大,B2则必须减小!但是”临界值已经达到“这件事反馈到发送端,至少要经过1/2个RTT,在忽略延迟ACK和ACK丢失等反馈失灵情形下,最多的反馈时间要1个RTT。问题是,TCP发送端怎么知道C2已经被填满了??它不知道!除非再增加一些窗口,多发一个数据包!这行为是如此的小心翼翼,以至于你会认为这是多么正确的做法!在发送端不知情的情况下,会持续增加或者保持当前的拥塞窗口,但是绝对不会降低,然而此时RTT已经增大,必须降速了!事实上,在丢包事件发生前,TCP是一定会加性增窗的,也就是说,丢包是TCP唯一可以识别的事件!
TCP在临界点的加性增窗行为,目的只是为了探测C2是不是已经被填满。我们来根据以上的推导计算一下这次探测所要付出的代价。由于反馈C2已满的时间是1/2个RTT到1个RTT,取决于C2的位置,那么将会在1/2个RTT到1个RTT的时间内面临着丢包!注意,这里的代价随着C2的增加而增加,因为C2越大,RTT的最终测量值,即rtt2则越大!这就是深队列丢包探测的问题。然而,在30多年前,正是这个”加性增“行为,直接导出了”基于丢包的拥塞控制算法“。那时没有深队列,问题貌似还不严重。但随着C2的增加,问题就越来越严重了,RTT的增大使得丢包处理的代价更大!
记住,对丢包的敏感不是错误,基于丢包的拥塞探测的算法就是这样运作的,错误之处在于,丢包的代价太大-窗口猛降,造成管道被清空。这是由于深队列的BufferBloat引发的问题,在浅队列中问题并不严重。随着路由器AQM技术的发展,好的初衷会对基于丢包的拥塞探测产生反而坏的影响。
现在,我们明白了,之所以基于丢包的拥塞控制算法的带宽利用率低,就是由于其填充第二类缓存所平添排队延迟造成的虚假且逐渐增大的RTT最终导致了BDP很大的假象,而这一切的目的,却仅仅是为了探测丢包,自以为在丢包前已经100%的利用了带宽,然而在丢包后,所有的一切都加倍还了回去!是丢包导致了带宽利用率的下降,而不是增加!!
总结一句, 用第二类缓存来探测BDP是一种透支资源的行为。
我一直觉得这不是TCP的错,但在发现BBR是如此简单之后,不再这么认为了,事实上,通过探测时间窗口内的最大带宽和最小RTT,就可以明确知道是不是已经填满了第一类缓存,并停止继续填充第二类缓存,即向最小化排队的方向收敛!曾经的基于时延的算法,比如Vegas,其实已经在走这条路了,它已经知道RTT的增加意味着排队了,只是它没有采用时间窗口过滤掉常规波动,而是采用了RTT增量窗口来过滤波动,最终甚至由于RTT抖动主动减少窗口,所以会造成竞争性不足。不管怎样,这是一种君子行为,它总是无力对抗基于丢包算法的流氓行为。
BBR综合了二者,对待君子则君子(不会填充第二类缓存,造成排队,因为一旦排队,所有连接的RTT均会增加,对类似Vegas的不利),对待流氓则流氓(采用滑动时间窗口抗带宽噪声,采用固定超时时间窗口抗RTT噪声,时间窗口内,决不降速),这是一种什么行为?我觉得比较类似警察的行为...
如果不是很理解,那么看看那些高速公路上随意变道或者占用应急车道的行为导致的后果吧(大多数没有什么后果,原因在于监管的不力,这就好像CUBIC遇到了Vegas一样!)。基于此,即便不使用BBR算法,最好也不要使用基于时延的Vegas等算法,但是也许,我们可以更好的改进CUBIC,我们也许已经知道了如何去更改CUBIC了。CUBIC的问题不是其算法本身导致的,而是TCP拥塞控制的框架导致的。见本文”CUBIC更改前奏-实现NCL(非拥塞丢包)“小节。
本节的最后,我们来看点关于第二类缓存的特性。
第二类缓存既然不是用来进行”BDP探测“(事实上,BDP的组成里根本就该有第二类缓存)的,那要它干什么??
我想这里可以简单解释一下了。第二类缓存的作用是为了适配统计复用的分组交换网络上路由器处理不过来这个问题而引入的。如果没有路由器交换机节点的存在,那么第二类缓存这里什么也没有:
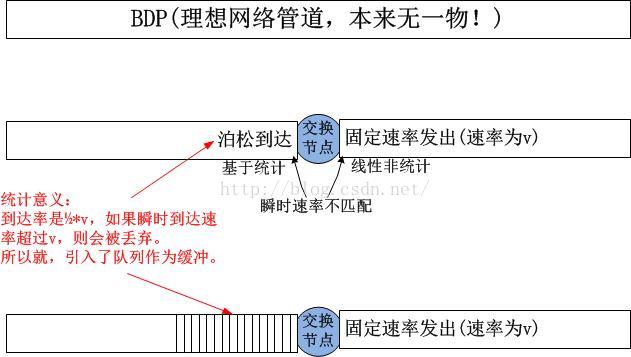
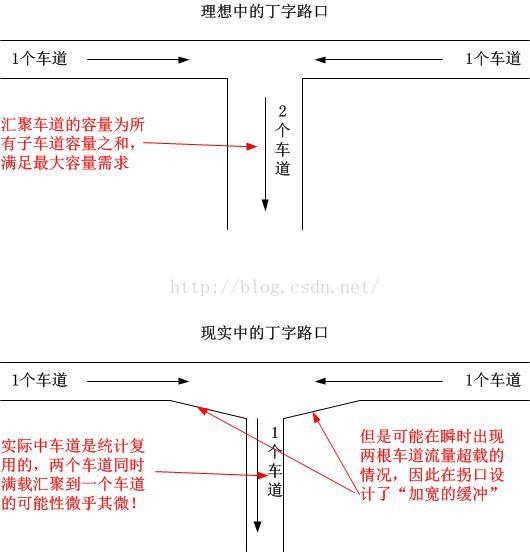
本节完!
2.突发特征与pacing
这里仅仅提一点,那就是突发最容易造成排队!这也是可以从泊松到达的排队论中推导出来的。为了不被人认为我在这里装逼,就不展示过程了,需要的请私下联系我。解决突发问题的方法有两种,一种就是边缘网络路由器上设置整形规则,这有效避免了汇聚层以及核心层路由器的排队。另外一种更加有效的方法就是直接在端主机做Pacing。Linux在3.12内核以后已经支持了FQ这个sched模块,它基于TCP连接发现的Pacing Rate来发送数据,取代了之前一窗数据突发出去的弊端。
Pacing背后的思想就是尽量减少网络交换节点处队列的排队!通过上一节的最后,我们知道,交换节点出口的速率恒定,而入口可能会面临突发,虽然在统计意义上,出入口的处理能力匹配即可,然而即便大多数时候到达速率都小于出口速率,只要有一瞬间的突发就可能冲击队列到爆满!事实上队列缓存存在的理由就是为了应对这种情况!
传统意义上,TCP拥塞控制逻辑仅仅计算一个拥塞窗口,TCP发送按照这个拥塞窗口发送适当大小的数据,但这些数据几乎是一次性突发出去的,Linux 3.9之后的patch出现了TCP Pacing rate的概念,可以将一窗数据按照一定的速率平滑发送出去,然而TCP本身并没有实现实际的Pacing发送逻辑,Linux 3.12内核实现了FQ这个schedule,TCP可以依靠这个schedule来实现Pacing了。
为什么不在TCP层实现这个Pacing,原因在于TCP层并不能控制严格的发送时序,它是属于软件层的。Pacing必须在数据包被发送到链路之前进行才比较有效,因为这时的Pacing是真实的!切记,Pacing目前可以通过TC来配置,要想Pacing起作用,在其之后就不能再有别的队列,否则,FQ的Pacing Rate就可能会被后面的队列给冲掉!
...
我们继续谈BBR算法的收敛特性。
3.BBR算法的收敛性
BBR算法的收敛性与之前基于加性增乘性减的算法的收敛性完全不同,比之前的更加优美!欲知如何,我先展示加性增乘性减的收敛图: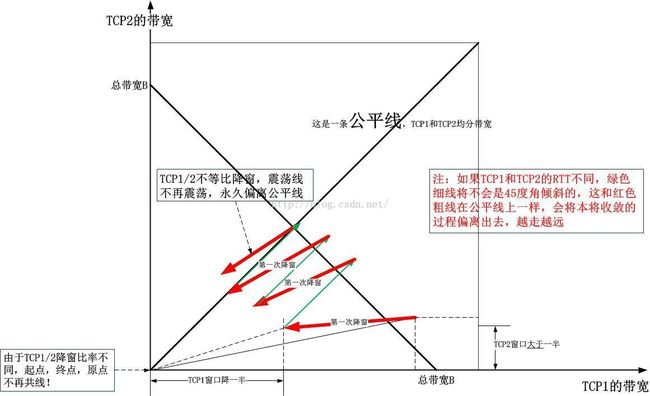
以下是根据上图总结出来的一幅抽象图:
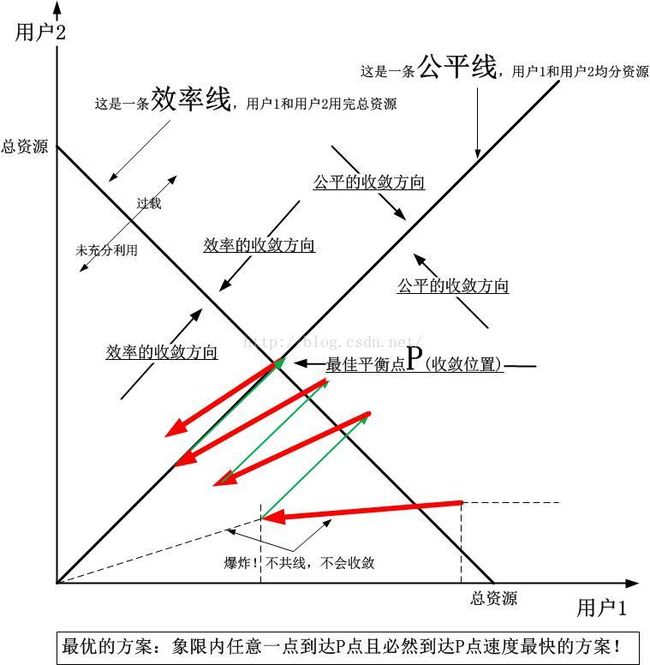
当我们认识BBR收敛性的时候,我们要换一种思路。即BBR收敛过程并不是独立的,它们是配合的,BBR算法根本就没有定义收敛点,只是大家互相配合,满足其带宽之和不超过第一类缓存的大小,即真正BDP的大小,在这个约束条件下,BBR最终自己找到了一个稳定的平衡点。
在展示图解之前,为了简单起见,我们先假设BBR在PROBE_BW状态,讨论在该状态的收敛过程。我们先看一下PROBE_BW状态的增益系数数组:
static const int bbr_pacing_gain[] = {
// 占据带宽,在带宽满之前,一直运行。效率优先,尽可能处在这里久一些...
BBR_UNIT * 5 / 4, /* probe for more available bw */
// 出让带宽,只要带宽不满了,则进入稳定状态平稳运行。兼顾公平,尽可能离开这里...
BBR_UNIT * 3 / 4, /* drain queue and/or yield bw to other flows */
// 一方面平稳运行,一方面等待出让的带宽不被自己重新抢占!
BBR_UNIT, BBR_UNIT, BBR_UNIT, /* cruise at 1.0*bw to utilize pipe, */
BBR_UNIT, BBR_UNIT, BBR_UNIT /* without creating excess queue... */
};很显然,BBR希望连接尽可能多的使用带宽,因此bbr_pacing_gain[0]的使能时间尽可能久些,其退出条件是:
已经运行超过了一个最小RTT时间并且要么发生了丢包,要么本次ACK到来前的inflight的值已经等于窗口值了。
虽然BBR希望一个连接尽可能占用带宽,但是BBR的原则是不能排队或者起码减少排队,当另一个连接发起时,额外的带宽占用会让处在正增益的连接inflight发生满载,因此bbr_pacing_gain[0]会让位给bbr_pacing_gain[1],进而出让带宽给新连接,随后进入长达6个RTT周期的平稳时期,等待出让的带宽被利用。总之,总结一点就是:
如果没有其它连接,一个连接会一直试图占满所有带宽,一旦有新连接,则老连接尽量一次性或者很短时间内出让部分带宽,然后在这些带宽被利用之前,老连接不再抢带宽,如果超过6个RTT周期之后,老连接重新开始新一轮抢占,出让,等待被利用的过程,从而和其它的连接一起收敛到平衡点。
因此,和加性增乘性减的独立收敛方案不同,BBR一开始就是考虑到对方存在的收敛方案。我们看一个简单的例子,描述一下大致的收敛思想:
初始状态
连接1:10 & 连接2:0
1>.连接1在一个RTT出让1/4带宽,稳定6个RTT,带宽为7.5 & 连接2以4个RTT为一个PROBE周期分别的带宽为:1.25, 1.55,1.95,2.4
2>.连接1在bbr_pacing_gain[0]占据带宽失败,继续出让带宽,稳定在5.6 & 连接2以3个RTT为一个PROBE周期分别的带宽为3.0,3.75,4.6
3>.完成收敛。
最后,我们可以看一下BBR的收敛图了:
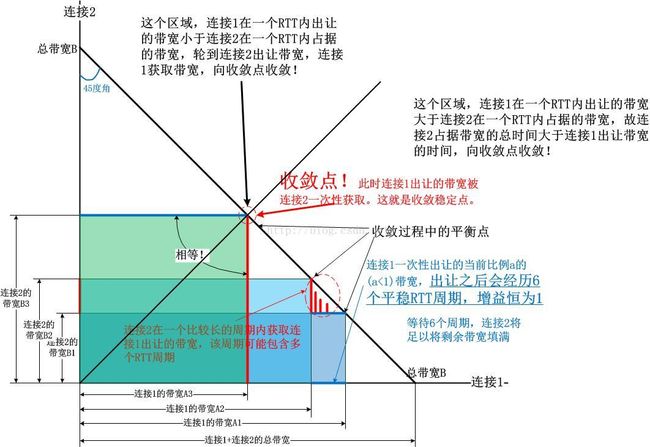
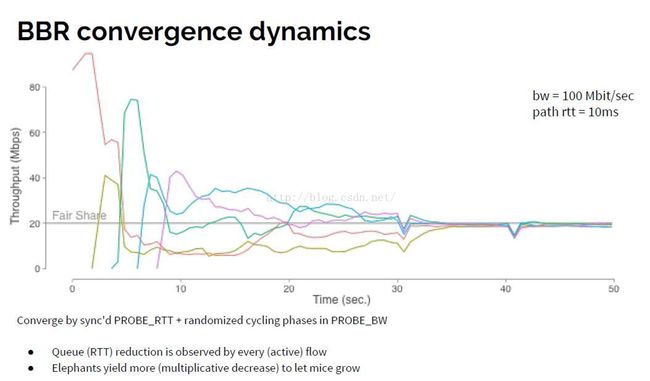
1).BBR_UNIT * 5 / 4的增益要保持多个最小RTT(非滑动的时间内)的时间,直到填满带宽(但要避免排队!所以只要触及带宽即可,即上一次的inflight等于本次的窗口估值)
2).BBR_UNIT * 3 / 4的增益保持的时间要短,最多一个最短RTT时间就退出,在不到RTT时间内,如果排空了部分网络资源也退出。
3).BBR_UNIT的增益紧接在BBR_UNIT * 3 / 4之后,并且持续6个最小RTT的时间。
4).在1)和2)表示的获取和出让之间,保持等比例平衡,默认为当前带宽1/4的获取和出让。
我们来根据以上规则描述上图中的收敛:
1).在上图的右下边,连接1带宽大于连接2,以上的规则使得连接1一次出让的带宽大于连接2一次获取,因此连接2多个RTT周期内维持在BBR_UNIT * 5 / 4增益,平衡点向沿着带宽线向左上收敛。
2).在上图的左上方,连接2的带宽大于连接1,连接1即使再出让带宽,即便连接2获取了,那连接2回赠的带宽还是大于连接1的出让,使得连接1比较久维持在BBR_UNIT * 5 / 4增益,向右下收敛。
4.BBR的公平收敛性与调优
关于收敛和性能调优的话题,这里还要多说几句。首先,虽然收敛是必然的,上文已经分析,但是收敛速度如何呢?BBR在Linux实现的目前是第一个版本,其带宽出让环节和带宽获取环节中,增益系数中有一个定值,即3/4和5/4,这两个值的算术平均值为1,这里的意义在于保持一个比例上的平衡。如果将出让系数3/4调大,比如调到1/2,那么获取带宽的增益系数就要调整为3/2,这会让收敛速度更快些。
我着手要做的就是参数化这个bbr_pacing_gain数组:
static const int bbr_pacing_gain[] = {
BBR_UNIT * a, // 1其次,由于以上的讨论都是基于PROBE_BW稳定状态这种理想化场景的,然而现实中你无法忽略STARTUP,DRAIN等状态,为了在测试中找到状态瓶颈,包括带宽利用最大化,收敛公平性,我们把BBR的状态机看作是一个马尔科夫链:
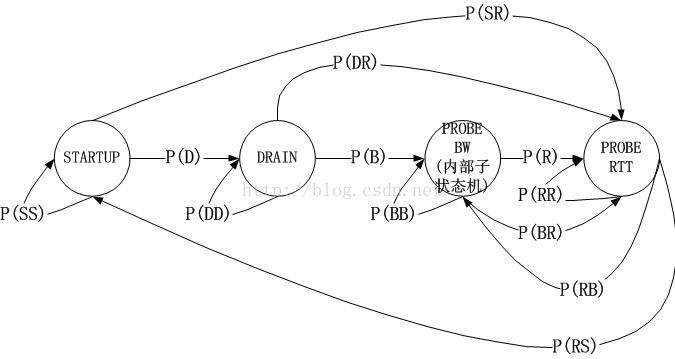
比如,调优的目标是尽可能让BBR系统运行在PROBE_BW状态,且在PROBE_BW内部,也有一个状态机,我们希望尽可能的稳定在系数为1的增益上运行。
获取了各种概率数据后,BBR的参数化调优方案就有了基调了。
在上一节,我们描述了BBR算法在稳定的PROBE_BW状态的收敛性。现在,我们来看一个异常的但是有普遍意义的场景,那就是发生拥塞的时候,BBR如何表现,如何收敛。由于BBR本身的宗旨就是消除队列,我们假设某个或者某些连接刚启动时,在STARTUP状态填充了队列的一部分,此时在其进入DRAIN状态之前,队列一直是存在的,由于队列已经开始被填充,那么已有的连接会在相当长的时间内无法采集到更小的RTT,最终,它们几乎会同时进入PROBE_RTT状态!看BBR的PROBE_RTT实现,就知道在这个状态中,cwnd会被瞬间缩减到4个MSS的大小!这会导致大量的网络资源被腾出,而这些腾出的资源会被新连接共享,这就是STARTUP和PROBE_RTT状态的公平性!
但是,如果和CUBIC共享资源怎么办?!
很遗憾,BBR无法识别CUBIC的存在!当BBR将cwnd缩减的时候,CUBIC会继续填充第二类缓存,直到透支掉最后的那一个字节。随后,也许你会认为CUBIC会执行乘性减来缩减cwnd,是的,确实如此,然而即使这样,也不能指望它们会腾出带宽,因为CUBIC的行为是各自独立的,你无法假设它们会同时进入乘性减窗,因此几乎可以肯定,共享链路上的缓存总是趋向与被填满的状态,这都是CUBIC的所为。然而怎能怪它呢,毕竟它的基础就是填满所有两类缓存为止,决不降速(不同于BBR的发现排队之前绝不减速的特性)。因此,BBR和CUBIC共存的时候,很有可能会出现全盘皆输的局面。
怎么缓解?!
事实上,BBR没必要对CUBIC过分谦让。只要满足自己不排队即可(因为排队于人于己均无好处!)。因此大可不必将窗口降到4个MSS,直接降到一半即可,这也是沿袭了传统乘性减的规则!此外,在PROBE_RTT阶段,也不要在这个状态运行过久,时间减半意思意思就好!为此,很容易更改代码:
0).定义一个新的fast_probe模块参数
1).bbr_set_cwnd的修改:
if (bbr->mode == BBR_PROBE_RTT) { /* drain queue, refresh min_rtt */
if (fast_probe)
tp->snd_cwnd = max(tp->snd_cwnd >> 1, bbr_cwnd_min_target); // 取cwnd/2!
else
tp->snd_cwnd = min(tp->snd_cwnd, bbr_cwnd_min_target);
}...
if (!bbr->probe_rtt_done_stamp &&
tcp_packets_in_flight(tp) <= bbr_cwnd_min_target) {
bbr->probe_rtt_done_stamp = tcp_time_stamp +
msecs_to_jiffies(fast_probe?(bbr_probe_rtt_mode_ms>>1):bbr_probe_rtt_mode_ms);
...
}最后,我们看一下STARTUP和DRAIN的增益系数,它们互为倒数,怎么填充就怎么清空,完美回退。
/* We use a high_gain value of 2/ln(2) because it's the smallest pacing gain
* that will allow a smoothly increasing pacing rate that will double each RTT
* and send the same number of packets per RTT that an un-paced, slow-starting
* Reno or CUBIC flow would:
*/
static const int bbr_high_gain = BBR_UNIT * 2885 / 1000 + 1;
/* The pacing gain of 1/high_gain in BBR_DRAIN is calculated to typically drain
* the queue created in BBR_STARTUP in a single round:
*/
static const int bbr_drain_gain = BBR_UNIT * 1000 / 2885;
我们来尝试调整这参数,可以是不对称的缓慢Drain,这是基于在降速排空队列的过程中,可能已经有别的连接出让了带宽!
5.CUBIC更改前奏-实现NCL(非拥塞丢包 Non-congestion Loss)
CUBIC还算是迄今比较伟大的算法,它不会轻易被BBR取代,但是它需要被改进。首先,在没有AQM时,加性增乘性减本身并没有错,一般的丢包都是尾部拥塞丢包,这对于TCP拥塞控制而言,基于丢包的拥塞探测太容易做了,但是尾部丢包会带来一系列的问题,为了解决这些问题,出现了AQM,比如RED之类的丢包算法,这样一来就无法区别RED丢包,尾部丢包,线路噪声丢包,乱序未丢包这几类现象了。问题的严重性是由拥塞算法对丢包的敏感性造成的,只要有丢包,或者说仅仅是按照自己的逻辑检测到了可能的丢包,就好像出了大事一般,窗口会大幅度下降!!然而,噪声丢包和乱序并不是拥塞,所以如果能过滤掉这两类,CUBIC的效率一定会有大的提高!
事实上,CUBIC算法没有任何问题,问题出在Linux的TCP实现(其它系统估计也好不到哪去,大家都是仿照BSD实现的)的问题,造成很多时候,CUBIC心有余而力不足,好不容易探测到一个合适的拥塞窗口,被dubious的ACK调用tcp_fastretrans_alert的PRR算法一下子拉下去了,或者直接被定时器超时事件给拉下去...BBR之所以优秀,并不是说其算法优秀,其独到之处在于一切都是它自己来决定的,没有谁能拉低BBR算出来的窗口和发送带宽,除了它自己!所以说,BBR的优秀更多的指的是其框架的优秀。
我不对CUBIC本身进行任何的改造,我只是解放它。首先要做的就是排除假拥塞丢包,要确保进入PRR逻辑的丢包都是由于导致第二类缓存被填满的拥塞避免引起的。至于说非拥塞丢包,继续进入CUBIC逻辑,让CUBIC获取更多的权力。
这里介绍的一种方法是NCL机制。详细文档请参见《 TCP-NCL: A Unified Solution for TCP Packet Reordering and Random Loss》。其基本思想就是,将重传与拥塞控制Alert(即主动的拥塞控制逻辑调用,在Linux中表现为tcp_fastretrans_alert以及tcp_enter_loss)逻辑分离,在确认真的拥塞之前不进入拥塞控制Alert逻辑。NCL是怎么做到的呢?很简单:
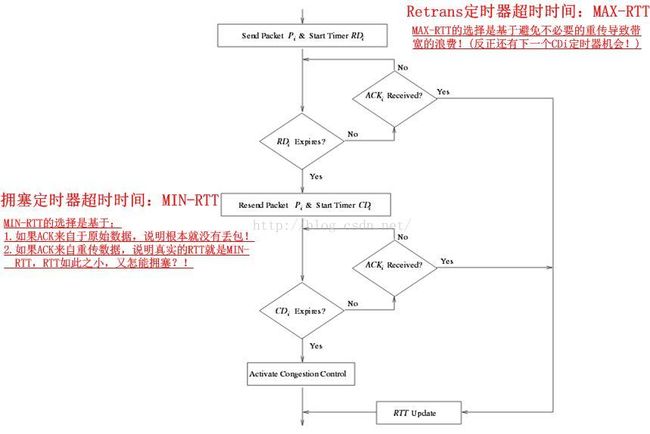
其各个例程的示意图如下:

...
接下来,tcp_time_to_recover的修改就手到擒来了!