推理速度快千倍!谷歌开源语言模型Transformer-XL
语言建模是 NLP 中的一种重要技术,因为它能够应用在各种 NLP 任务中,如机器翻译和主题分类等。目前,处理语言建模问题有两种最先进的架构——循环神经网络(RNN)和 Transformer。前者处理输入表征(单词或字符),逐个学习它们之间的关系;后者接收一段表征,并使用注意机制学习它们之间的依赖关系。
虽然这两种架构都取得了令人瞩目的成就,但它们的主要局限在于捕获长期依赖性,例如使用文档开头的重要单词来预测后面的单词。谷歌和卡内基梅隆大学的一篇新论文《Transformer-XL:超越固定长度上下文的注意力语言模型》结合了这两种方法的优点。新模型在输入数据的每个段上使用 Transformer 的注意力模块,并使用循环机制来学习连续段之间的依赖关系。
Transformer-XL 在多种语言建模数据集(如单词级别的 enwik8 和字符级别的 text8)上实现了最目前先进的结果,且该模型在推理阶段速度更快,比之前最先进的 Transformer 架构快 300 到 1800 倍。
背景介绍:Transformer 架构
语言建模的一种常用方法是循环神经网络(RNN),因为这种网络可以很好地捕获单词之间的依赖关系,尤其是当其中含有 LSTM(详见 https://colah.github.io/posts/2015-08-Understanding-LSTMs/)等模块时。然而,受梯度消失问题的影响,RNN 往往速度很慢,且其学习长期依赖的能力比较有限。
2017 年提出的 Transformer 架构(详见 https://arxiv.org/abs/1706.03762)为语言建模问题提供了一种全新的解决方案:注意力模块。注意模块不是逐个地处理表征,而是接收一整段表征,并使用三个可训练的权重矩阵——查询(Query),键(Key)和值(Value)来一次性学习所有输入表征之间的依赖关系。这三个权重矩阵构成了注意力头(Attention Head)。Transformer 网络由多个层组成,每个层都有几个注意力头(和附加层),用于学习表征之间的不同关系。
与许多 NLP 模型一样,Transformer 会首先将输入表征嵌入到向量中。由于注意模块中含有并发处理机制,模型还需要添加有关表征顺序的信息。这个步骤被称为位置编码(Positional Encoding),可帮助网络学习其位置信息。通常,该步骤使用正弦函数完成。该函数根据表征的位置生成向量,而不需要学习任何参数。
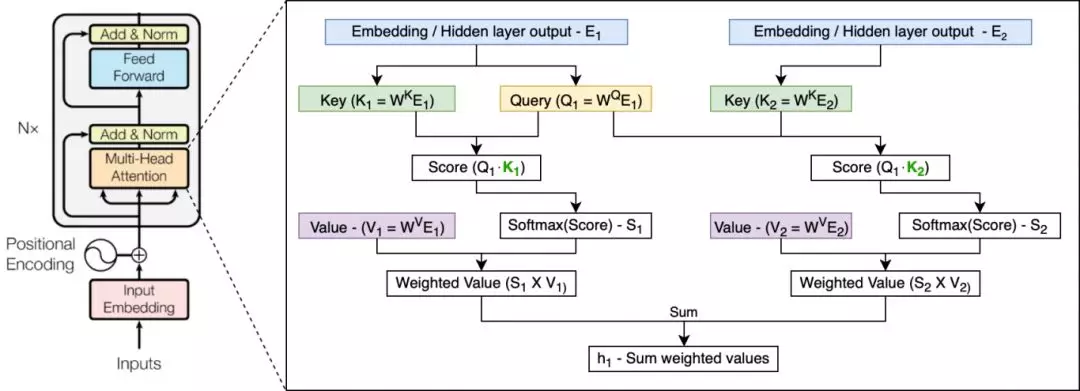
图:单个表征(E1)上的单个注意力头的示例。其输出是使用自身的 Query 向量及所有标记的 Key 和 Value 向量计算的(图中只显示一个额外的标记 E2)。Query 和 Key 定义每个表征的权重,其输出是所有 Value 向量的加权和。
注:有关 Transformer 的更深入讨论,可参考 Jay Alammar 的这篇博文
https://jalammar.github.io/illustrated-transformer/
最初的 Transformer 架构被用于机器翻译(含有编码器 - 解码器机制)。据此,Al-Rfou 等人(见 https://arxiv.org/abs/1808.04444)提出了一种语言建模架构。该架构的目标是根据之前的字符预测片段中的字符。例如,它使用 x1 ... xn-1 预测字符 xn,而右边的下一个字符则被屏蔽(参见下图)。这种 64 层变换器模型仅限于处理 512 个字符这种相对较短的输入,因此它将输入分成段,并分别从每个段中学习。如果在测试阶段需要处理较长的输入,该架构会在每一步中将输入向右移动一个字符,以此实现对单个字符的预测。
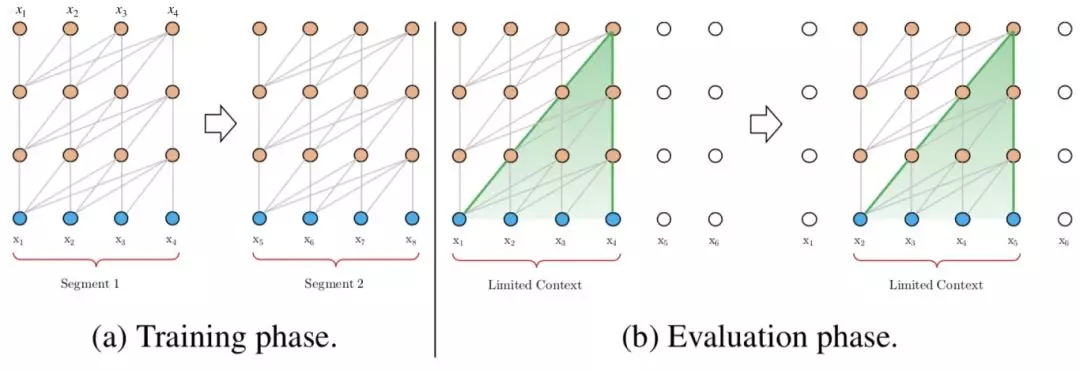
图:vanilla Transformer 语言模型的训练和测试示意。来源:Transformer-XL(https://arxiv.org/abs/1706.03762)
该模型在常用基准测试(enwik8 和 text8)上的表现优于 RNN 模型,但它仍然存在以下两个缺点:
-
上下文相关性有限。字符之间的最大依赖距离受输入长度的限制。例如,该模型不能“使用”出现在几个句子之前的单词。
-
上下文破碎。对于长度超过 512 个字符的文本,其每个段都是从头开始单独训练的。因此,对于每个段的第一个表征以及各个段之间,根本不存在上下文(依赖性)。这会使得训练效率低下,并会影响模型的性能。
Transformer-XL 的工作机制
Transformer-XL 架构基于 Al-Rfou 等人提出的 vanilla Transformer,但引入了两点创新——循环机制(Recurrence Mechanism) 和 相对位置编码(Relative Positional Encoding),以克服 vanilla Transformer 的缺点。与 vanilla Transformer 相比,该架构的另一个优势是它可以被用于单词级和字符级的语言建模。
循环机制
循环机制的目标是通过利用之前段的信息来实现长期依赖性。与 vanilla Transformer 类似,Transformer-XL 处理第一个标记段,但它会保留隐藏层的输出。处理后面的段时,每个隐藏层都会接收两个输入:
-
该段的前一个隐藏层的输出,和 vanilla Transformer 相同(如下图中的灰色箭头所示)。
-
上一个隐藏层的输出(如绿色箭头所示),可以使模型创建长期依赖关系。
从技术上讲,这两个输入会被拼接,然后用于计算当前段(当前层的当前头部)的 Key 和 Value 矩阵。该步骤为网络提供了更多关于每个表征的权重(重要性)的信息,但它不会更改 Value 矩阵。
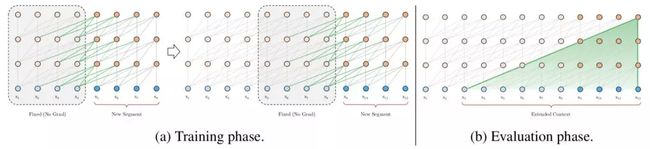
图:Transformer-XL 语言模型的训练和测试示意。来源:Transformer-XL(https://arxiv.org/abs/1706.03762)
该概念可以扩展到更长的依赖上。使用相同的方法,利用前面多个段的信息,只要 GPU 内存允许,在测试阶段也可以获得更长的依赖。
循环机制的另一个优点是其测试速度快。在每个步骤中,它可以一次前进一整个段(而不是像在 vanilla Transformer 中一次只能前进一个表征),并使用先前段的数据来预测当前段的表征。
相对位置编码
循环机制引入了新的挑战——原始位置编码将每个段分开处理,因此,来自不同段的表征会具有相同的位置编码。例如,第一和第二段的第一个表征将具有相同的编码,虽然它们的位置和重要性并不相同(比如第一个段中的第一个表征可能重要性低一些)。这种混淆可能会错误地影响网络。
针对此问题,论文提出了一种新的位置编码方式。这种位置编码是每个注意力模块的一部分。它不会仅在第一层之前编码位置,而且会基于表征之间的相对距离而非绝对位置进行编码。从技术上讲,它对注意力头分数(Attention Head’s Score)的计算方式不再是简单的乘法(Qi⋅Kj),而是包括四个部分:
-
内容权重——没有添加原始位置编码的原始分数。
-
相对于当前内容的位置偏差(Qi)。该项使用正弦类函数来计算表征之间的相对距离(例如 i-j),用以替代当前表征的绝对位置。
-
可学习的全局内容偏差——该模型添加了一个可学习的向量,用于调整其他表征内容(Kj)的重要性。
-
可学习的全局偏差——另一个可学习向量,仅根据表征之间的距离调整重要性(例如,最后一个词可能比前一段中的词更重要)。
实验结果
论文作者比较了模型在单词级别和字符级别数据集上的表现,并将其与其他著名模型(RNN 和 Transformer)进行了比较。Transformer-XL 在几个不同的数据集基准测试中实现了最先进的(SOTA)结果:
-
在大型单词级别数据集——WikiText-103 数据集上,18 层的 Transformer-XL(含有 257M 参数)获得了 18.3 的困惑度(Perplexity)。这个结果优于之前 Baevski 和 Auli(论文链接:https://arxiv.org/abs/1809.10853)得到的最优值 20.5。
-
在字符级数据集 enwik8上,12 层 Transformer-XL 达到了 1.06 位每字符(bpc),与 Al-Rfou 等人之前的 SOTA(链接:https://arxiv.org/abs/1808.04444)类似,但相比于 Transformer-XL,Al-Rfou 等人却使用了六倍以上的参数。另外,24 层 Transformer-XL 实现了一个 0.99 bpc 的新 SOTA。
-
有趣的是,在仅具有短期依赖性的数据集(如仅包含单个句子 One Billion Word 数据集)以及小型数据集(如仅含有 1M 表征的 Penn Treebank 数据集)上,Transformer-XL 也实现了 SOTA 结果。这表明该模型在这些情景中也可能有效。
循环机制和相对位置编码的优点如下面的图表所示。图中比较了不同上下文长度(即注意力头中使用的之前的表征的数量)中包含或不包含循环机制,以及使用或不使用新编码方式的困惑度得分。完整的 Transformer-XL 明显优于其他模型,并能够有效利用长期依赖性。此外,它还能够捕获比 RNN 更长的依赖性(延长了 80%)。
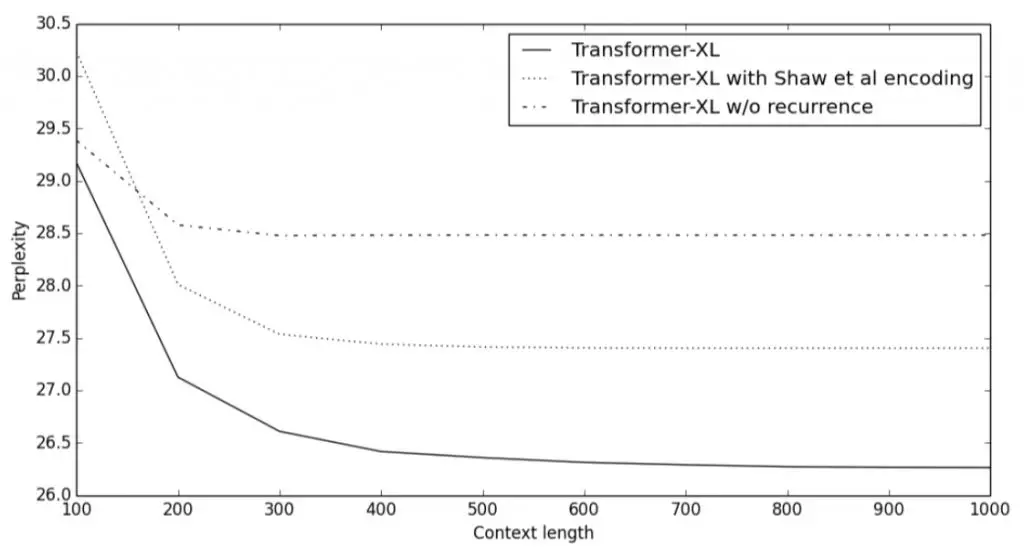
图:Transformer-XL 的对比实验。来源:Transformer-XL(链接:https://arxiv.org/abs/1706.03762)
最后,如前所述,该模型在推理阶段的速度也明显快于 vanilla Transformer,特别是对于较长的上下文。例如,对于 800 个字符的上下文长度,Transformer-XL 比 vanilla Transformer 快 363 倍;而对于 3800 字符的上下文,Transformer-XL 快了 1874 倍。
实现细节
该模型是开源的,并使用 TensorFlow 和 PyTorch 实现(链接:https://github.com/kimiyoung/transformer-xl/)。作者也上传了预先训练好的模型。每个数据集的训练具体需要多长时间并未明确给出。
结 论
Transformer-XL 在几种不同的数据集(大 / 小,字符级别 / 单词级别等)均实现了最先进的语言建模结果。它结合了深度学习的两个重要概念——循环机制和注意力机制,允许模型学习长期依赖性,且可能可以扩展到需要该能力的其他深度学习领域,例如音频分析(如每秒 16k 样本的语音数据)等。
此模型尚未在情感分析或问题回答等 NLP 任务上进行测试。另外,这种强语言模型与其他基于 Transformer 的模型(如 BERT,参见 https://www.lyrn.ai/2018/11/07/explained-bert-state-of-the-art-language-model-for-nlp/)相比有何优点,仍然有待解答。
相关资料传送门:
论文地址:
https://arxiv.org/abs/1901.02860
代码开源(包含 PyTorch 和 TensorFlow 的模型实现,而且带有预训练的模型):
https://github.com/kimiyoung/transformer-xl
原文链接:
https://www.lyrn.ai/2019/01/16/transformer-xl-sota-language-model/
转载:https://mp.weixin.qq.com/s/Xf3tCCTX6awd3bbjcSUAvQ