AI芯片:商汤科技基于winograd算法的FPGA方案分析
商汤科技2017年发表了一篇论文:Evaluating Fast Algorithms for Convolutional Neural Networks on FPGAs.
商汤科技的这篇论文,利用论文Fast Algorithms for Convolutional Neural Networks中研究的winograd算法大量减少乘法操作的优点,应用到卷积计算中去。
总体来说,商汤科技的这个设计思想就是:通过大量减少卷积计算的乘法操作,降低运算复杂度,来提高运算速度,并在FPGA中顺利实现。
本文,主要分析商汤论文Evaluating Fast Algorithms for Convolutional Neural Networks on FPGAs中的设计思路及实现方式,重点关注怎么处理卷积计算。
另外,会用到论文Fast Algorithms for Convolutional Neural Networks中的部分结论。
有兴趣的小伙伴,可以去下载论文详细研究。
感谢商汤科技及两篇论文作者的分享。
首先谈一谈winograd算法的优点。
然后研究下商汤科技的实现方案。
1.winograd算法
这里的内容主要来自论文Fast Algorithms for Convolutional Neural Networks。
假设输入为d,滤波器为g。
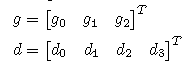
图1 输入及滤波器
上图为输入及滤波器的向量表示形式。这里以最简单的一维向量为例。
用F(m,n)表示卷积计算,其中m是一次卷积计算输出结果的个数,n表示滤波器的宽度(元素的个数)。
输入与滤波器怎么做卷积呢?
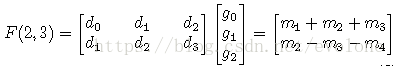
图2 卷积计算
上图所示,为输入d与滤波器g做卷积计算。
(1)常规卷积计算
根据矩阵运算规则,易知:
F(2,3)=
d0 x g0 + d1 x g1 + d2 x g2
d1 x g0 + d2 x g1 + d3 x g2
如果这么计算F(2,3),那么必然需要6个乘法,4个加法。
(2)winograd
经过拼凑得到
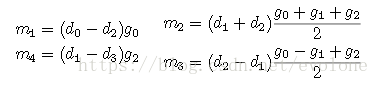
图3 拼凑m
这两种方法计算结果一致,我手动计算验证过了。直观感受就是,方法二是将方法一的结果进行拆分拼凑得到。
很奇妙吧!
这就是数学的魅力。
利用m1,m2,m3,m4去计算F(2,3),那么需要4个乘法(除以2,因为是定点数的运算,且是2的幂次,直接左移一位即可,而不用浪费乘法运算单元),11个加(减)法。
比较一下这两个方法,发现,方法二比方法一少2个乘法,但是多了7个加法。
这里,就需要去衡量一下,这样的交换比,是否值得。
还好,这样的交换比是可以接受的。
下面把上面的这种做法,用矩阵的形式表示,提炼成公式运算。
首先假设有如下矩阵:
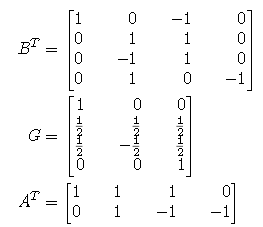
图4 transform 矩阵
那么有
![]()
图5 一维winograd公式
然后可以推导到二维的公式:
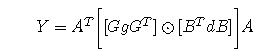
嗯,这个就是商汤科技论文中直接拿去用的公式。
当然,这个时候的g的尺寸是(r x r),这是个二维的输入。d也类似。
上面的transform矩阵只是针对F(2,3)的。
以此类推。
F(3,2)对应transform矩阵:
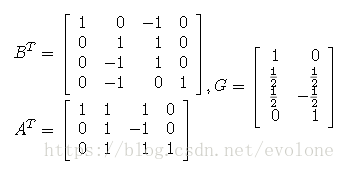
F(4,3)对应transform矩阵:

可以看出,不同参数的F(m,n)的转化矩阵是不一样的。这个是winograd算法的缺点。
2.winograd算法的FPGA实现
下面的分析主要是基于商汤科技的论文Evaluating Fast Algorithms for Convolutional Neural Networks on FPGAs。
商汤科技论文说,大部分的卷积都是用的3 x 3的滤波器,如果滤波器是5 x 5的,那么,通过边缘补0,扩展成4个3 x 3的滤波器。如果滤波器的尺寸太大,比如11 x 11,那么还是采用传统卷积去算。
所以,商汤采用的是F(2,3)的公式。
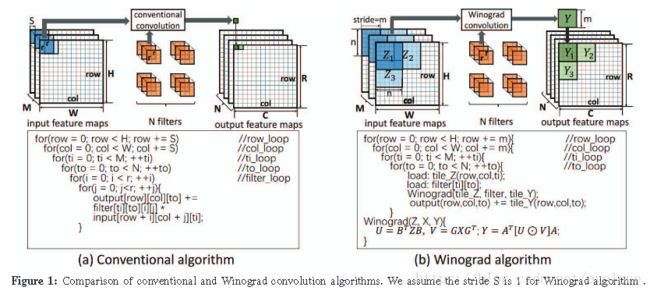
上图比较了传统卷积算法与基于winograd的卷积算法。
可以看出,传统卷积(a)共有6层循环,其中第一层是循环输入图片的行,第二层循环输入图片的列,第三层循环输入图片的channel数,第四层循环filter的数量(也就是输出的channel数),最后两层循环单个的filter(尺寸r x r)。
基于winograd算法的卷积计算,直接能看到4层循环,第一层循环是基于输入图片的行,第二层循环基于输入图片的列,第三层循环输入图片的channel数,第四层循环filter数(输出的channel数)。
注意:winograd的第一和第二层循环,步长与传统卷积的不同。
粗略来看,winograd比传统卷积少了两层循环。
但是,其实并不是。
传统卷积的最后两层循环,一共有r x r个乘法,及r x r -1个加法。
winograd因为算法的不同,采用增加加法去减少乘法,或者说用加法替代部分乘法。这一点,可参考第一部分的winograd算法分析。
所以,这么一看,基于winograd算法的卷积计算与传统卷积计算在前四层的循环是比较类似的,主要区别在最后两层,也就是商汤如何去实现基于winograd的卷积内核。
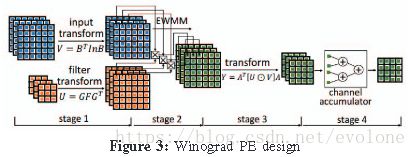
上图就是商汤论文中提到winograd卷积内核的实现方法。
一共分成4个stage.
stage1,对输入数据和filter根据矩阵进行转化。
stage2,元素对应相乘。
stage3,对相乘的结果按照转化矩阵进行转化,得到一个channel的结果。
stage4,如果有多个channel,那么所有上面的三个stage都是多个channel同时进行的,此时将所有channel的计算结果累加得到最终的结果。
因为商汤采用的是F(2,3)的公式,所以转化矩阵中的参数要么是1,要么是1/2,这些都不需要用乘法器,只需对数据进行移位就能得到中间结果,然后采用加法器就能得到转化后的结果。
搞清楚了winograd卷积内核后,再来看看商汤的整体结构。
整体上,商汤设计的基于winograd的结构如下所示:
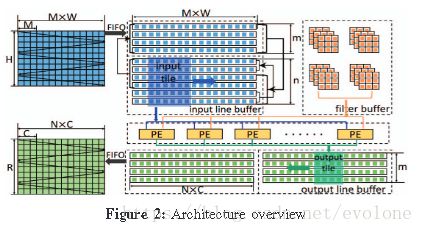
商汤论文中说内部的winograd卷积内核是一个阵列的形式,阵列的尺寸由输入channel数和filter数(输出channel数)决定。
下面猜测一下内部winograd卷积内核阵列的组成形式。因为商汤论文没有细说,只能猜测了。
因为内部要将输入数据复用到每一个filter。所以,数据应该是类似谷歌TPU那样,数据每个周期传递到相邻的内核单元。
又因为,在内核的stage4会对各个channel的计算结果进行累加,从图来看类似同时累加,结合内核的尺寸与channel数有关,那么大胆假设是多个channel同时计算。
那么商汤的矩阵结构就应该是这样:
每一行的winograd卷积内核单元计算的是同一个filter的不同的channel的结果。
不同的行,代表计算不同的filter的结果。
3.winograd算法的FPGA实现与TPU等其他同类处理器的对比分析
这样有个问题,如果每层的卷积核的参数不同,比如channel数不同,那么,商汤的设计方案内部的卷积内核阵列的尺寸就不一样,岂不是每次都要重新烧录FPGA?
当然,因为一般来说,目前比较成熟的深度学习算法的filter数或channel数都比较大,比如32/64/128/256/512等,应该说不可能每次都是完整按照filter数和channel数去定义winograd卷积内核的阵列。毕竟谷歌TPU1中的乘法阵列尺寸也才256×256。
一个不靠谱的估计,商汤会将这么大规模的filter数和channel数,拆分提取一个合适的最大公因数,比如32,定义内核阵列的尺寸。然后,若filter数和channel数超过32的,就会多循环几次就是了。这样的话,控制稍微有些复杂,还要消耗一定的存储空间。
最后,商汤把自己的设计与其他设计(包括基于FPGA的和GPU的)相比,还是有优势的。
没有看到与TPU的对比,颇为遗憾。
不知道基于winograd算法的实现,可看作脉动矩阵的一维应用(毕竟只传递了计算的输入数据,并不传递计算的部分和),与谷歌TPU(脉动矩阵的二维应用,同时传递输入数据和计算的部分和)做比较,在同量级的资源下,真正跑起来,谁更厉害。
谷歌的TPU的脉动矩阵设计,可以针对任意的filter数和channel数,另外filter的尺寸也并不局限于3 x 3,而是可以任意形式的矩阵(长方形/正方形都可以)。TPU只需要对应修改控制参数即可,而不用更改内部的乘法矩阵结构。从这一点来看,TPU比商汤的设计更具有灵活性。
最后的最后,商汤还是很厉害的。(这条五毛)