python GIL全局解释器锁的理解
GIL的全称是:Global Interpreter Lock,意思就是全局解释器锁,这个GIL并不是python的特性,他是只在Cpython解释器里引入的一个概念,而在其他的语言编写的解释器里就没有这个GIL例如:Jython,Pypy
为什么会有gil?:
随着电脑多核cpu的出现核cpu频率的提升,为了充分利用多核处理器,进行多线程的编程方式更为普及,随之而来的困难是线程之间数据的一致性和状态同步,而python也利用了多核,所以也逃不开这个困难,为了解决这个数据不能同步的问题,设计了gil全局解释器锁。
说到gil解释器锁,我们容易想到在多线程中共享全局变量的时候会有线程对全局变量进行的资源竞争,会对全局变量的修改产生不是我们想要的结果,而那个时候我们用到的是python中线程模块里面的互斥锁,哪样的话每次对全局变量进行操作的时候,只有一个线程能够拿到这个全局变量;看下面的代码:
import threading global_num = 0 def test1(): global global_num for i in range(1000000): global_num += 1 print("test1", global_num) def test2(): global global_num for i in range(1000000): global_num += 1 print("test2", global_num) t1 = threading.Thread(target=test1) t2 = threading.Thread(target=test2) t1.start() t2.start()
在上面的例子里,我们创建了两个线程来争夺对global_num的加一操作,但是结果并非我们想要的,所以我们在这里加入了互斥锁
import threading import time global_num = 0 lock = threading.Lock() def test1(): global global_num lock.acquire() for i in range(1000000): global_num += 1 lock.release() print("test1", global_num) def test2(): global global_num lock.acquire() for i in range(1000000): global_num += 1 lock.release() print("test2", global_num) t1 = threading.Thread(target=test1) t2 = threading.Thread(target=test2) start_time = time.time() t1.start() t2.start()
这回能得到我们想要的结果,在之前我的博文里也说到过这个问题,在这里就不多累赘了。
而在Cpython解释器中,当我们的python代码有一个线程开始访问解释器的时候,GIL会把这个大锁给锁上,此时此刻其他的线程只能干等着,无法对解释器的资源进行访问,这一点就跟我们的互斥锁相似。而只是这个过程发生在我们的Cpython中,同时也需要等这个线程分配的时间到了,这个线程把gil释放掉,类似我们互斥锁的lock.release()一样,另外的线程才开始跑起来,说白了,这无疑也是一个单线程。
看如下的图,也只是把我第一段代码的变量变成count,因为这里我们忽略掉互斥锁,只考虑gil
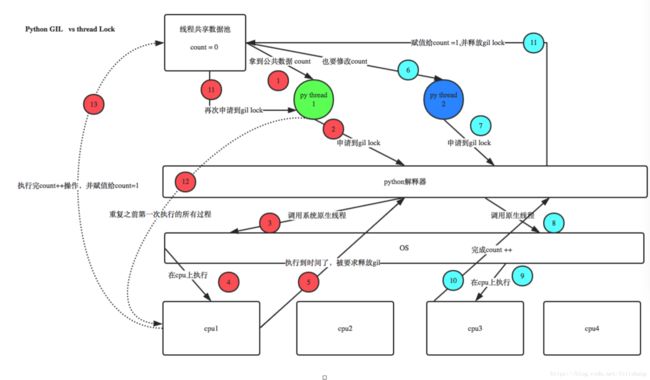
执行过程:1.thread1拿到全局变量count
2.thread1申请到python解释器的gil
3.解释器调用系统原生线程
4.在cpu1上执行规定的时间
5.执行时间到了,要求释放gil@等下一次得到gil的时候,程序从这里接着这一次开始执行
6.thread2拿到了全局变量,此时thread1对全局count的操作并未完成,所以thread拿到的和thread拿到的count其实是相同的,这样也很好解释为什么结果不是200万 而是少于200万
7.thread2申请到了gil锁
8.调用原生的线程
9.如果是单核cpu则会在cup1上执行,(不是重点),如图在cpu3上执行
10.执行规定的时间,此时完成了对count的加一操作
11.执行时间还未到,线程2执行完对count操作,并给count加一,并且释放了gil锁
12.线程1又申请到了gil锁,重复之前的操作。
13.线程1执行万对count的操作,执行时间到,释放gil锁
综合上面的步骤就能很好的理解gil锁
哪些情况适合用多线程呢:
只要在进行耗时的IO操作的时候,能释放GIL,所以只要在IO密集型的代码里,用多线程就很合适
哪些情况适合用多进程呢:
用于计算密集型,比如计算某一个文件夹的大小。