本文中,我们将对ZooKeeper进行介绍。简单地说,ZooKeeper是一个用来在构成应用的各个子服务之间进行协调的一个服务。
由于其本身并没有特别复杂的机制,因此我们将会把更多的笔墨集中在如何对ZooKeeper进行使用方面。当然,这也是和其它博文所略有不同的地方,否则我也不会花费时间去写这这篇博客。
ZooKeeper简介
我们已经在前面一系列和集群相关的博文中提到过,一个大型服务常常是由一系列子服务共同组成的。这些服务常常包含一系列动态的配置,以告知子服务当前程序运行环境的变化。那么我们需要怎样完成配置的更新呢?这些配置的更改到底是由谁来发起?如果有多个发起方同时对同一配置进行更改,那么各个不同子服务接收到消息的先后顺序将有所不同,进而导致各个子服务内部的动态配置互不相同。这一系列问题我们应该如何解决?
答案就是我们要讲解的ZooKeeper。ZooKeeper允许我们将数据组织成为一个类似于文件系统的数据结构。通过数据结点所在的地址,我们可以访问数据结点中所包含的数据:
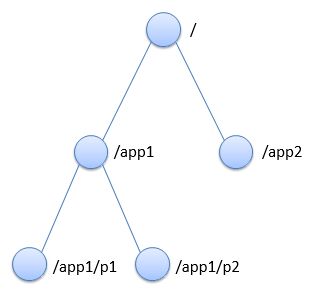
为了使用ZooKeeper,我们的各个子服务需要通过一个客户端与ZooKeeper连接,并通过一系列API调用执行对数据的读写操作。而为了解决前面所提到的一系列和配置管理相关的问题,ZooKeeper提供了如下一系列特性:
- Wait free:其表示ZooKeeper的API并没有使用阻塞原语(blocking primitive)。这是因为阻塞原语常常会导致死锁,程序运行缓慢等一系列问题。该非阻塞特性也允许客户端同时发送几个消息来执行并行的修改。
- 请求的线性有序执行:由于wait free特性会导致各个客户端之间的相互协作出现问题,如处理多个写入请求时的写写冲突以及在写入请求被阻塞时对数据的读取所产生的读写冲突等。为了解决这个问题,ZooKeeper的内部实现保证了在同一客户端的所有的操作都是FIFO的,并且ZooKeeper服务中所有的写入都是按照线性的方式来执行的。同时ZooKeeper中的数据还存在着version的概念,从而帮助保证写入的安全。
- 数据缓存在客户端:为了提高读操作的运行性能,ZooKeeper会尝试将数据缓存在客户端。为了保证数据的一致性,各个客户端可以使用一个watch机制来添加对特定数据变动的侦听。
下面就让我们依次对这些特性进行讲解。
首先就是wait free特性。让我们想象一种情况,那就是对多条配置项的同时改写。如果每次调用都需要等待所有更改完成,那么整个更新的过程将变得非常缓慢:
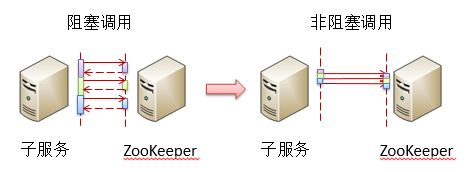
从上图中可以看到,一个非阻塞调用可以直接返回,从而可以消除因为等待响应所导致的阻塞,显著地提高子服务的运行效率。这种效率的提高在同时更改多个配置时非常显著。由此ZooKeeper所提供的API主要分为阻塞和非阻塞两种。
接下来就是各个请求的FIFO执行以及线性读写。其实如果您做过多线程,这种保证非常容易理解。假设现在执行了两个写入请求,那么写入的先后顺序不同可能导致运行结果不同:
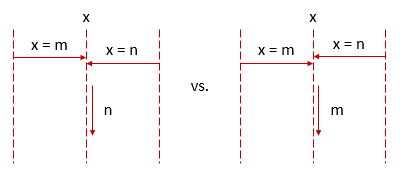
而这种先后顺序变化很有可能是由于网络延迟所导致的。试想一下,如果我们在非阻塞模式中使用了同一客户端插入了对同一个配置的两个写入操作,那么我们就需要保证后一个写入操作是有效的,而且再次读取一定能读取后一个写入操作所写入的值。在version的帮助下,我们可以避免计划外写入,而单一客户端的请求会按照FIFO顺序执行的则可以用来保证写入请求后的读取会读取最后写入的值。这也是ZooKeeper能够提供异步模式的基础。
而为了提高读写速度,ZooKeeper会在客户端保存数据的缓存。这样就可以使得对数据的重复使用不再需要从ZooKeeper服务中重复读取。而为了保证客户端缓存和ZooKeeper服务记录的数据一致,ZooKeeper使用了了一种被称为watch的机制:如果一个客户端发送一个请求,并在该请求中设置了watch标记,那么该客户端就会在该数据上建立watch机制。一旦该结点所记录的数据发生了变化,那么它将向客户端发送一个消息以通知该数据已经失效。该通知只声明相应的数据发生了更改 ,却不会指出到底更改为哪个值。如果客户端需要读取更新的值,那么它就需要重新执行一次读取,并在该请求中决定到底是否再次通过watch标记继续侦听。也就是说,watch机制是一种一次性的机制。其运行机制大致如下图所示:
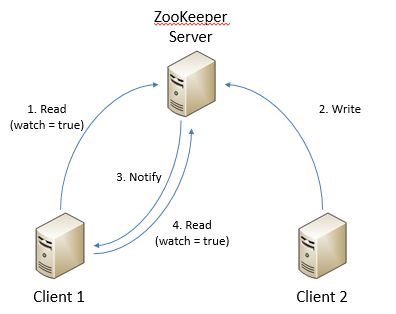
而另一个使watch机制失效的便是会话结束。这抑或是子服务自动退出服务等正常业务逻辑执行(例如在使用Amazon的Spot Instance时会常常遇到这种情况),或者是子服务失效等非正常情况。
除此之外,ZooKeeper还有一个比较重要的概念就是数据的版本。相信使用过乐观锁等机制的读者都应该知道,版本实际上就是为了防止过期数据的。而且我们也在刚刚的讲解中提到过版本的作用,因此在这里不做详述。
由于ZooKeeper常常管理着整个集群中所有的动态配置信息,因此它自身已经包含了高可用性设计。通常情况下,ZooKeeper的高可用性常常是通过多个服务实例来完成的。不同的客户端可能连接到不同的服务实例上:

这些服务实例中,一个服务器将扮演leader角色,而其它服务实例将扮演follower角色。在一个读请求到达时,任何服务实例将可以直接将其所记录的数据返回。而在需要写入数据的时候,接收到写入请求的服务实例会将该请求转向ZooKeeper的leader,然后再由follower来对数据进行更新:
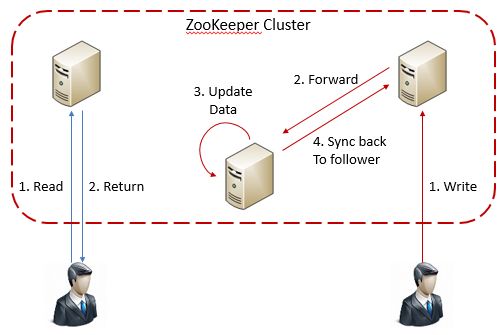
而为了能从失效状态恢复,ZooKeeper会定期保存数据的快照,并记录对数据的操作日志。如果一个ZooKeeper实例失效,那么我们就可以通过选取最近的Snapshot并重新执行相应的操作日志来完成该实例的恢复。
这里有一个问题,那就是leader是如何决定的,以及在leader失效时如何得到新的leader。这一切都是通过其内置的选举协议来完成的。一种说法是,leader的选举是按照一种特殊的Quorum选举方式,Simple Majority Quorums来完成的。简单地说,其表示绝大多数结点同意的选举方式。而另一种说法则是按照Paxos协议族来完成的。不管怎样,您只要知晓ZooKeeper中有一个leader即可。
最后要说的一点就是数据结点的类型。在ZooKeeper中,数据结点主要分为两种类型:Regular以及Ephemeral。Regular结点需要通过客户端显式地创建及删除,而Ephemeral结点则会在会话结束之时即被销毁。
OK。现在呢,基本上所有的基础机制都已经介绍完毕了。那么在本节最后,就让我们来看看ZooKeeper所提供的一系列API。在这里,我们并不区分API是同步的还是异步的:
- create(path, data, flags):在特定路径下创建一个结点。我们可以通过flags控制结点是否在会话结束时被移除等一系列行为
- getData(path, watch):获得特定路径下结点的数据,并通过watch参数来决定是否启用watch机制。
- setData(path, data, version):设置特定路径下结点的数据。其通过传入的version来决定是否发出请求的客户端拥有最新的数据。如果不是,那么该请求被认为是非正确的并不被执行。
- getChildren(path, watch):获得特定路径下的所有子结点。
- getACL(path, version):获取结点所拥有的ACL。
- setACL(path, acls, version):设置结点的ACL,以控制对它的访问。
- sync():等待对客户端所连接结点的更新完毕。
- delete(path, version):删除特定路径下的结点。通过传入的version来决定是否发出请求的客户端拥有最新的数据。如果不是,那么该请求被认为是非正确的并不被执行。
ZooKeeper使用示例
在了解了ZooKeeper的使用之后,我们现在就以一个简单的示例来看看到底如何使用ZooKeeper。
在《On cloud, be cloud native》一文中,我们穿插着介绍了Amazon所提供的一系列服务。其中两个重要的服务就是AMI和Auto Scaling Group。两者组合可以制定出高效的可扩展(Scalability,我更倾向“伸缩”一词),高可用集群。在启动时,Auto Scaling Group会使用指定的AMI创建虚拟机实例并执行动态脚本对创建好的虚拟机进行配置。这其中就包括从ZooKeeper中读取作为动态脚本输入的动态配置信息:
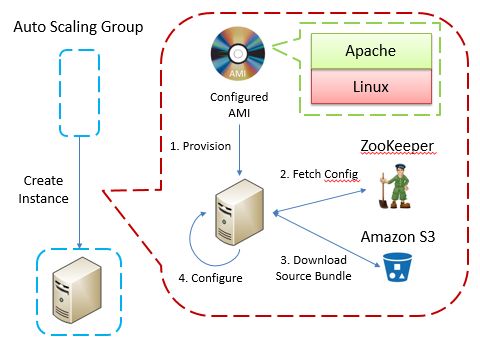
从上图中可以看到,在程序启动时,其将直接从ZooKeeper中直接读取已经放置在特定位置的配置文件。该配置文件中记录了虚拟机实例所需要运行的代码在S3上的地址。接下来,虚拟机实例将会从Amazon S3中下载并部署这些代码,并动态地对虚拟机进行配置。而在该读取配置的过程中,新创建的虚拟机实例将会把watch选项设置为true。
而在程序运行一段时间后,我们可能就需要对该Auto Scaling Group所承载的服务进行升级。此时我们首先需要将更新后的Source Bundle放置在Amazon S3上,并更新ZooKeeper中所记录的配置。由于之前在创建虚拟机时我们已经将watch选项设置为true,因此该配置更改会发送一条通知到Auto Scaling Group中的各个虚拟机实例之上。接下来,这些虚拟机通过向Auto Scaling Group发送Detach消息从该Auto Scaling Group移除。在该Detach消息中,我们应选择保持Auto Scaling Group容量不变这一选项。这样做的结果就是,Auto Scaling Group将会使用新的配置重新创建一台新的虚拟机。这样我们只需要对配置进行更改,而其它的一切工作都由Amazon的各种自动化功能自行完成。
这个流程中有一个问题,那就是我们要能够保证整个应用能持续地提供服务(假设更新后的服务逻辑具有后向兼容性)。当配置更改消息发送到各个虚拟机时,它们可能都会开始尝试从Auto Scaling Group移除,从而导致Auto Scaling Group的容量快速下降,进而导致整个应用无法提供服务。而解决方案便是通过ZooKeeper实现互斥锁的功能,从而使得Auto Scaling Group中的各个实例的移除是逐个进行的。
基于ZooKeeper的互斥锁的实现非常简单:创建一个“lock file”即可。这种方法实际上在很多软件中被使用。例如最常见的就是Git。其原理很简单,那就是尝试创建一个文件。如果文件创建成功,那么其就是得到了锁。而如果由于文件已经存在而创建失败,那么就是没有得到锁。而在基于ZooKeeper的互斥锁实现中,我们尝试创建的则是一个结点:为了获得锁,ZooKeeper的客户端会尝试在特定路径下创建一个Ephemeral结点。如果其创建成功,那么它就可以得到该锁。而其它各个没有成功获得锁的实例将通过发送一个读请求并标示watch标志来侦听该结点的变化。一旦拥有锁的实例发现Auto Scaling Group已经创建好了新的虚拟机,那么它就可以向ZooKeeper发送请求删除该文件。此时其它等待的实例将得到通知并再次尝试获得锁。
那么拥有锁的实例是如何得知新的虚拟机已经创建完毕了呢?其使用的就是ZooKeeper的另外一种常见使用方法:Group Membership。在ZooKeeper中,我们可以创建一个结点,并在它之下添加/删除子结点。而在父结点进行监听的客户端将由于子结点的增删得到通知消息。在得到通知之后,其就可以通过getChildren()函数得到所有的子结点。也就是说,在得到锁并将自身移出Auto Scaling Group的虚拟机实例可以首先通过getChildren()函数添加对Auto Scaling Group所对应结点的监听。在新的虚拟机实例创建完毕并添加到Auto Scaling Group中后,其将向Auto Scaling Group所对应的结点添加一个子结点,从而通知原本移出Auto Scaling Group的虚拟机实例新的虚拟机实例已经创建完毕。那么原虚拟机实例就可以释放互斥锁,从而使得下一个虚拟机开始执行替换的步骤。
通过该互斥锁实现,我们能够让Auto Scaling Group中的各虚拟机实例逐个移除并替换。当然啊,网络上还有很多种对ZooKeeper的精妙使用。这里就不再一一赘述了。
转载请注明原文地址并标明转载:http://www.cnblogs.com/loveis715/p/5185796.html
商业转载请事先与我联系:[email protected]
公众号一定帮忙别标成原创,因为协调起来太麻烦了。。。