MYSQL(高可用方案)
本次专题是 MySQL高可用方案选型,这个专题想必有很多同学感兴趣。
高可用的意义以及各种不同高可用等级相应的停机时间我就不必多说了,直接进入主题。
可选MySQL高可用方案
MySQL的各种高可用方案,大多是基于以下几种基础来部署的:
-
基于主从复制;
-
基于Galera协议;
-
基于NDB引擎;
-
基于中间件/proxy;
-
基于共享存储;
-
基于主机高可用;
在这些可选项中,最常见的就是基于主从复制的方案,其次是基于Galera的方案,我们重点说说这两种方案。其余几种方案在生产上用的并不多,我们只简单说下。
基于主从复制的高可用方案
双节点主从 + keepalived/heartbeat
一般来说,中小型规模的时候,采用这种架构是最省事的。
两个节点可以采用简单的一主一从模式,或者双主模式,并且放置于同一个VLAN中,在master节点发生故障后,利用keepalived/heartbeat的高可用机制实现快速切换到slave节点。
在这个方案里,有几个需要注意的地方:
-
采用keepalived作为高可用方案时,两个节点最好都设置成BACKUP模式,避免因为意外情况下(比如脑裂)相互抢占导致往两个节点写入相同数据而引发冲突;
-
把两个节点的auto_increment_increment(自增起始值)和auto_increment_offset(自增步长)设成不同值。其目的是为了避免master节点意外宕机时,可能会有部分binlog未能及时复制到slave上被应用,从而会导致slave新写入数据的自增值和原先master上冲突了,因此一开始就使其错开;当然了,如果有合适的容错机制能解决主从自增ID冲突的话,也可以不这么做;
-
slave节点服务器配置不要太差,否则更容易导致复制延迟。作为热备节点的slave服务器,硬件配置不能低于master节点;
-
如果对延迟问题很敏感的话,可考虑使用MariaDB分支版本,或者直接上线MySQL 5.7最新版本,利用多线程复制的方式可以很大程度降低复制延迟;
-
对复制延迟特别敏感的另一个备选方案,是采用semi sync replication(就是所谓的半同步复制)或者后面会提到的PXC方案,基本上无延迟,不过事务并发性能会有不小程度的损失,需要综合评估再决定;
-
keepalived的检测机制需要适当完善,不能仅仅只是检查mysqld进程是否存活,或者MySQL服务端口是否可通,还应该进一步做数据写入或者运算的探测,判断响应时间,如果超过设定的阈值,就可以启动切换机制;
-
keepalived最终确定进行切换时,还需要判断slave的延迟程度。需要事先定好规则,以便决定在延迟情况下,采取直接切换或等待何种策略。直接切换可能因为复制延迟有些数据无法查询到而重复写入;
-
keepalived或heartbeat自身都无法解决脑裂的问题,因此在进行服务异常判断时,可以调整判断脚本,通过对第三方节点补充检测来决定是否进行切换,可降低脑裂问题产生的风险。
双节点主从+keepalived/heartbeat方案架构示意图见下:
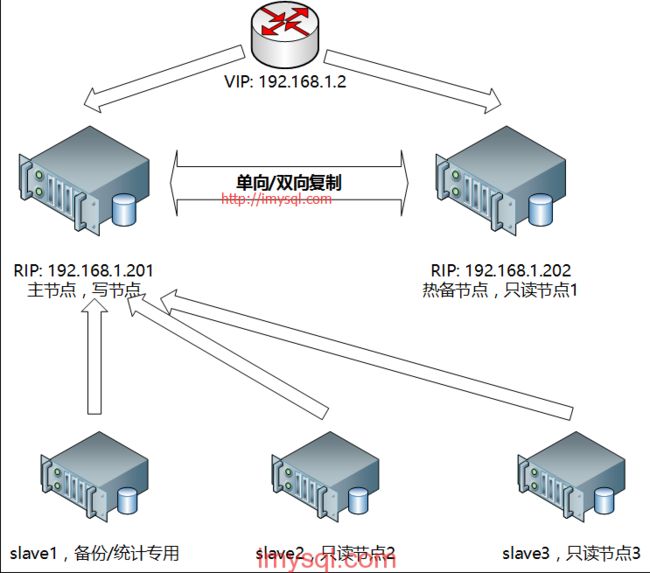
图解:MySQL双节点(单向/双向主从复制),采用keepalived实现高可用架构。
多节点主从+MHA/MMM
多节点主从,可以采用一主多从,或者双主多从的模式。
这种模式下,可以采用MHA或MMM来管理整个集群,目前MHA应用的最多,优先推荐MHA,最新的MHA也已支持MySQL 5.6的GTID模式了,是个好消息。
MHA的优势很明显:
-
开源,用Perl开发,代码结构清晰,二次开发容易;
-
方案成熟,故障切换时,MHA会做到较严格的判断,尽量减少数据丢失,保证数据一致性;
-
提供一个通用框架,可根据自己的情况做自定义开发,尤其是判断和切换操作步骤;
-
支持binlog server,可提高binlog传送效率,进一步减少数据丢失风险。
不过MHA也有些限制:
-
需要在各个节点间打通ssh信任,这对某些公司安全制度来说是个挑战,因为如果某个节点被黑客攻破的话,其他节点也会跟着遭殃;
-
自带提供的脚本还需要进一步补充完善,当然了,一般的使用还是够用的。
多节点主从+etcd/zookeeper
在大规模节点环境下,采用keepalived或者MHA作为MySQL的高可用管理还是有些复杂或麻烦。
首先,这么多节点如果没有采用配置服务来管理,必然杂乱无章,线上切换时很容易误操作。
在较大规模环境下,建议采用etcd/zookeeper管理集群,可实现快速检测切换,以及便捷的节点管理。
基于Galera协议的高可用方案
Galera是Codership提供的多主数据同步复制机制,可以实现多个节点间的数据同步复制以及读写,并且可保障数据库的服务高可用及数据一致性。
基于Galera的高可用方案主要有MariaDB Galera Cluster和Percona XtraDB Cluster(简称PXC),目前PXC用的会比较多一些。
PXC的架构示意图见下:

(图片源自网络),图解:在底层采用wsrep接口实现数据在多节点间的同步复制。

(图片源自网络),图解:在PXC中,一次数据写入在各个节点间的验证/回滚流程。
PXC的优点
-
服务高可用;
-
数据同步复制(并发复制),几乎无延迟;
-
多个可同时读写节点,可实现写扩展,不过最好事先进行分库分表,让各个节点分别写不同的表或者库,避免让galera解决数据冲突;
-
新节点可以自动部署,部署操作简单;
-
数据严格一致性,尤其适合电商类应用;
-
完全兼容MySQL;
虽然有这么多好处,但也有些局限性:
-
只支持InnoDB引擎;
-
所有表都要有主键;
-
不支持LOCK TABLE等显式锁操作;
-
锁冲突、死锁问题相对更多;
-
不支持XA;
-
集群吞吐量/性能取决于短板;
-
新加入节点采用SST时代价高;
-
存在写扩大问题;
-
如果并发事务量很大的话,建议采用InfiniBand网络,降低网络延迟;
事实上,采用PXC的主要目的是解决数据的一致性问题,高可用是顺带实现的。因为PXC存在写扩大以及短板效应,并发效率会有较大损失,类似semi sync replication机制。
其他高可用方案
-
基于NDB Cluster,由于NDB目前仍有不少缺陷和限制,不建议在生产环境上使用;
-
基于共享存储,一方面需要不太差的存储设备,另外共享存储可也会成为新的单点,除非采用基于高速网络的分布式存储,类似RDS的应用场景,架构方案就更复杂了,成本也可能更高;
-
基于中间件(Proxy),现在可靠的Proxy选择并不多,而且没有通用的Proxy,都有有所针对,比如有的专注解决读写分离,有的专注分库分表等等,真正好用的Proxy一般要自行开发;
-
基于主机高可用,是指采用类似RHCS构建一个高可用集群后,再部署MySQL应用的方案。老实说,我没实际用过,但从侧面了解到这种方案生产上用的并不多,可能也有些局限性所致吧;
以DBA们的聪明才智,肯定还有其他我不知道的方案,也欢迎同行们间多多交流。
从 MySQL+MMM 到 MariaDB+Galera Cluster : 一个高可用性系统改造
很少有事情比推出高可用性(HA)系统之后便经常看到的系统崩溃更糟糕。对于我们这个Rails运行机的团队来说,这个失效的HA系统是MySQL多主复制管理器(MMM)。
![]()
我们已经找寻MMM的替代品有一段时间了,几个月之前,我们转换到了MariaDB + Galera Cluster以寻求高可用的Mysql。
MMM怎么了,Galera Cluster又有什么特别之处呢?继续阅读!
MySQL多主机复制 (MMM)基本被打破
MySQL MMM 是如何工作的:一台安装了MySQL MMM的服务器每十秒种(默认间隔)轮询一次MySQL节点, 来检查其状态。仅其中的一台服务器接收到写入器角色 - 其他的可以拥有阅读器角色。 MMM 维护了一个虚拟IP,这个IP指向拥有写入器角色的节点。
问题在于轮询:如果MySQL每十分钟轮询,那么如果写入器节点在检查的间歇出现故障怎么办?如果你设置了HA你可能正处理着许多事务 - 在MMM检测到写入器节点不正常之前,可能已经有成千上万的事务失败了。更糟糕的是,如果存在一种内部问题:复制失败在先,事务失败在后,那么你要把写入器角色转到其他节点上吗?但是其他节点不一定符合原始的写入器节点。
减少轮询间隔到1秒也不能修正这个问题-大型数据库可能在每秒内运行许多事务。
因此轮询是根本问题,而且超出了根本问题范围。无法控制的MySQL MMM经常产生难以恢复的问题。Baron Swartz在Percona的MySQL大神上对MMM的缺陷有如下描述:
简要地来说,MMM产生的宕机时间比它要防止的宕机时间更长。因此它是一个低可靠性的工具,不是高可靠性的工具。它可以让你连续几天以7X24小时的工作方式从宕机的机器里提取数据,并放回到服务器上,这只会导致系统真正的非常严重的一塌糊涂。因此,MMM赋予词语"cluset-f__k"新的意义。
尽管MMM存在缺陷,然而它至少是对MySQL进行高可靠性的一次突破。然而时间改变了一切。甚至MySQL MMM的创建者也说到了要更改的时候了。Baron有关MMM的博客日志有Alexey's的如下评论:
我是MMM的最初的作者,我完全同意你的意见。每次我试图给集群添加HA的时候,我都会想起MMM,而且需要亲自去尝试,因为我只是不确定这个工具的我所做的配置。而且市场上没有其他软件可以可靠地做这项工作。
那么,为什么Galera是最好的MySQL HA解决方案呢?
我们的Galera Cluster设置仍然使用轮询来做健康检测——这比MMM好在哪里呢?
答案在于主从复制怎样是运作的。对于标准版的MySQL,对master的写操作被记录于一个二进制的日志。Slave会在之后复制二进制日志中的查询。查询在写服务器上运行与在其它节点上运行时刻之间,总是会有一个延迟。它是异步的。
MySQL异步复制有下面的问题:
-
slave服务器的数据集总是落后于master服务器。
-
MySQL复制很慢——它从二进制日志回访事务。
对于Galera,事务是在它们被提交之前被所有节点确认。如果一个事务在一个节点失败了,那个节点将立刻从群集中移除。换句话说,Galera主从复制是同步的。你 永远也不会丢失事务——没有延迟 (而且Galera的 基于行的复制大约要快5倍速)。
Galera集群是局内人
MySQL MMM 是一个局外者—— 对于服务器上实际在发生的事情它是“哑的”。它只做一种检测,而且那就是它所知道的全部该如何反应的事情。
Galera集群是一个“局内人”,因此对每个节点的内部状态要更机灵,并且不需要人工干预就可以做正确的事情(例如,一个节点同步或未同步,成为一个donor(节点处于为新节点准备或传输集群全量数据状态,对客户端不可用),等等——全部都是自动的)。
当写入节点失败的时候会发生什么呢?
由于用一个Galera集群可以写进任意节点,我们还是选择尽量减少潜在的死锁和只在一个节点写入。为此,我们使用HAProxy:我们拥有一个前端供“写入者”节点,另一个前端供读出以供所有节点实现余额查询。“写入者”通过单个节点发送请求,而其他的节点作为备份。
如果HAProxy检测到“写入者”节点不正常,它立即提拔备份节点中的一个作为“写入者”。MySQL的MMM在这种情况下通常会关掉所有节点之间的通话——HAProxy不会如此。当“写入者”后台更新的时候,我们可能会丢失一部分请求,但它不会导致不一致的数据集通过服务器,这比瘫痪更糟糕。
我们不会自动修复失败的节点,不过这没有关系。我主要关注点是确保一个正常的节点在执行写入,HAProxy是做这个的。
修复失效的节点(并让它作为一个新的节点处于在线状态)
当一个节点在标准的MySQL复制的时候失效,你将在再次进行复制的时候把大量的负载集中在一台服务器上(这台服务器不仅仅要进行读和写,而且还要承接来自innodbbackupex的负载)。
使用Galera,你可以让其中一个节点离线(因此你至少需要三个节点)。这时这个节点就成为供给者节点-对它的写操作将被阻塞。这个节点就通过rsync传输自身的数据给失效的节点(或者新的节点)。然后,供给者节点和失效节点通过辅助队列运行查询而与其他节点保持同步。
一旦这两个节点回归到同步状态,HAProxy将自动的标记它们为启动状态,然后把它们添回道前端。
Galera集群也支持普通的MySQL,因此我们为什么不切换到MariaDB?
切换到MariaDB的理由既有技术原因也有政治原因:
-
易于移植:首先,MariaDB是MySQL的随手可得的替代品。从MySQL 5.1移植到MariaDB,只有Galera服务器5.6可以运行。
-
性能:我们有几个包含索引的在性能方面存在问题的查询,后面通过令人惊讶的移植来”修补“这方面的问题。MariaDB似乎更适合于复杂查询和连接,而Rails上的Ruby也因处理复杂的查询和连接而扬名。MariaDB更适合做查找索引的整个工作,而且正如我前面所说,许多令人烦恼的查询现在已经提速了。我们似乎看不到二者在内存使用上有任何令人吃惊的区别。我期望Galera能更多的使用内存,不过如果这么做了,那么Galera就没有任何值得关注的地方了。
-
社团:MariaDB有很大的驱动力,而且与MySQL相比增加了更多的功能。Oracle对MySQL未来倾注了大量的心血,而MariaDB看起来也存活了好长时间-甚至谷歌正在切换到MariaDB。
我们会再做一次?
绝对地。我们没有看到有什么原因不切换到 MariaDB 和 Galera Cluster。
监控 Galera Cluster

监控 Galera 的一件伟大的事情是它是分层的 - 我们可以很容易地监视栈的每一部分。我们使用 Scout 来监视,那意味着我们仅仅需要去使用下列插件:
-
MariaDB Galera Cluster - 安装在每一个 Galera Cluster 结点上去获取关键指标(本地状态,连通性,等)。
-
HAProxy - 为每一个代理安装(写入器一次,读取器一次)。
-
URL Monitoring - 检测和 HAProxy 检测的相同的状态URL来决定结点的健康。
TL;DR
直到最近, MySQL MMM 是添加高可用性到 MySQL 的最好的(但坏了的)途径。Galera Cluster 最终为 MySQL 增加了真实的高可用性,主要多亏同步复制。
MariaDB作为Mysql的一个分支,在开源项目中已经广泛使用,例如大热的openstack,所以,为了保证服务的高可用性,同时提高系统的负载能力,集群部署是必不可少的。
MariaDB Galera Cluster 介绍
MariaDB集群是MariaDB同步多主机集群。它仅支持XtraDB/ InnoDB存储引擎(虽然有对MyISAM实验支持 - 看wsrep_replicate_myisam系统变量)。
主要功能:
-
同步复制
-
真正的multi-master,即所有节点可以同时读写数据库
-
自动的节点成员控制,失效节点自动被清除
-
新节点加入数据自动复制
-
真正的并行复制,行级
-
用户可以直接连接集群,使用感受上与MySQL完全一致
优势:
-
因为是多主,所以不存在Slavelag(延迟)
-
不存在丢失事务的情况
-
同时具有读和写的扩展能力
-
更小的客户端延迟
-
节点间数据是同步的,而Master/Slave模式是异步的,不同slave上的binlog可能是不同的
技术:
Galera集群的复制功能基于Galeralibrary实现,为了让MySQL与Galera library通讯,特别针对MySQL开发了wsrep API。
Galera插件保证集群同步数据,保持数据的一致性,靠的就是可认证的复制,工作原理如下图:
当客户端发出一个commit的指令,在事务被提交之前,所有对数据库的更改都会被 write-set 收集起来,并且将write-set 纪录的内容发送给其他节点。
write-set 将在每个节点进行认证测试,测试结果决定着节点是否应用write-set更改数据。
如果认证测试失败,节点将丢弃 write-set ;如果认证测试成功,则事务提交。
1 安装环境准备
安装MariaDB集群至少需要3台服务器(如果只有两台的话需要特殊配置,请参照官方文档)
在这里,我列出试验机器的配置:
操作系统版本:centos7
node4:10.128.20.16 node5:10.128.20.17 node6:10.128.20.18
以第一行为例,node4为 hostname ,10.128.20.16为 ip ,在三台机器修改 /etc/hosts 文件,我的文件如下:
10.128.20.16 node4 10.128.20.17 node5 10.128.20.18 node6
为了保证节点间相互通信,需要禁用防火墙设置(如果需要防火墙,则参照官方网站增加防火墙信息设置)
在三个节点分别执行命令:
systemctl stop firewalld
然后将 /etc/sysconfig/selinux 的 selinux 设置成 disabled ,这样初始化环境就完成了。
2 安装 MariaDB Galera Cluster
[root@node4 ~]# yum install -y mariadb mariadb-galera-server mariadb-galera-common galera rsync
[root@node5 ~]# yum install -y mariadb mariadb-galera-server mariadb-galera-common galera rsync
[root@node6 ~]# yum install -y mariadb mariadb-galera-server mariadb-galera-common galera rsync
3 配置 MariaDB Galera Cluster
初始化数据库服务,只在一个节点进行
[root@node4 mariadb]# systemctl start mariadb [root@node4 mariadb]# mysql_secure_installation NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDB SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY! In order to log into MariaDB to secure it, we'll need the current password for the root user. If you've just installed MariaDB, and you haven't set the root password yet, the password will be blank, so you should just press enter here. Enter current password for root (enter for none): OK, successfully used password, moving on... Setting the root password ensures that nobody can log into the MariaDB root user without the proper authorisation. Set root password? [Y/n] New password: Re-enter new password: Password updated successfully! Reloading privilege tables.. ... Success! By default, a MariaDB installation has an anonymous user, allowing anyone to log into MariaDB without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. Remove anonymous users? [Y/n] n ... skipping. Normally, root should only be allowed to connect from 'localhost'. This ensures that someone cannot guess at the root password from the network. Disallow root login remotely? [Y/n] y ... Success! By default, MariaDB comes with a database named 'test' that anyone can access. This is also intended only for testing, and should be removed before moving into a production environment. Remove test database and access to it? [Y/n] n ... skipping. Reloading the privilege tables will ensure that all changes made so far will take effect immediately. Reload privilege tables now? [Y/n] y ... Success! Cleaning up... All done! If you've completed all of the above steps, your MariaDB installation should now be secure. Thanks for using MariaDB!
关闭数据库,修改 /etc/my.cnf.d/galera.cnf
[root@node4 mariadb]# systemctl stop mariadb
[root@node4 ~]# vim /etc/my.cnf.d/galera.cnf
修改以下内容:
[mysqld] ...... wsrep_provider = /usr/lib64/galera/libgalera_smm.so wsrep_cluster_address = "gcomm://node4,node5,node6" wsrep_node_name = node4 wsrep_node_address=10.128.20.16 #wsrep_provider_options="socket.ssl_key=/etc/pki/galera/galera.key; socket.ssl_cert=/etc/pki/galera/galera.crt;"
提示:如果不用ssl的方式认证的话,请把 wsrep_provider_options 注释掉。
将此文件复制到node5、node6,注意要把 wsrep_node_name 和 wsrep_node_address 改成相应节点的 hostname 和ip。
4 启动 MariaDB Galera Cluster 服务
[root@node4 ~]# /usr/libexec/mysqld --wsrep-new-cluster --user=root &
观察日志:
[root@node4 ~]# tail -f /var/log/mariadb/mariadb.log 150701 19:54:17 [Note] WSREP: wsrep_load(): loading provider library 'none' 150701 19:54:17 [Note] /usr/libexec/mysqld: ready for connections. Version: '5.5.40-MariaDB-wsrep' socket: '/var/lib/mysql/mysql.sock' port: 3306 MariaDB Server, wsrep_25.11.r4026
出现 ready for connections ,证明我们启动成功,继续启动其他节点:
[root@node5 ~]# systemctl start mariadb
[root@node6 ~]# systemctl start mariadb
可以查看 /var/log/mariadb/mariadb.log,在日志可以看到节点均加入了集群中。
警告:--wsrep-new-cluster 这个参数只能在初始化集群使用,且只能在一个节点使用。
5 查看集群状态
我们可以关注几个关键的参数:
wsrep_connected = on 链接已开启
wsrep_local_index = 1 在集群中的索引值
wsrep_cluster_size =3 集群中节点的数量
wsrep_incoming_addresses = 10.128.20.17:3306,10.128.20.16:3306,10.128.20.18:3306 集群中节点的访问地址
6 验证数据同步
我们在 node4 上新建数据库 galera_test ,然后在 node5 和 node6 上查询,如果可以查询到 galera_test 这个库,说明数据同步成功,集群运行正常。
[root@node4 ~]# mysql -uroot -proot -e "create database galera_test"
[root@node5 ~]# mysql -uroot -proot -e "show databases" +--------------------+ | Database | +--------------------+ | information_schema | | galera_test | | mysql | | performance_schema | +--------------------+
[root@node6 ~]# mysql -uroot -proot -e "show databases" +--------------------+ | Database | +--------------------+ | information_schema | | galera_test | | mysql | | performance_schema | +--------------------+
至此,我们的 MariaDB Galera Cluster 已经成功部署。
https://www.cnblogs.com/robbinluobo/p/8294782.html