1.下载源码:
开源代码地址:https://github.com/deepinsight/insightface
2.查看作者项目训练要求
(1)训练数据
训练数据使用作者提供并制作好的数据,如下图所示:
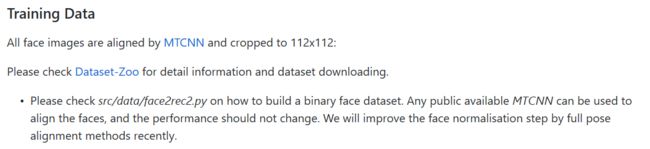
点击Dataset-Zoo进入数据下载中心,如下图所示:
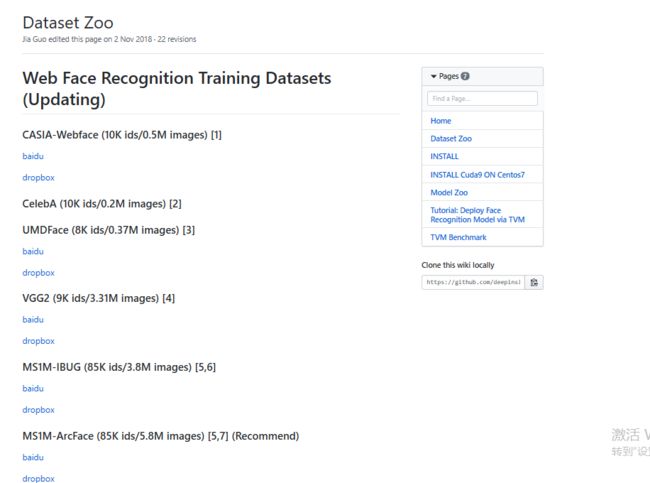
本人训练数据为MS1M-ArcFace,选择自己想要训练的数据都可以。
(2)训练要求如下图所示:
a.

由于在本地配置环境问题比较多,本人直接拉取mxnet-cu90镜像,省去好多麻烦事,可参考我的博客https://www.cnblogs.com/liuwenhua/p/11537696.html,有详细解读。
b.下载代码放到自己的目录下:

c.数据解读:

根据作者要求把下载数据放到datastes目录下,六个文件中前三个是训练数据需求,后三个是验证数据。
打开文件property,如下图:
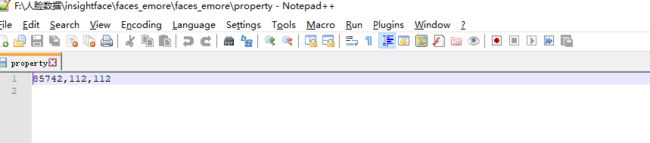
85742为类别数,根据不同数据需要更改代码,后续提到。112,112为图片大小。
d.ubuntu环境设置及代码编辑
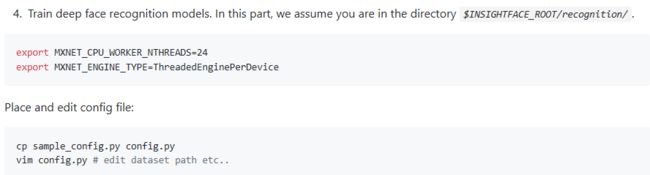
具体方法如下:
创建sh文件:进入到recognition,编辑
vim run_train.sh
编辑下面两行代码
export MXNET_CPU_WORKER_NTHREADS=24
export MXNET_ENGINE_TYPE=ThreadedEnginePerDevice
执行命令如下:
cp sample_config.py config.py
vim config.py
显示如下图所示:

根据自己的下载的数据或制作的数据需要添加代码在dataset =edict()下面
dataset.emore = edict() dataset.emore.dataset = 'emore' dataset.emore.dataset_path = '../datasets/faces_emore' dataset.emore.num_classes = 85742 dataset.emore.image_shape = (112,112,3) dataset.emore.val_targets = ['lfw', 'cfp_fp', 'agedb_30']
①更改的第一个就是上面的emore,根据自己的喜好
②更改dataset.emore.dataset_path路径
③dataset.emore.num_classes,训练数据的类别数
(3)开始训练

我的设备是两块RTX2080ti,运行代码如下:
CUDA_VISIBLE_DEVICES='0,1' python -u train.py --network r100 --loss arcface --dataset emore
由于在运行过程中提示显存不足,所以要设置bach_size,为了方便运行,我们添加下面代码到run_train.sh文件中
export MXNET_CPU_WORKER_NTHREADS=24 export MXNET_ENGINE_TYPE=ThreadedEnginePerDevice CUDA_VISIBLE_DEVICES='0,1' python -u train.py --network r100 --loss arcface --dataset emore --per-batch-size 36
保存退出,在终端运行
bash run_train.sh
模型开始训练,如下图:
后续准备制作自己的训练数据,后续更新