1 意义
1.1 分层的 APIs & 抽象层次
Flink提供三层API。 每个API在简洁性和表达性之间提供不同的权衡,并针对不同的用例。
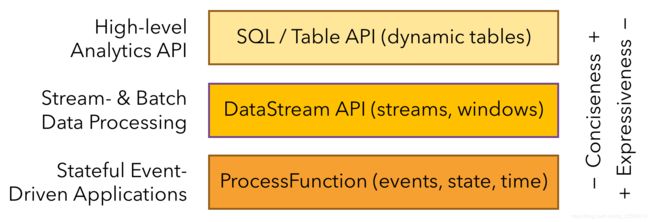
而且Flink提供不同级别的抽象来开发流/批处理应用程序
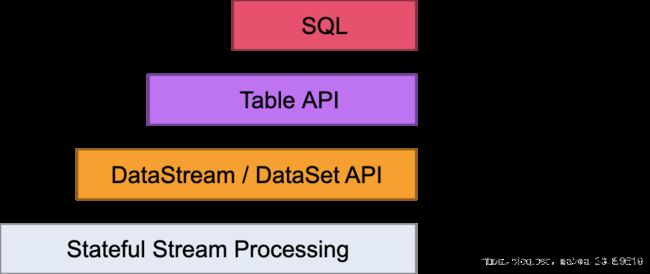
- 最低级抽象只提供有状态流。它通过Process Function嵌入到DataStream API中。它允许用户自由处理来自一个或多个流的事件,并使用一致的容错状态。此外,用户可以注册事件时间和处理时间回调,允许程序实现复杂的计算。
- 实际上,大多数应用程序不需要上述低级抽象,而是针对Core API编程, 如DataStream API(有界/无界流)和DataSet API (有界数据集)。这些流畅的API提供了用于数据处理的通用构建块,例如各种形式的用户指定的转换,连接,聚合,窗口,状态等。在这些API中处理的数据类型在相应的编程语言中表示为类。
低级Process Function与DataStream API集成,因此只能对某些 算子操作进行低级抽象。该数据集API提供的有限数据集的其他原语,如循环/迭代。 - 该 Table API 是为中心的声明性DSL 表,其可被动态地改变的表(表示流时)。该 Table API遵循(扩展)关系模型:表有一个模式连接(类似于在关系数据库中的表)和API提供可比的 算子操作,如选择,项目,连接,分组依据,聚合等 Table API程序以声明方式定义应该执行的逻辑 算子操作,而不是准确指定 算子操作代码的外观。虽然 Table API可以通过各种类型的用户定义函数进行扩展,但它的表现力不如Core API,但使用更简洁(编写的代码更少)。此外, Table API程序还会通过优化程序,在执行之前应用优化规则。
可以在表和DataStream / DataSet之间无缝转换,允许程序混合 Table API以及DataStream 和DataSet API。 - Flink提供的最高级抽象是SQL。这种抽象在语义和表达方面类似于 Table API,但是将程序表示为SQL查询表达式。在SQL抽象与 Table API紧密地相互作用,和SQL查询可以通过定义表来执行 Table API。1.2 模型类比MapReduce ==> Hive SQL
Spark ==> Spark SQL
Flink ==> SQL
2 总览
2.1 简介
Apache Flink具有两个关系型API
- Table API
- SQL
用于统一流和批处理
Table API是Scala和Java语言集成查询API,可以非常直观的方式组合来自关系算子的查询(e.g. 选择,过滤和连接).
Flink的SQL支持基于实现SQL标准的Apache Calcite。无论输入是批输入(DataSet)还是流输入(DataStream),任一接口中指定的查询都具有相同的语义并指定相同的结果。
Table API和SQL接口彼此紧密集成,就如Flink的DataStream和DataSet API。我们可以轻松地在基于API构建的所有API和库之间切换。例如,可以使用CEP库从DataStream中提取模式,然后使用 Table API分析模式,或者可以在预处理上运行Gelly图算法之前使用SQL查询扫描,过滤和聚合批处理表数据。
Table API和SQL尚未完成并且正在积极开发中。并非 Table API,SQL和stream,batch输入的每种组合都支持所有算子操作
2.2 依赖结构
所有Table API和SQL组件都捆绑在flink-table Maven工件中。
以下依赖项与大多数项目相关:
- flink-table-common
通过自定义函数,格式等扩展表生态系统的通用模块。 - flink-table-api-java
使用Java编程语言的纯表程序的表和SQL API(在早期开发阶段,不推荐!)。 - flink-table-api-scala
使用Scala编程语言的纯表程序的表和SQL API(在早期开发阶段,不推荐!)。 - flink-table-api-java-bridge
使用Java编程语言支持DataStream / DataSet API的Table&SQL API。 - flink-table-api-scala-bridge
使用Scala编程语言支持DataStream / DataSet API的Table&SQL API。 - flink-table-planner
表程序规划器和运行时。 - flink-table-uber
将上述模块打包成大多数Table&SQL API用例的发行版。 uber JAR文件flink-table * .jar位于Flink版本的/ opt目录中,如果需要可以移动到/ lib。
2.3 项目依赖
必须将以下依赖项添加到项目中才能使用Table API和SQL来定义管道:
org.apache.flink
flink-table-planner_2.11
1.8.0
此外,根据目标编程语言,您需要添加Java或Scala API。
org.apache.flink
flink-table-api-java-bridge_2.11
1.8.0
org.apache.flink
flink-table-api-scala-bridge_2.11
1.8.0
在内部,表生态系统的一部分是在Scala中实现的。 因此,请确保为批处理和流应用程序添加以下依赖项:
org.apache.flink
flink-streaming-scala_2.11
1.8.0
2.4 扩展依赖
如果要实现与Kafka或一组用户定义函数交互的自定义格式,以下依赖关系就足够了,可用于SQL客户端的JAR文件:
org.apache.flink
flink-table-common
1.8.0
目前,该模块包括以下扩展点:
- SerializationSchemaFactory
- DeserializationSchemaFactory
- ScalarFunction
- TableFunction
- AggregateFunction
3 概念和通用API
Table API和SQL集成在一个联合API中。此API的核心概念是Table用作查询的输入和输出。本文档显示了具有 Table API和SQL查询的程序的常见结构,如何注册Table,如何查询Table以及如何发出Table。
3.1 Table API和SQL程序的结构
批处理和流式传输的所有 Table API和SQL程序都遵循相同的模式。以下代码示例显示了 Table API和SQL程序的常见结构。
// 对于批处理程序,使用ExecutionEnvironment而不是StreamExecutionEnvironment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建一个TableEnvironment
// 对于批处理程序使用BatchTableEnvironment而不是StreamTableEnvironment
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 注册一个 Table
tableEnv.registerTable("table1", ...) // 或者
tableEnv.registerTableSource("table2", ...); // 或者
tableEnv.registerExternalCatalog("extCat", ...);
// 注册一个输出 Table
tableEnv.registerTableSink("outputTable", ...);
/ 从 Table API query 创建一个Table
Table tapiResult = tableEnv.scan("table1").select(...);
// 从 SQL query 创建一个Table
Table sqlResult = tableEnv.sqlQuery("SELECT ... FROM table2 ... ");
// 将表API结果表发送到TableSink,对于SQL结果也是如此
tapiResult.insertInto("outputTable");
// 执行
env.execute();3.2 将DataStream或DataSet转换为表
它也可以直接转换为a 而不是注册a DataStream或DataSetin 。如果要在 Table API查询中使用Table,这很方便。TableEnvironmentTable
// 获取StreamTableEnvironment
//在BatchTableEnvironment中注册DataSet是等效的
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStream> stream = ...
// 将DataStream转换为默认字段为“f0”,“f1”的表
Table table1 = tableEnv.fromDataStream(stream);
// 将DataStream转换为包含字段“myLong”,“myString”的表
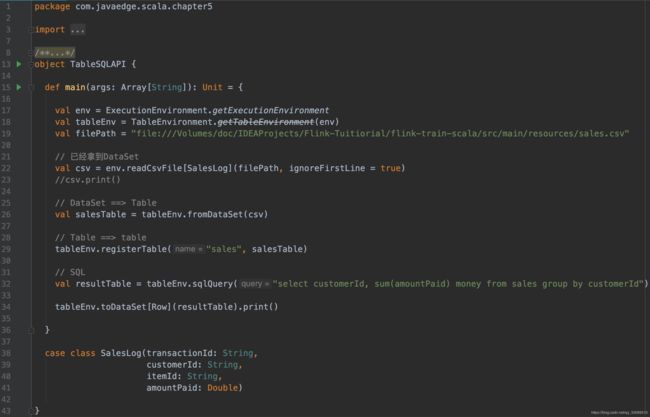
Table table2 = tableEnv.fromDataStream(stream, "myLong, myString"); - sale.csv文件

- Scala
- Java
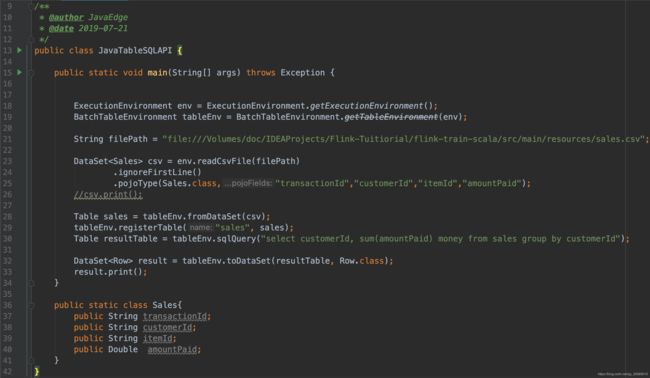
还不完善,等日后Flink该模块开发完毕再深入研究!
参考
Table API & SQL