Copyright © Microsoft Corporation. All rights reserved.
适用于License版权许可
更多微软人工智能学习资源,请见微软人工智能教育与学习共建社区
- Content
- 01.0-神经网络的基本工作原理
- 01.1-基本数学导数公式
- 01.2-Python-Numpy库的点滴
- 02.0-反向传播与梯度下降
- 02.1-线性反向传播
- 02.2-非线性反向传播
- 02.3-梯度下降
- 03.0-损失函数
- 03.1-均方差损失函数
- 03.2-交叉熵损失函数
- 04.0-单入单出单层-单变量线性回归
- 04.1-最小二乘法
- 04.2-梯度下降法
- 04.3-神经网络法
- 04.4-梯度下降的三种形式
- 04.5-实现逻辑非门
- 05.0-多入单出单层-多变量线性回归
- 05.1-正规方程法
- 05.2-神经网络法
- 05.3-样本特征数据的归一化
- 05.4-归一化的后遗症
- 05.5-正确的推理方法
- 05.6-归一化标签值
- 06.0-多入多出单层神经网络-多变量线性分类
- 06.1-二分类原理
- 06.2-线性二分类实现
- 06.3-线性二分类结果可视化
- 06.4-多分类原理
- 06.5-线性多分类实现
- 06.6-线性多分类结果可视化
- 07.0-激活函数
- 07.1-挤压型激活函数
- 07.2-半线性激活函数
- 07.3-用双曲正切函数分类
- 07.4-实现逻辑与门和或门
- 08.0-单入单出双层-万能近似定理
- 08.1-双层拟合网络的原理
- 08.2-双层拟合网络的实现
- 09.0-多入多出双层-双变量非线性分类
- 09.1-实现逻辑异或门
- 09.2-理解二分类的工作原理
- 09.3-非线性多分类
- 09.4-理解多分类的工作原理
- 10.0-调参与优化
- 10.1-权重矩阵初始化
- 10.2-参数调优
- 10.3-搜索最优学习率
- 10.4-梯度下降优化算法
- 10.5-自适应学习率算法
- 11.0-深度学习基础
- 11.1-三层神经网络的实现
- 11.2-验证与测试
- 11.3-梯度检查
- 11.4-手工测试训练效果
- 11.5-搭建深度神经网络框架
- 12.0-卷积神经网络
- 12.1-卷积
- 12.2-池化
- 14.1-神经网络模型概述
- 14.2-Windows模型的部署
- 14.3-Android模型的部署
下面我们举一个简单的线性回归的例子来说明实际的反向传播和梯度下降的过程。完全看懂此文后,会对理解后续的文章有很大的帮助。
简单回忆一下什么是线性回归:
回归的目的是通过几个已知数据来预测另一个数值型数据的目标值。假设特征和结果满足线性关系,即满足一个计算公式y(x),这个公式的自变量就是已知的数据x,函数值y(x)就是要预测的目标值。这个计算公式称为回归方程,得到这个方程的过程就称为回归。线性回归就是假设这个方式是一个线性方程,一个多元一次方程,其形式为:
\[y=a_0+a_1x_1+a_2x_2+\dots+a_kx_k\]
为了简化起见,我们用一元一次的线性回归来举例,即\(z = wx+b\)(z,w,x,b都是标量),因为这个函数的形式和神经网络中的\(Z = WX + B\)(Z,W,X,B等都是矩阵)非常近似,可以起到用简单的原理理解复杂的事情的作用。
创造训练数据
让我们先自力更生创造一些模拟数据:
import numpy as np
import matplotlib.pyplot as plt
from pathlib import Path
def create_sample_data(m):
# check if saved before
Xfile = Path("XData.npy")
Yfile = Path("YData.npy")
# load data from file
if Xfile.exists() & Yfile.exists():
X = np.load(Xfile)
Y = np.load(Yfile)
else: # generate new data
X = np.random.random(m)
# create some offset as noise to simulate real data
noise = np.random.normal(0,0.1,X.shape)
# genarate Y data
W = 2
B = 3
Y = X * W + B + noise
np.save("XData.npy", X)
np.save("YData.npy", Y)
return X, Y由于使用了文件存储,所以在第二次运行本程序时,或者在调试代码时,前后的结果是可比的,因为是同一批数据。
得到200个数据点如下:

好了,模拟数据制作好了,目前X是一个200个元素的集合,里面有0~1之间的随机x点,Y是一个200个元素的集合,里面有对应到每个x上的\(y=2x+3\)的值,然后再加一个或正或负的上下偏移作为噪音,来满足对实际数据的模拟效果(因为大部分真实世界的生产数据从来都不是精确的,精确只存在于数学领域)。
现在我们要忘记这些模拟数据(样本值)是如何制作出来的,也就是要忘记W,B的值。我们就假设这是实际应用中收集到的模拟数据,但是我们并不知道它的原始函数是什么参数,只知道是公式\(y = wx + b\),我们的任务就是要根据这些样本值,通过神经网络训练的方式,得到w和b的值。注意这里x和y是样本的输入和输出,不是目标变量,这一点和常见的初等数学题不一样,要及时转变概念。
最终,样本数据的样子是:
\[ \begin{pmatrix} x_1\\ x_2\\ \dots\\ x_m\\ \end{pmatrix} , \begin{pmatrix} y_1\\ y_2\\ \dots\\ y_m\\ \end{pmatrix} \]
其中,x就是上图中蓝色点的横坐标值,y是纵坐标值。
最小二乘法与均方差
线性回归试图学得 \(z(x_i)=wx_i+b\),使得\(z(x_i) \simeq y_i\)。如何学得w和b呢?均方差(MSE - mean squared error)是回归任务中常用的手段:
\[ Error = \frac{1}{m}\sum_{i=1}^m(z(x_i)-y_i)^2 = \frac{1}{m}\sum_{i=1}^m(y_i-wx_i-b)^2 \]
其中,\(x_i和y_i\)是样本值,\(z_i\)是预测值。
实际上就是试图找到一条直线,使所有样本到直线上的欧氏距离之和最小。

假设我们计算出初步的结果是红色虚线所示,这条直线是否合适呢?我们来计算一下图中每个点到这条直线的距离(黄色线),把这些距离的值都加起来(都是正数,不存在互相抵消的问题)成为loss,然后想办法不断改变红色直线的角度和位置,让loss最小,就意味着整体偏差最小,那么最终的那条红色直线就是我们要的结果。
如果想让Error的值最小,通过对w和b求导,再令导数为0(到达最小极值),就是w和b的最优解:
\[ w = \frac{\sum{y_i(x_i-\bar{x})}}{\sum{x_i^2}-\frac{1}{m}(\sum{x_i})^2}\tag{求和均为i=1到m} \]
\[ b=\frac{1}{m}\sum_{i=1}^m(y_i-wx_i) \]
我们先试一下上面这两个公式是否好用:
x_sum = sum(X) # 求x之和
x_mean = x_sum/m # 求x平均
x_square = sum(X*X) # 求x平方之和
x_square_mean = x_sum * x_sum / m # 求x之和之平方之均
xy = sum(Y*(X-x_mean)) # 求w的公式的分子部分
w = xy / (x_square - x_square_mean) # 求w
print(w)
b = sum(Y-w*X) / m # 求b
print(b)
结果为:
w=1.9983541668129974
b=3.0128994960012876可以看到非常接近w=2,b=3的原始值。
既然我们已经可以用纯数学方法的最小二乘法得到w,b的值,为什么还要学机器学习的方法呢?因为最小二乘法能做的事情有两种:
\[y=a_0+a_1x+a_2x^2+ \dots + a_mx^m \tag{单元x多次方程}\]
\[y=a_0+a_1x_1+a_2x_2+ \dots + a_mx_m \tag{多元x线性方程}\]
前提条件是我们预测到方程的形式。但是更复杂的形式就比较吃力甚至无能为力了,比如:
\[y=0.4x^2 + 0.3xsin(15x) + 0.01cos(50x)-0.3\]
\[y=3x_1^2 + 4x_2\]
而在客观世界中或实际的生产环境中,我们其实根本不知道要拟合的曲线是什么形式,就根本无从下手,这时只能用神经网络来拟合了,而拟合的结果也不是一个公式,而是一个神经网络模型。
定义神经网络结构
我们是首次尝试建立神经网络,先搞一个最简单的单点神经元:
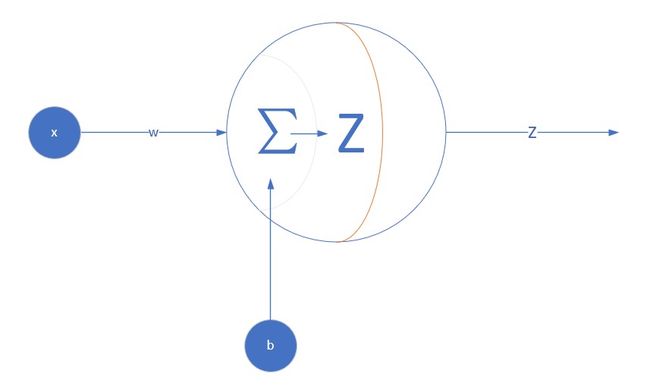
对于简单的线性回归问题,我们使用单层网络单个神经元就足够了。而且由于是线性的,我们不需要定义激活函数,这就大大简化了程序,而且便于大家循序渐进地理解。
样本数据x,乘以相同的w值后相加,再加上偏移b,输出z。
def forward_calculation(w,b,X):
z = w * x + b
return z定义代价函数
我们用传统的均方差函数: \(loss = \frac{1}{2}(Z-Y)^2\),其中,Z是每一次迭代的预测输出,Y是样本标签数据。我们使用所有样本参与训练,因此损失函数实际为:
\[loss = \frac{1}{2m}\sum_{i=1}^{m}(Z_i - Y_i) ^ 2\]
其中的分母中有个2,实际上是想在求导数时把这个2约掉,没有什么原则上的区别。
由于loss是所有样本的集合,我们先对其中的所有值求总和,样本数量是m,然后除以m来求一个平均值。
下面是Python的code,用于计算损失:
# w:weight, b:bias, X,Y:sample data, count: count of sample, prev_loss:last time's loss
def check_diff(w, b, X, Y, count, prev_loss):
Z = w * X + b
LOSS = (Z - Y)**2
loss = LOSS.sum()/count/2
diff_loss = abs(loss - prev_loss)
return loss, diff_loss我们计算这个loss值的目的是计算前后两次迭代的loss值差异,当足够小时,就结束训练。
定义针对w和b的梯度函数
求w的梯度
因为:
\[z = wx+b\]
\[loss = \frac{1}{2}(z-y)^2\]
所以我们用loss的值作为基准,去求w对它的影响,也就是loss对w的偏导数:
\[ \frac{\partial{loss}}{\partial{w}} = \frac{\partial{loss}}{\partial{z}}*\frac{\partial{z}}{\partial{w}} \]
其中:
\[ \frac{\partial{loss}}{\partial{z}} = \frac{\partial{(\frac{1}{2}(z-y)^2)}}{\partial{z}} = z-y \]
而:
\[ \frac{\partial{z}}{\partial{w}} = \frac{\partial{}}{\partial{w}}(wx+b) = x \]
所以:
\[ \frac{\partial{loss}}{\partial{w}} = \frac{\partial{loss}}{\partial{z}}*\frac{\partial{z}}{\partial{w}} = (z-y)x \]
求b的梯度
所以我们用loss的值作为基准,去求w对它的影响,也就是loss对w的偏导数:
\[ \frac{\partial{loss}}{\partial{b}} = \frac{\partial{loss}}{\partial{z}}*\frac{\partial{z}}{\partial{b}} \]
其中第一项前面算w的时候已经有了,而:
\[ \frac{\partial{z}}{\partial{b}} = \frac{\partial{(wx+b)}}{\partial{b}} = 1 \]
所以:
\[ \frac{\partial{loss}}{\partial{b}} = \frac{\partial{loss}}{\partial{z}}*\frac{\partial{z}}{\partial{b}} = z-y \]
# z:predication value, y:sample data label, x:sample data, count:count of sample data
def dJwb_batch(X,Y,Z,count):
p = Z - Y
db = sum(p)/count
q = p * X
dw = sum(q)/count
return dw, db
def dJwb_single(x,y,z):
p = z - y
db = p
dw = p * x
return dw, db
上面有两个求梯度函数,第一个用于数组数据(当输入的X/Y/Z都是数组时),第二个用于标量数据(x/y/z都是标量),但最后输出的dw/db都是标量,因为只有一个神经元。
每次迭代后更新w,b的值
def update_weights(w, b, dw, db, eta):
w = w - eta*dw
b = b - eta*db
return w,b帮助函数
第一个show_result函数用于最后输出结果。第二个print_progress函数用于训练过程中的输出。
def show_result(X, Y, w, b, iteration, loss_his, w_his, b_his, n):
# draw sample data
# plt.figure(1)
plt.subplot(121)
plt.plot(X, Y, "b.")
# draw predication data
Z = w*X +b
plt.plot(X, Z, "r")
plt.subplot(122)
plt.plot(loss_his[0:n], "r")
plt.plot(w_his[0:n], "b")
plt.plot(b_his[0:n], "g")
plt.grid(True)
plt.show()
print(iteration)
print(w,b)
def print_progress(iteration, loss, diff_loss, w, b, loss_his, w_his, b_his):
if iteration % 10 == 0:
print(iteration, diff_loss, w, b)
loss_his = np.append(loss_his, loss)
w_his = np.append(w_his, w)
b_his = np.append(b_his, b)
return loss_his, w_his, b_his主程序初始化
# count of samples
m = 200
# initialize_data
eta = 0.01
# set w,b=0, you can set to others values to have a try
w, b = 0, 0
eps = 1e-10
iteration, max_iteration = 0, 10000
# calculate loss to decide the stop condition
prev_loss, loss, diff_loss = 0,0,0
# create mock up data
X, Y = create_sample_data(m)
# create list history
loss_his, w_his, b_his = list(), list(), list()训练方式的选择
接下来,我们会用三种方式来训练神经网络(神经元):
- 随机梯度下降SGD (Stochastic Gradient Descent):每次迭代只使用一个样本进行训练,每次都更新梯度值
- 批量梯度下降BGD (Batch Gradient Descent):把所有样本整批的输入网络进行训练,每批样本更新一次梯度值
- 小批量梯度下降MBGD (Mini-batch Gradient Descent):每次用一部分样本进行训练,每小批样本更新一次梯度值
Pseudo code如下:
第一种方式:逐个样本训练即随机梯度下降
repeat:
for 每个样本x,y:
标量计算得到z的单值 z = w * x + b
计算w的梯度
计算b的梯度
更新w,b的值
计算本次损失
与上一次的损失值比较,足够小的话就停止训练
end for
until stop condition第二种方式:批量样本训练即批量梯度下降
repeat:
矩阵前向计算得到Z值 = w * X + b(其中X是所有样本的数组)
计算w的梯度
计算b的梯度
更新w,b的值
计算本批损失
与上一批的损失值比较,足够小的话就停止训练
until stop condition第三种方式:小批量样本训练即批量梯度下降
repeat:
从样本集X中获得一小批量样本Xn
矩阵前向计算得到Z值 = w * Xn + b(其中Xn是一小批样本的数组)
计算w的梯度
计算b的梯度
更新w,b的值
计算本批损失
与上一批的损失值比较,足够小的话就停止训练
until stop condition我们看完它们的训练结构后再来比较它门的好坏。
随机梯度下降方式 - SGD
针对200个数据,每次迭代只使用一个样本进行训练,每次都更新梯度值。
程序主循环
while iteration < max_iteration:
for i in range(m):
# get x and y value for one sample
x = X[i]
y = Y[i]
# get z from x,y
z = forward_calculation(w, b, x)
# calculate gradient of w and b
dw, db = dJwb_single(x, y, z)
# update w,b
w, b = update_weights(w, b, dw, db, eta)
# calculate loss for this batch
loss, diff_loss = check_diff(w,b,X,Y,m,prev_loss)
# condition 1 to stop
if diff_loss < eps:
break
prev_loss = loss
iteration += 1
loss_his, w_his, b_his = print_progress(iteration, loss, diff_loss, w, b, loss_his, w_his, b_his)
if diff_loss < eps:
break
show_result(X, Y, w, b, iteration, loss_his, w_his, b_his, 200)程序运行结果
1 0.0013946089980010831 1.7082689753500857 2.8635473444149815
2 1.2964547916170625e-05 1.8540100768184453 3.06775776515801
3 7.79019593934345e-07 1.8807160337440225 3.0745103188170186
......
19 8.734980997196495e-09 1.9871421670235265 3.0189893623564035
20 6.770768725197773e-09 1.9888753203686051 3.0180574393623383
21 1.4217967081453509e-13 1.9909568305589769 3.0231282539481192
21
1.9909568305589769 3.0231282539481192一共迭代了21次(实际是21*200次),由于diff_loss小于1e-10,所以停止了。但是,可以看到w=1.99..,b=3.023...,与实际值w=2, b=3还有差距。
下图右侧图,红色线是loss值的变化,蓝色线是w值的变化,绿色线是b值的变化。这三个值都很快从初始值趋近于理想值,可见这种方式的收敛速度较快。

批量梯度下降方式 - BGD
程序主循环
# condition 2 to stop
while iteration < max_iteration:
# using current w,b to calculate Z
Z = forward_calculation(w,b,X)
# get gradient value
dW, dB = dJwb_batch(X, Y, Z, m)
# update w and b
w, b = update_weights(w, b, dW, dB, eta)
# print(iteration,w,b)
iteration += 1
# condition 1 to stop
loss, diff_loss = check_diff(w,b,X,Y,m,prev_loss)
if diff_loss < eps:
break
prev_loss = loss
iteration += 1
loss_his, w_his, b_his = print_progress(iteration, loss, diff_loss, w, b, loss_his, w_his, b_his)
show_result(X, Y, w, b, iteration, loss_his, w_his, b_his, 200)程序运行结果
15580 1.0078619969849933e-10 1.9970527059142416 3.013622182124774
15590 1.0010891421385892e-10 1.9970570862183055 3.0136197497927952
15591
1.9970579605084025 3.013619264309657训练过程迭代了15591次,loss的前后差值小于1e-10了,达到了停止条件。可以看到最后w = 1.997, b = 3.0136。
下图右侧图,红色线是loss值的变化,蓝色线是w值的变化,绿色线是b值的变化。到第400次迭代时,w/b两个值还没有到达理想值。loss的下降速度很快,但是在后期的变化很小,不能给w/b提供有效的反馈。

小批量梯度下降方式 - MBGD
程序主循环
batchNumber = 20 # 设置每批的数据量为20
# condition 2 to stop
while iteration < max_iteration:
# generate current batch
batchX, batchY = generate_batch(X, Y, iteration, batchNumber, m)
# using current w,b to calculate Z
Z = forward_calculation(w,b,batchX)
# get gradient value
dW, dB = dJwb_batch(batchX, batchY, Z, batchNumber)
# update w and b
w, b = update_weights(w, b, dW, dB, eta)
# calculate loss
loss, diff_loss = check_diff(w,b,X,Y,m,prev_loss)
# condition 1 to stop
if diff_loss < eps:
break
prev_loss = loss
iteration += 1
loss_his, w_his, b_his = print_progress(iteration, loss, diff_loss, w, b, loss_his, w_his, b_his)
show_result(X, Y, w, b, iteration, loss_his, w_his, b_his, 300)程序运行结果
4450 1.2225522157127688e-10 1.9753608229361126 3.0087345373193264
4460 1.1451271614976166e-10 1.9753871799671467 3.008717691199392
4470 1.068962461950318e-10 1.975413384400498 3.0087009426124025
4479
1.975439437119652 3.0086842909936786训练过程迭代了4479次,最后w=1.9754, b=3.0086。
下图右侧图,红色线是loss值的变化,蓝色线是w值的变化,绿色线是b值的变化。到第300次迭代时,w/b值已经接近理想值了。loss的下降速度慢,但是在后期仍然可以给w/b有效的反馈。

三种方式的比较
下图是三种方式在向目标解迭代靠近时的示意图:

随机梯度下降
- 每次用一个样本训练,然后立刻更新权重,训练速度最快。可以简单地理解为“神经过敏”性格。
- 可以设置一个适中(更多)的迭代次数,以便得到更好的解
- 由于使用单个样本数据,会受数据噪音的影响,且前后两个样本的训练效果可能会相互抵消。从轨迹上来看,跳跃性较大。
- 由于数据随机,所以有可能受训练样本噪音影响而跳到全局最优解,但是不保证。在某些博客中说“本方法只能获得局部最优解”,这实际上是不对的。
批量梯度下降
- 每次用整批样本训练后,才更新一次权重,训练速度最慢。可以简单地理解为“老成持重”性格。
- 特定的样本如果误差较大,不会影响整体的训练质量
- 从轨迹上来看,比较平稳地接近中心,但是在接近最优解时的迭代次数太多,非常缓慢
- 如果只有一个极小值,可以得到相对全局较优的解。如果实际数据有两个极小值,不一定能得到全局最优解。在某些博客中说“本方法可以获得全局最优解”,这实际上是不能保证的,取决于初始值设置。
小批量梯度下降
- 每次使用一小批数据训练,速度适中。可以简单地理解为“稳重而不失灵活”的性格。
- 多了一个batchNumber参数需要设置,大家可以试验一下分别设置为10,20,25,40,50,训练效果如何
- 从轨迹上来看,有小的跳跃,但是下降方向还算是稳定,不会向反方向跳跃
孔子说:点赞是人类的美德!如果觉得有用,关闭网页前,麻烦您给点个赞!然后准备学习下一周的内容。
点击这里提交问题与建议
联系我们: [email protected]
学习了这么多,还没过瘾怎么办?欢迎加入“微软 AI 应用开发实战交流群”,跟大家一起畅谈AI,答疑解惑。扫描下方二维码,回复“申请入群”,即刻邀请你入群。
