Java连接Spark Standalone集群
软件环境:
spark-1.6.3-bin-hadoop2.6、hadoop-2.6.4、jdk1.7.0_67、IDEA14.1.5 ;
Hadoop集群采用伪分布式安装,运行过程中只启动HDFS;Spark只启动一个Worker;使用虚拟机搭建Hadoop、Spark集群;Idea直接安装在Win10上;192.168.128.128是虚拟机ip;本机ip是:192.168.0.183;
Java连接Spark集群,如果采用YARN的方式,可以参考:Java Web提交任务到Spark ;写此篇的初衷是,在使用的过程中发现使用YARN调用Spark集群效率太低,所以尝试使用Java直接连接Spark Standalone集群。同时,需要说明一点,这里使用的是一个节点,如果使用多个节点情况可能有所不同。
本次测试一共进行了5次实验,最终达到一个既可以连接Spark Standalone集群,同时可以监控该任务的目的。所有代码可以在 https://github.com/fansy1990/JavaConnectSaprk01 下载。
任务1:设置master直接连接
1.1. 创建Scala工程
设置SDK、JDK以及spark-assembly的jar包到Classpath,创建好的工程如下:
1.2 创建示例程序
这里使用的是单词计数程序,代码如下:
package demo
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by fansy on 2017/7/5.
*/
object WordCount {
def main(args: Array[String]) {
val input = "hdfs://192.168.128.128:8020/user/root/magic"
val output =""
val appName = "word count"
val master = "spark://192.168.128.128:7077"
val conf = new SparkConf().setAppName(appName).setMaster(master)
val sc = new SparkContext(conf)
val line = sc.textFile(input)
line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect().foreach(println)
sc.stop()
}
}

ClassNotFound错误,出现这个错误,肯定是类找不到了,为什么找不到呢?
1.3 问题分析
如果要分析这个问题,那么需要连接Spark执行过程,看日志:
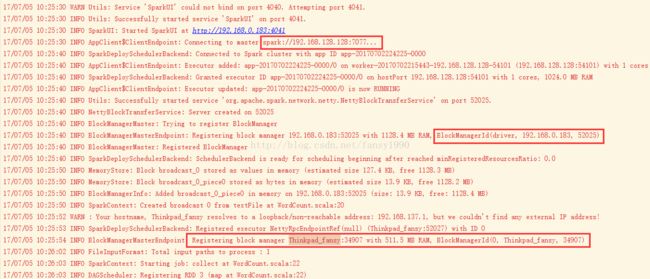
从日志中可以看出,程序运行后,会先去连接Master,连接上Master后,会在启动程序的地方,也就是本机win10上面启动Driver(其实可以理解为启动BlockManager),Driver程序控制整个APP的生命周期,同时SparkContext也在这个上面运行。接着,Master就会分配Worker的资源给这个App,供App使用运行自己的业务逻辑。所以实际运行任务的是Worker,Worker上面运行demo.WordCount的逻辑,但是并没有把demo.WordCount发给Worker,所以导致Worker找不到demo.WordCount这个类,也就会出现ClassNotFound的错误了。
任务2:添加业务逻辑Jar路径,连接Master
2.1 修改代码
如果需要添加对应的jar路劲,只需在代码中添加addJars即可,如下:
val jars =Array("C:\\Users\\fansy\\workspace_idea_tmp\\JavaConnectSaprk01\\out\\artifacts\\wordcount\\wordcount.jar")
val conf = new SparkConf().setAppName(appName).setMaster(master).setJars(jars)2.2 运行代码,观察结果
打包后,运行代码,结果如下:
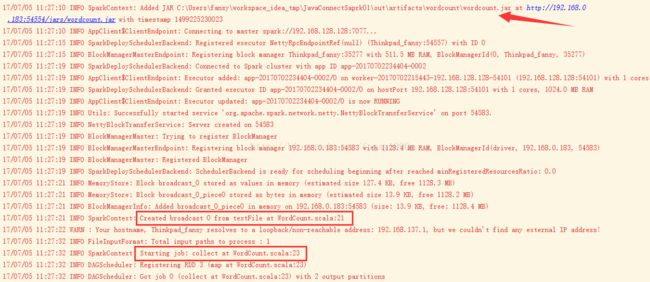
会发现,出现多了一行日志,把该Jar包添加到了Driver所在机器的路径上(可以理解为声明了一个公共的Classpath,或者理解为Worker就可以访问到了);
同时任务可以往下运行,继续运行,可以得到结果:
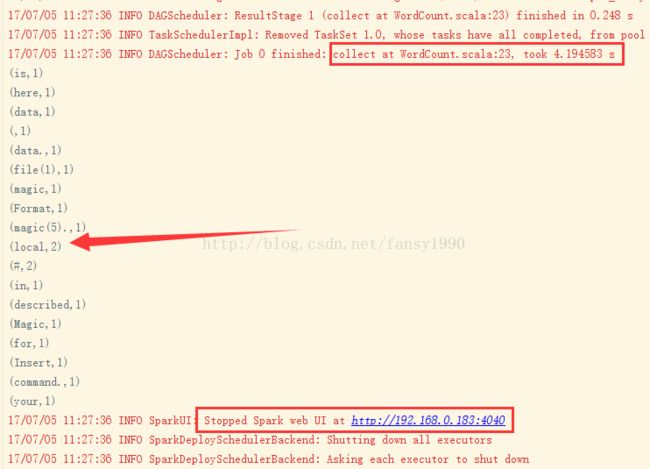
可以看到打印的单词统计的结果。
任务3 Driver运行在不同节点的尝试
3.1 任务描述
在使用Spark On YARN的方式提交Spark任务的时候,可以让Driver运行在集群中,即Cluster模式。这样,如果同时有多个客户端提交任务,就不会占用客户端太多的资源(想象一下,如果一个Driver需要默认256M内存资源,那100个客户端就是25G左右内存了),而是占用集群资源。所以是否可以通过设置,使得Driver不在win10上运行,而在集群上运行?
注意:这里如果要采用这种模式,那么集群只要要有额外资源供除了worker使用外,还需要给Driver预留一定资源。
3.2 尝试修改driver.host参数
修改代码,添加:
val conf = new SparkConf().setAppName(appName).setMaster(master).setJars(jars)
.set("spark.eventLog.enabled","true")
.set("spark.eventLog.dir","hdfs://node10:8020/eventLog")
.set("spark.driver.host","192.168.128.128")
.set("spark.driver.port","8993")
val sc = new SparkContext(conf)任务4 Java线程运行Spark程序提交到Spark StandAlone集群
4.1 任务实现思路
既然使用任务2可以提交任务到Spark Standalone集群,并且能正确运行,那么是否可以设置一个多线程用于调用这个APP,然后在主程序中查看这个多线程运行情况,根据线程任务返回值,判断任务是否执行成功。
4.2 任务实现
线程类:
package demo03;
import java.util.concurrent.Callable;
/**
* 线程任务
* Created by fansy on 2017/7/5.
*/
public class RunTool implements Callable {
private String input;
private String output;
private String appName;
private String master;
private String jars;
private String logEnabled;
private String logDir;
public RunTool(){}
public RunTool(String[] args){
this.input = args[0];
this.output = args[1];
this.appName = args[2];
this.master = args[3];
this.jars = args[4];
this.logEnabled = args[5];
this.logDir = args[6];
}
@Override
public Boolean call() throws Exception {
return WordCount.run(new String[]{input,output,appName,master,jars,logEnabled,logDir});
}
}
主类:
package demo03;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* Created by fansy on 2017/7/5.
*/
public class Driver {
public static void main(String[] args) {
// 主类中,每2秒刷新次,看下线程任务执行状态,最后根据线程任务返回值,判断任务是否执行成功;
任务5 加入多信息监控
5.1 任务描述
在任务4中已经可以实现相关任务调用、任务监控的功能,但是在任务监控这块并没有执行APP的一些信息,比如一共有多少个Job,每个job运行的状态等等,这节就是加入这些信息。
5.2 实现思路
在任务4中的demo03.WordCount中发现,在初始化SparkContext后,就会有一个APPID了,所以这里可以把初始化SparkContext和实际运行业务逻辑的代码分开,而多线程的任务调度放在业务逻辑上。
在主类中,先初始化SparkContext,获取sc;然后把此sc传入业务逻辑中,供其使用,在使用完成后,在业务逻辑类中关闭sc。最后在主类中使用sc来监控App执行情况,这里需要注意的是,使用sc来监控App的执行情况,只能监控到App里面的Job的状态,如成功或失败。这里需要注意的是Job的成功与失败和最后任务的成功和失败是有区别的,Job可能会fail,但是job fail的App,其最终的结果可能是成功执行的。所以这里还需要加上总任务的执行情况,也就是使用任务4中的返回值来判断。
这里需要明确一点:SparkContext启动后,可以运行多个job;而AppID对应一个SparkContext;但是Job的个数不是SparkContext可以预知的,也就是说业务逻辑代码生成的Job可以是多个的,也就是说不能够通过job运行情况来判断整个任务运行的失败与否。
5.3 具体实现
Driver类:
package demo04;
import org.apache.spark.SparkContext;
import org.apache.spark.SparkJobInfo;
import org.apache.spark.SparkStatusTracker;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* Created by fansy on 2017/7/5.
*/
public class Driver {
public static void main(String[] args) throws InterruptedException {
String master = "spark://node10:7077";
String appName = "wordcount" + System.currentTimeMillis();
String[] jars = "C:\\Users\\fansy\\workspace_idea_tmp\\JavaConnectSaprk01\\out\\artifacts\\wordcount\\wordcount.jar".split(",");
String logEnabled = "true";
String logDir = "hdfs://node10:8020/eventLog";
String[] arg = new String[]{
"hdfs://node10:8020/user/root/magic",
""
};
// 1.获取SC
SparkContext sc = Utils.getSc(master, appName, jars, logEnabled, logDir);
// 2. 提交任务 线程
FutureTask future = new FutureTask<>(new WordCount(sc, arg));
new Thread(future).start();
// 3. 监控
String appId = sc.applicationId();
System.out.println("AppId:"+appId);
SparkStatusTracker sparkStatusTracker = null;
int[] jobIds ;
SparkJobInfo jobInfo;
while (!sc.isStopped()) {// 如果sc没有stop,则往下监控
Thread.sleep(2000);
// 获取所有Job
sparkStatusTracker = sc.statusTracker();
jobIds = sparkStatusTracker.getJobIdsForGroup(null);
for(int jobId :jobIds){
jobInfo = sparkStatusTracker.getJobInfo(jobId).getOrElse(null);
if(jobInfo == null){
System.out.println("JobId:"+jobId+",相关信息获取不到!");
}else{
System.out.println("JobId:" + jobId + ",任务状态:" + jobInfo.status().name());
}
}
}
// 4. 检查线程任务是否返回true
boolean flag = true;
while(flag){
try{
Thread.sleep(200);
System.out.println("Job closing ...");
if(future.isDone()){
flag = false;
if(future.get().booleanValue()){
System.out.println("Job "+appId+" done with success state");
}else{
System.out.println("Job "+appId+" failed!");
}
}
}catch (InterruptedException|ExecutionException e){
e.printStackTrace();
}
}
}
}
Utils工具类主要是获取SparkContext,每次获取都是一个新的SparkContext,如下:
package demo04
import org.apache.spark.{SparkContext,SparkConf}
/**
* Created by fansy on 2017/7/6.
*/
object Utils {
/**
* 获得sc
* @param master
* @param appName
* @param jars
* @return
*/
def getSc(master:String,appName:String,jars:Array[String],logEnabled:String,logDir:String):SparkContext = {
val conf = new SparkConf().setMaster(master).setAppName(appName).setJars(jars)
.set("spark.eventLog.enabled",logEnabled)
.set("spark.eventLog.dir",logDir)
new SparkContext(conf)
}
}
再次运行,即可监控到App里面每个Job的具体信息了。
思考
1. 任务3的尝试失败了,但是是否有方法设置Driver运行的地方呢?如果所有Driver都在Client端运行,那么Client需要较高配置才行;
2. 这里使用的是Java程序直接连接的方式,如果是Java Web呢?是否需要做些环境配置?
3. 使用Java 直连Spark Standalone的方式确实可以提交效率,不过如果需要同时运行MR的程序,那么使用YARN的方式会方便一点,至少不需要部署Spark集群了。
分享,成长,快乐
脚踏实地,专注
转载请注明blog地址:http://blog.csdn.net/fansy1990
脚踏实地,专注
转载请注明blog地址:http://blog.csdn.net/fansy1990