TensorFlow 模型优化工具包 — 训练后整型量化
精品文章,第一时间送达
![]()
转载自:Google,未经允许不得二次转载
模型优化工具包是一套先进的技术工具包,可协助新手和高级开发者优化待部署和执行的机器学习模型。自推出该工具包以来, 我们一直努力降低机器学习模型量化的复杂性
(https://www.tensorflow.org/lite/performance/post_training_quantization)。
最初,我们通过“混合运算”为训练后量化提供支持,该方法可量化模型参数(例如权重),但以浮点方式执行部分计算。今天,我们很高兴宣布推出一款新工具:训练后整型量化。整型量化是一种通用技术,可降低模型权重和激活函数的数值精度,从而减少内存并缩短延迟时间。
优化模型以缩减尺寸、延时和功耗,使准确率损失不明显
为何应使用训练后整型量化
我们之前发布的“混合”训练后量化方法可在许多情况下减少模型大小和延迟时间,但却必须进行浮点计算,这可能不适用于所有硬件加速器(如 Edge TPU, https://cloud.google.com/edge-tpu/),而只适用于 CPU。
注:“混合”训练后量化 链接
https://www.tensorflow.org/lite/performance/post_training_quantization
我们已推出全新的训练后整型量化方法,可让用户使用已经过训练的浮点模型,并对其进行充分量化,仅使用 8 位带符号整数(即“int8”)。凭借这一量化方案,我们可以在许多模型中获得合理的量化模型准确率,而不必重新训练依靠量化感知 (quantization-aware) 训练的模型。借助这一新工具,模型大小将缩小为原来的 1/4,却能得到更大的 CPU 速度提升。此外,Edge TPU 等固定点硬件 (fixed point hardware) 加速器也将能运行这些模型。
与量化感知训练相比,此工具更易于使用,并可在大多数模型中实现出色的准确率。目前可能仍存在需要进行量化感知训练的用例,但我们希望随着训练后工具的不断改进,这种情况会越来越少。
注:量化感知训练 链接https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/quantize
总之,如果用户希望减少 CPU 大小和延迟时间,即应使用“混合”训练后量化工具。如果旨在大幅改进 CPU 或兼容固定点加速器,则应使用此训练后整型量化工具;若会影响模型准确率,则可能还需使用量化感知训练。
如何启用训练后整型量化
我们的整型量化工具需要使用一个小型代表性数据校正集。只需为转换器提供 representative_dataset 生成器,优化参数便会对输入模型执行整型量化。
1def representative_dataset_gen(): 2 data = tfds.load(...) 3 4 for _ in range(num_calibration_steps): 5 image, = data.take(1) 6 yield [image] 7 8converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) 9converter.optimizations = [tf.lite.Optimize.DEFAULT]10converter.representative_dataset = tf.lite.RepresentativeDataset(11 representative_dataset_gen)def representative_dataset_gen():
2 data = tfds.load(...)
3
4 for _ in range(num_calibration_steps):
5 image, = data.take(1)
6 yield [image]
7
8converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
9converter.optimizations = [tf.lite.Optimize.DEFAULT]
10converter.representative_dataset = tf.lite.RepresentativeDataset(
11 representative_dataset_gen)模型是否经过完全量化?
与现有的训练后量化功能类似,默认情况下,未进行量化操作的算子将自动以浮点方式执行。这样可使转换过程顺利进行,并会生成始终在常规移动 CPU 上执行的模型,鉴于 TensorFlow Lite 将在只使用整型的加速器中执行整型运算,并在执行浮点运算时回退到 CPU。 若要在完全不支持浮点运算的专用硬件(如某些机器学习加速器,包括 Edge TPU)上完整执行运算,您可以指定标记以仅输出整型运算:
1converter.target_ops = [tf.lite.OpSet.TFLITE_BUILTINS_INT8]converter.target_ops = [tf.lite.OpSet.TFLITE_BUILTINS_INT8]
当使用此标记且运算没有可量化的整型对应项时,TensorFlow Lite 转换器将报错。
模型仅需少量数据
实验中发现,使用数十个可表明模型在执行期间所见内容的代表性示例,足以获得最佳准确率。例如,我们仅使用 ImageNet 数据集中的 100 张图像对模型进行校准后,即得出了以下准确率。
结果
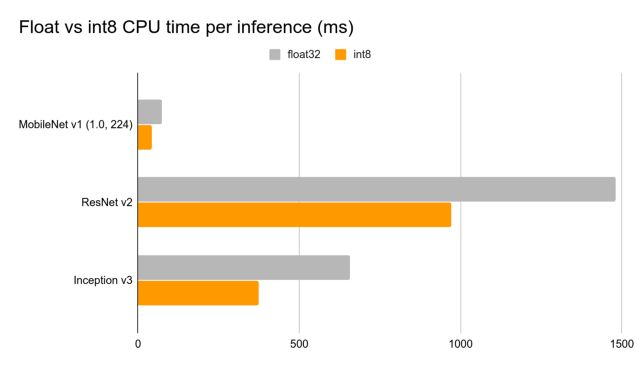
延时
与浮点模型相比,量化模型在 CPU 上的运行速度提升了2到4倍,模型压缩提升4倍。我们还希望通过硬件加速器(如 Edge TPU)进一步提速。
准确率
仅使用 ImageNet 数据集中的 100 张校准图像,完全量化的整型模型便获得了与浮点模型相当的准确率(MobileNet v1 损失了 1% 的准确率)。

整型模型的工作原理
记录动态范围
以上新工具的工作原理是:记录动态范围,在浮点 TensorFlow Lite 模型上运行多个推理,并将用户提供的代表性数据集用作输入。我们会使用所记录的推理值,以确定在整型算法中执行模型全部张量所需的缩放比例参数。
Int8 量化方案
需要注意的是,我们的全新量化规范已实现这一训练后用例,且该用例可针对某些运算使用每轴量化。在我们新增每轴量化之前,由于准确率下降,训练后整型量化并不实用;但每轴量化却具有准确率优势,能够为许多模型实现更接近于浮动模型的准确率。
8 位量化使用以下公式得出的值近似于浮点值:
real_value = (sint8_value — zero_point) * scale.每轴(也称为“每通道”)或每层权重以 int8 二进制补码表示,数值范围为 [-127, 127],零点时则等于 0。
每层激活函数/输入以 int8 二进制补码表示,数值范围为 [-128, 127],零点范围为 [-128, 127]。如需了解更多详情,请参阅完整量化规范(https://www.tensorflow.org/lite/performance/quantization_spec)。
量化感知训练方面有何打算?
我们希望尽可能简化量化方法。因此,我们很期待能够通过某种方法在训练后实现模型的量化!但是,我们也明白,某些模型在通过量化进行训练时已经拥有最佳质量。所以,我们也在致力开发量化感知训练 API。同时,我们也鼓励您尝试使用训练后量化法,因为它也许能满足模型的所有需求!
文档和教程
您可以在 TensorFlow 网站上找到关于训练后整型量化、新量化规范以及训练后整型量化教程的详细信息。我们非常乐于了解您对此工具的使用情况 — 欢迎您分享自己的案例!
训练后整型量化
(https://www.tensorflow.org/model_optimization/guide/quantization)
新量化规范
(https://www.tensorflow.org/lite/performance/quantization_spec)
训练后整型量化教程
(https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/tutorials/post_training_integer_quant.ipynb)
案例分享
(https://services.google.com/fb/forms/tensorflowcasestudy/)
致谢
感谢 TensorFlow 模型优化团队: Suharsh Sivakumar、Jian Li、Shashi Shekhar、Yunlu Li、Alan Chiao、Raziel Alvarez、Lawrence Chan、Daniel Situnayake、Tim Davis、Sarah Sirajuddin
Reviewed by:linsong
你也许还想看:
● 干货 | NLP算法岗大厂面试经验与路线图分享
● 怎样设计最优的卷积神经网络架构?| NAS原理剖析
● 给机器学习面试者的十项建议 | 面试官角度
欢迎扫码关注:

![]() 点击下方 | 阅读原文 | 了解更多
点击下方 | 阅读原文 | 了解更多