java面试总结
https://www.cnblogs.com/aishangJava/p/9865925.html
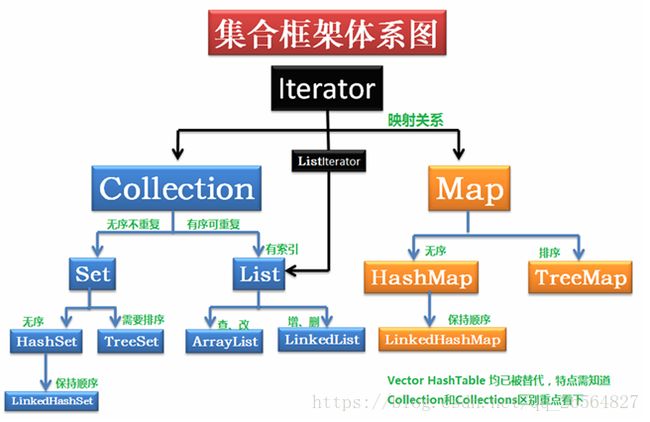
一、Set集合。其主要实现类有HashSet、TreeSet。存放对象的引用,不允许有重复对象。
代码:
public class SetTest {
public static void main(String[] args) {
Set set=new HashSet();
//添加数据
set.add("abc");
set.add("cba");
set.add("abc");//故意重复
set.add(123);
set.add(true);
System.out.println("集合元素个数:"+set.size());
//遍历出集合中每一个元素
Iterator it=set.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
通过java的equals()方法判别。如果有特殊需求须重载equals()方法。
aisy绍
java 常用的三大集合类
一、Set集合。其主要实现类有HashSet、TreeSet。存放对象的引用,不允许有重复对象。
代码:
public class SetTest {
public static void main(String[] args) {
Set set=new HashSet();
//添加数据
set.add("abc");
set.add("cba");
set.add("abc");//故意重复
set.add(123);
set.add(true);
System.out.println("集合元素个数:"+set.size());
//遍历出集合中每一个元素
Iterator it=set.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
通过java的equals()方法判别。如果有特殊需求须重载equals()方法。
1.HashSet(),调用对象的hashCode()方法,获得哈希码,然后再集合中计算存放对象的位置。通过比较哈希码与equals()方法来判别是否重复。所以,重载了equals()方法同时也要重载hashCode()方法。
2.TreeSet(),继承ShortedSet接口,能够对集合中对象排序。默认排序方式是自然排序,但该方式只能对实现了Comparable接口的对象排序,java中对Integer、Byte、Double、Character、String等数值型和字符型对象都实现了该接口。
如果有特殊排序,须重载该接口下的compareTo()方法或通过Comparator接口的实现类构造集合。
二、List集合,其主要实现类有LinkedList、ArrayList,前者实现了链表结构,后者可代表大小可变的数组。List的特点是能够以线性方式储蓄对象,并允许存放重复对象。List能够利用Collections类的静态方法sort排序。sort(List list)自然排序;sort(List listm,Comparator codddmparator)客户化排序。
ArrayList和LinkedList的大致区别如下:
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
代码:
List:线性集合接口,有序;ArrayList:动态数组[可变长度的动态数组];LinkedList:链表结构的集合
public class ListTest {
//ArrayList
static void testOne(){
List list=new ArrayList();
//添加数据
list.add("abc");
list.add("cba");
list.add(123);
list.add(0,"fist");
//查看集合长度
System.out.println("存放"+list.size()+"个元素");
list.remove(0);//删除第一个元素
//查看集合中是否包含cba
if(list.contains("cba")){
System.out.println("包含元素cba");
}
//取出集合中第二个元素
System.out.println("第二个元素是:"+list.get(1));
//取出集合中所有元素
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
//LinkedList
static void testTwo(){
LinkedList list=new LinkedList();
//添加元素
list.add("aaaa");
list.add(123123);
list.addFirst("1111111");
list.addLast("2222222");
list.add("33333333");
System.out.println("元素个数:"+list.size());
//取出第三个元素
System.out.println("第三个元素是:"+list.get(2));
//第一个元素
System.out.println("第一个元素:"+list.getFirst());
System.out.println("最后一个元素:"+list.getLast());
//删除第一个元素
list.removeFirst();
for (Object object : list) {
System.out.println(object);
}
}
public static void main(String[] args) {
//testOne();
testTwo();
}
}
三、Map集合,其主要实现类有HashMap、TreeMap。Map对值没有唯一性要求,对健要求唯一,如果加入已有的健,原有的值对象将被覆盖。HashMap类按照哈希算法来存取键对象,可以重载equals()、hashCode()方法来比较键,但是两者必须一致。TreeMap,可自然排序,也可通过传递Comparator的实现类构造TreeMap。
代码:
Map:键值对存储结构的集合,无序
public class MapTest {
public static void main(String[] args) {
//实例化一个集合对象
Map map=new HashMap();
//添加数据
map.put("P01", "zhangSan");
map.put("P02", "Lucy");
map.put("PSex", "男");
map.put("PAge", "39");
map.put("PAge", "22");//key,重复会被后面的覆盖
//判断是否有一个key为PSex
if(map.containsKey("PSex")){
System.out.println("存在");
}
System.out.println("集合大小:"+map.size());
System.out.println("输出key为PAge的值:"+map.get("PAge"));
//遍历出Map集合中所有数据
Iterator it=map.keySet().iterator();
while(it.hasNext()){
String key=it.next().toString();
System.out.println("key="+key+",value="+map.get(key));
}
/*
Set set=map.keySet();//取出map中所有的key并封装到set集合中
Iterator it=set.iterator();
while(it.hasNext()){
String key=it.next().toString();
System.out.println("key="+key+",value="+map.get(key));
}
*/
}
}
进程和线程的区别
进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
线程:是进程的一个执行单元,是进程内科调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
一个程序至少一个进程,一个进程至少一个线程。
为什么会有线程?
每个进程都有自己的地址空间,即进程空间,在网络或多用户换机下,一个服务器通常需要接收大量不确定数量用户的并发请求,为每一个请求都创建一个进程显然行不通(系统开销大响应用户请求效率低),因此操作系统中线程概念被引进。
- 线程的执行过程是线性的,尽管中间会发生中断或者暂停,但是进程所拥有的资源只为改线状执行过程服务,一旦发生线程切换,这些资源需要被保护起来。
- 进程分为单线程进程和多线程进程,单线程进程宏观来看也是线性执行过程,微观上只有单一的执行过程。多线程进程宏观是线性的,微观上多个执行操作。
线程的改变只代表CPU的执行过程的改变,而没有发生进程所拥有的资源的变化。
进程线程的区别:
- 地址空间:同一进程的线程共享本进程的地址空间,而进程之间则是独立的地址空间。
- 资源拥有:同一进程内的线程共享本进程的资源如内存、I/O、cpu等,但是进程之间的资源是独立的。
一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
进程切换时,消耗的资源大,效率高。所以涉及到频繁的切换时,使用线程要好于进程。同样如果要求同时进行并且又要共享某些变量的并发操作,只能用线程不能用进程
- 执行过程:每个独立的进程程有一个程序运行的入口、顺序执行序列和程序入口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
- 线程是处理器调度的基本单位,但是进程不是。
- 两者均可并发执行。
优缺点:
线程执行开销小,但是不利于资源的管理和保护。线程适合在SMP机器(双CPU系统)上运行。
进程执行开销大,但是能够很好的进行资源管理和保护。进程可以跨机器前移。
何时使用多进程,何时使用多线程?
对资源的管理和保护要求高,不限制开销和效率时,使用多进程。
要求效率高,频繁切换时,资源的保护管理要求不是很高时,使用多线程。
线程的生命周期及五种基本状态:
Java线程具有五中基本状态
新建状态(New):当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread();
就绪状态(Runnable):当调用线程对象的start()方法(t.start();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行;
运行状态(Running):当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就 绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
阻塞状态(Blocked):处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才 有机会再次被CPU调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
1.等待阻塞:运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
2.同步阻塞 -- 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
3.其他阻塞 -- 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
sleep和wait的区别:
首先要明确,wait是Object类的方法,也就是说,所有的对象都有wait方法,而且都是Object中的wait方法因为wait方法被标为final无法被重写,源码如下:
[java] view plain copy
public final native void wait(long timeout) throws InterruptedException;
native关键字修饰,表示这个方法使用其他语言实现,又由java由C编写可得,这个方法做了很可能是C与操作系统级别的交互。抛出InterruptedException,表示线程可能由已经终止的风险。
sleep与wait,在非多线程运行条件下的情况是一样的,都是当前线程让出执行机会,进入休眠/等待。但是在synchronized中就有一些不一样了:
1.wait会释放同步锁,让其他线程进入synchronized代码块执行。sleep不会释放锁,其他线程只能等待在synchronized代码块中进入sleep的线程醒后执行完毕才能竞争持有锁。
2.wait可以被notify/notifyAll等方法唤醒,继续竞争CPU和锁。sleep方法只能等待线程睡眠时间到继续运行。
如何保证线程安全的问题,线程安全是什么:
既然是线程安全问题,那么毫无疑问所有的隐患都是出现在多个线程访问的情况下产生的,也就是我们要确保在多条线程访问的时候,我们的程序还能按照我们预期的行为去执行。
既然存在线程安全的问题,那么肯定得想办法解决这个问题,怎么解决?我们说说常见的几种方式。
1、synchronized
synchronized关键字,就是用来控制线程同步的,保证我们的线程在多线程环境下,不被多个线程同时执行,确保我们数据的完整性,使用方法一般是加在方法上。
这样就可以确保我们的线程同步了,同时这里需要注意一个大家平时忽略的问题,首先synchronized锁的是括号里的对象,而不是代码,其次,对于非静态的synchronized方法,锁的是对象本身也就是this。
当synchronized锁住一个对象之后,别的线程如果想要获取锁对象,那么就必须等这个线程执行完释放锁对象之后才可以,否则一直处于等待状态。
注意点:虽然加synchronized关键字,可以让我们的线程变得安全,但是我们在用的时候,也要注意缩小synchronized的使用范围,如果随意使用时很影响程序的性能,别的对象想拿到锁,结果你没用锁还一直把锁占用,这样就有点浪费资源。
2、Lock
先来说说它跟synchronized有什么区别吧,Lock是在Java1.6被引入进来的,Lock的引入让锁有了可操作性,什么意思?就是我们在需要的时候去手动的获取锁和释放锁,甚至我们还可以中断获取以及超时获取的同步特性,但是从使用上说Lock明显没有synchronized使用起来方便快捷。进入方法我们首先要获取到锁,然后去执行我们业务代码,这里跟synchronized不同的是,Lock获取的所对象需要我们亲自去进行释放,为了防止我们代码出现异常,所以我们的释放锁操作放在finally中,因为finally中的代码无论如何都是会执行的。其实在Lock还有几种获取锁的方式,我们这里再说一种,就是tryLock()这个方法跟Lock()是有区别的,Lock在获取锁的时候,如果拿不到锁,就一直处于等待状态,直到拿到锁,但是tryLock()却不是这样的,tryLock是有一个Boolean的返回值的,如果没有拿到锁,直接返回false,停止等待,它不会像Lock()那样去一直等待获取锁。
Java中的equals和==
1)对于==,如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等;
如果作用于引用类型的变量,则比较的是所指向的对象的地址
2)对于equals方法,注意:equals方法不能作用于基本数据类型的变量
如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;
诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。
浅谈HashMap 的底层原理:
https://blog.csdn.net/a2524289/article/details/78888480