这里简单用三台虚拟机,搭建了一个两个数据节点的hadoop机群,仅供新人学习。零零碎碎,花了大概一天时间,总算完成了。
环境
-
Linux版本:CentOS 6.5
-
VMware虚拟机
-
jdk1.6.0_45
主要分为一下几步完成
一、安装CentOS 6.5
当然了,如果没有虚拟机,需要先安装VMware,然后新建虚拟机,选择系统镜像即可,复制几台,比如我的机器4G内存,最多复制两台,一共三台。
建议这时候把所有机器进入管理员root权限:
[root@blue bin]#su
输入密码即可
二、修改IP
复制的三台机器ip一样的,需要配置/etc/sysconfig/network-scripts/ifcfg-eth0文件,有几台修改几次,vim命令打开:
[root@blue bin]#vim /etc/sysconfig/network-scripts/ifcfg-eth0
修改为:
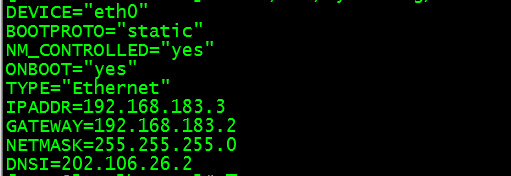
主机修改为:192.168.183.3
三台机器ip随便都行,比如改为
192.168.183.3
192.168.183.4
192.168.183.5
三、免登陆
我们需要让三台机器能互相进入、控制对方。
1、配置hostname
[root@blue bin]#vim /etc/hosts

所有机器都得有,所以可以直接复制过去
[root@blue bin]#scp -rp /etc/hosts 192.168.183.4:/etc
[root@blue bin]#scp -rp /etc/hosts 192.168.183.5:/etc
2、配置network文件
[root@blue bin]#vim /etc/sysconfig/network
编辑HOSTNAME的值,就是给机器取名字:
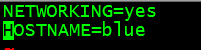
另外两台机器也要编辑network文件,比如三台机器分别取名blue、blue2、blue3。
重启机器,命令输入hostname:
就会出现刚才设置的名字.
四、生成key
1、Ssh-keygen命令
[root@blue bin]#ssh-keygen
会生成文件,保存在/root/.ssh/id_rsa,到时候会有提示的,里面有cat id_rsa.pub这个文件。
2、对于blue这台机器:
[root@blue bin]#cat id_rsa.pub > authorized_keys
生成authorized_keys文件
在blue2、blue3都执行
[root@blue bin]#ssh-keygen命令
会生成同样文件,里面包含了控制该机器的钥匙信息
打开blue2、blue3的id_rsa.pub文件会有形如下面内容,

鼠标选中(自动进入剪贴板),粘贴到blue机器的authorized_keys文件里面,这样blue(主机)的authorized_keys里面就是三台机器的钥匙,有了钥匙,就可以访问了。
authorized_keys里面是这样:

3、复制钥匙
把authorized_keys文件远程复制到blue2、blue3机器里面,这样每台机器都有其它机器和自己的钥匙了。
[root@blue bin]#scp –r authorized_keys 192.168.183.4:~/.ssh
[root@blue bin]#scp –r authorized_keys 192.168.183.4:~/.ssh
4、检查
对于blue:
[root@blue bin]#ssh blue2
[root@blue bin]#ssh blue3
会发现不需要密码,如果还需要密码,那就失败了。重新检查,大不了从头再来。
对于另外两台机器blue2、blue3也同样ssh命令检查,不需要密码,就ok!
五、Hadoop环境配置
1、关闭防火墙
这就需要关闭三台机器防火墙:
关闭:[root@blue bin]#service iptables stop
检查:[root@blue bin]#iptables –L
会出现:
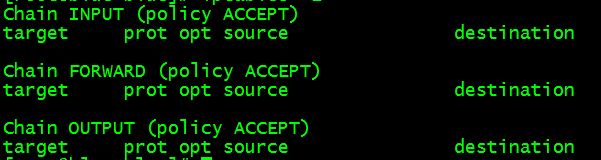
表明防火墙成功关闭
2、安装hadoop
在blue机器里面操作
保存hadoop文件,这里是压缩包,放到共享目录里面,将其复制到虚拟机blue的/usr/local/src文件夹下面
[root@blue bin]#cp /mnt/hgfs/share/hadoop-1.2.1-bin.tar.gz /usr/local/src
然后进入虚拟机的/usr/local/src下面:
解压文件
[root@blue bin]#tar -xzvf hadoop-1.2.1-bin.tar.gz
3、修改配置文件
进入/usr/local/src/hadoop-1.2.1/conf文件夹,下面有需要配置的文件
(1)、修改masters文件
修改为:blue
(2)、修改slaves文件
修改为:
blue2
Blue3
(3)、修改core-site.xml文件
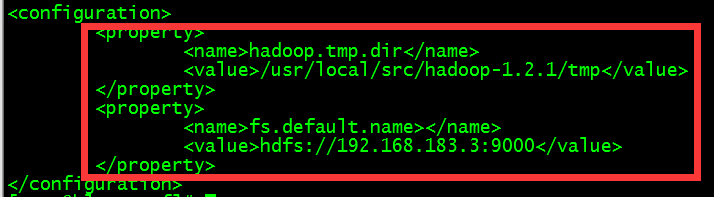
(4)、修改mapred-site.xml

(5)、修改hdfs-site.xml
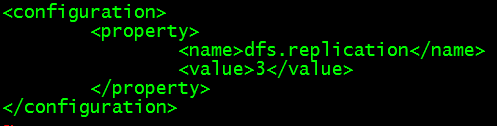
(6)、配置环境修改文件hadoop-env.sh
I:安装java
由于hadoop是基于java的,这里安装java,并且配置JAVA_HOME环境变量
修改这个文件:
[root@blue bin]#vim ~/.bashrc
如下
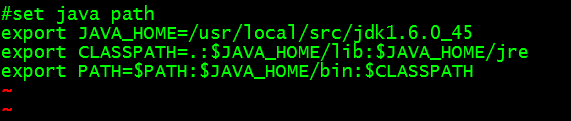
JAVA_HOME值就是jdk的安装路径,这里安装在/usr/local/src下面
Ii:[root@blue bin]#source ~/.bashrc 刷新文件,因为刚才修改过,除非重启,
命令:
[root@blue bin]#Java
如果出现一些信息,表明配置java环境成功!
Iii:[root@blue bin]#vim Hadoop-env.sh
末尾加一行
export JAVA_HOME= /usr/local/src/jdk1.6.0_45
以上几步需要细心,保证不敲错一个字符!
4、复制hadoop到另外两台机器blue2、blue3
[root@blue bin]#scp -rp /usr/local/src/hadoop-1.2.1 192.168.183.4:/usr/local/src
或者:
[root@blue bin]#scp -rp /usr/local/src/hadoop-1.2.1 blue2:/usr/local/src
因为配置了network文件,每台机器ip与hostname唯一对应,并且重启生效了,所以用ip与名字是一样的,如果没有重启,需要设置临时名字:
[root@blue bin]#hostname blue
[root@blue bin]#hostname blue2
[root@blue bin]#hostname blue3
[root@blue bin]#scp -rp /usr/local/src/hadoop-1.2.1 192.168.183.5:/usr/local/src
或者:
[root@blue bin]#scp -rp /usr/local/src/hadoop-1.2.1 blue3:/usr/local/src
建议这里再检查一下三台机器的防火墙是否关了,命令:
[root@blue bin]#Setenforce 0
[root@blue bin]#Getenforce
如果出现Permissive,表明关掉了,否则service iptables stop关掉防火墙。
5、格式化节点
进入目录:
[root@blue bin]#cd /usr/local/src/hadoop-1.2.1/bin
执行hadoop命令:
[root@blue bin]#./hadoop namenode –format
6、启动hadoop
[root@blue bin]#./start-all.sh
7、这时执行命令:
首先在父亲(blue)里面,如果父亲都有问题,肯定有问题。
[root@blue bin]#jps

出现的四个与上面图片的必须一样,否则表明有前面的5个配置文件有问题,返回去检查。
如果没有问题,再对blue2、blue3两台机器执行命令:
[root@blue bin]#jps
哈哈,会发现错误:bash:jps:command not found
其实是不能发现java的环境变量,前面只配置了父亲blue的java环境变量。
需要把主机blue的环境变量文件.bashrc复制到两台孩子机器blue2、blue3的对应位置下面,覆盖原有的.bashrc文件。需要三台机器jdk位置安装一样哦,这里前面都统一安装在/usr/local/src目录下面。
[root@blue bin]#scp -rp ~/.bashrc blue2:~/
[root@blue bin]#scp -rp ~/.bashrc blue3:~/
还要分别在blue2、blue3里面,记得source ~/.bashrc,重新加载文件,才能生效
8、停止hadoop
[root@blue bin]#./stop-all.sh
继续5、6步,即在blue里面的hadoop的bin目录下面,这里所有执行的文件都在bin目录,下面。
然后在孩子节点机器blue2、blue3命令:
[root@blue bin]#jps:
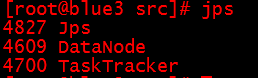
英文意思是:4609数据节点、4700任务节点
出现的三个必须一样,否则表明前面的5个配置文件有问题,返回去检查。然后重复8——5——6——7步骤。
如果不出意外,按照这种步骤是可以配置成功的!