小项目(逻辑回归)--信用卡数据异常检测
数据下载:creditcard.csv
1.数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('creditcard.csv')
print(data.head(n=5))
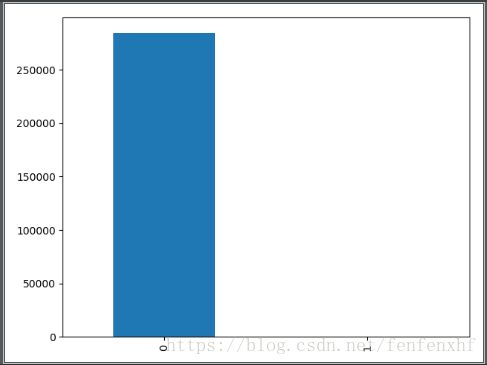
countClasses = pd.value_counts(data['Class'],sort=True).sort_index() #计算class列中不同属性的数据的个数
countClasses.plot(kind='bar') #简单的pandas也可以画图
plt.show()

2.发现Amount这一列数值比较大,在机器学习中特征的重要性偏爱数值比较大的特征,解决办法可以标准化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler #sklearn数据预处理模块
data = pd.read_csv('creditcard.csv')
dataMatrix = np.mat(data) #将数据变换成矩阵形式
X = dataMatrix[:,:-1] #数据集
y = dataMatrix[:,-1] #标签
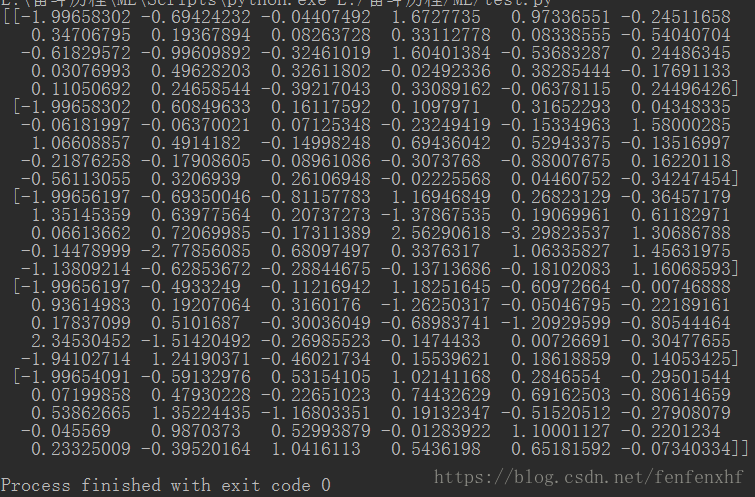
scaler = StandardScaler().fit(X) #StandardScaler()这个小括号一定不能忘记,#标准化:(x-mean)/std
dataStand = scaler.transform(X)
print(dataStand[:5,:])
3.发现样本分布非常不均衡
解决方案:下采样(将多的样本随机选取和少样本一样的数目),过采样(将少样本数目增加到多样本数目)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler #sklearn数据预处理模块
data = pd.read_csv('creditcard.csv')
dataMatrix = np.mat(data)
X = dataMatrix[:,:-1]
y = dataMatrix[:,-1]
#print(len(y)) #284807
scaler = StandardScaler().fit(X) #标准化:(x-mean)/std
dataStand = scaler.transform(X)
#print(dataStand[:5,:])
#下采样
numberRecordsFraud = len(data[data.Class == 1]) #为1样本的个数
#print(numberRecordsFraud) #492
fraud_indices = np.array(data[data.Class == 1].index) #为1的样本的索引
#print(fraud_indices)
normal_indices = data[data.Class == 0].index #为0数据的索引
random_normal_indices = np.random.choice(normal_indices,numberRecordsFraud,replace=False)
random_normal_indices = np.array(random_normal_indices)
underSampleIndices = np.concatenate([fraud_indices,random_normal_indices],axis=0) #默认按列进行合并
#print(underSampleIndices.shape) #(984,)
underSampleData = data.iloc[underSampleIndices,:] #把索引还原成对应的数据
print(underSampleData.shape) #(984, 31)
X_undersample = underSampleData[:,:-1]
y_undersample = underSampleData[:,-1]
4.交叉验证
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler #sklearn数据预处理模块
from sklearn.cross_validation import train_test_split #sklearn数据集分割模块
data = pd.read_csv('creditcard.csv')
dataMatrix = np.mat(data)
X = dataMatrix[:,:-1]
y = dataMatrix[:,-1]
#print(len(y)) #284807
scaler = StandardScaler().fit(X) #标准化:(x-mean)/std
dataStand = scaler.transform(X)
#print(dataStand[:5,:])
#下采样
numberRecordsFraud = len(data[data.Class == 1]) #为1样本的个数
#print(numberRecordsFraud) #492
fraud_indices = np.array(data[data.Class == 1].index) #为1的样本的索引
#print(fraud_indices)
normal_indices = data[data.Class == 0].index #为0数据的索引
random_normal_indices = np.random.choice(normal_indices,numberRecordsFraud,replace=False)
random_normal_indices = np.array(random_normal_indices)
underSampleIndices = np.concatenate([fraud_indices,random_normal_indices],axis=0) #默认按列进行合并
#print(underSampleIndices.shape) #(984,)
underSampleData = data.iloc[underSampleIndices,:] #把索引还原成对应的数据
#print(underSampleData.shape) #(984, 31)
X_undersample = underSampleData.ix[:,:-1] #需要加ix
y_undersample = underSampleData.ix[:,-1]
"""
loc——通过行标签索引行数据
iloc——通过行号索引行数据
ix——通过行标签或者行号索引行数据(基于loc和iloc 的混合)
同理,索引列数据也是如此!
"""
#交叉验证
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
#用原始数据的测试集来做测试,比下采样的数据要好
x_train_undersample,x_test_undersample,y_train_undersample,y_test_undersample = \
train_test_split(X_undersample,y_undersample,test_size=0.3,random_state=0)
#print(len(x_train)) #199364
#print(len(x_train_undersample)) #688
下采样可能会出现这样的问题
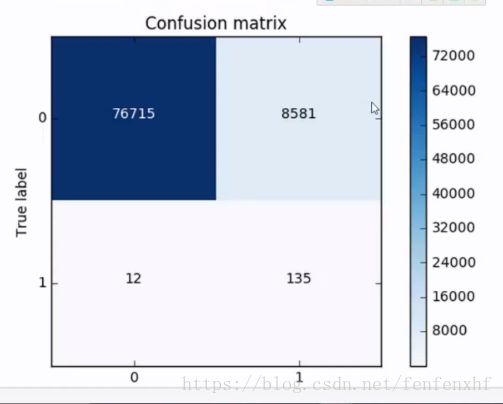
可以看到召回率没什么问题,但是我们把真实为0的预测成1的数据量很大。
5.模型评估
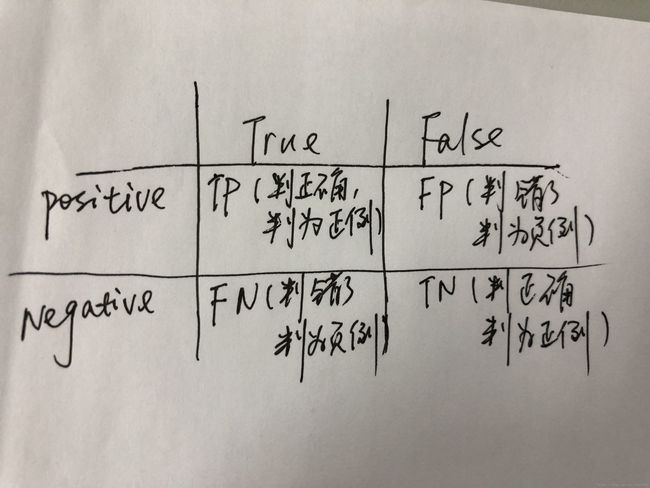
recall_score = TP / (TP + FN)
6.预测和评估
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler #sklearn数据预处理模块
from sklearn.cross_validation import train_test_split,cross_val_score,KFold
#切分数据集分为训练集和测试集;交叉验证评估结果;交叉验证切分的份数(也就是验证的次数)
from sklearn.linear_model import LogisticRegression #逻辑回归模块
from sklearn.metrics import confusion_matrix,recall_score,classification_report
#混淆矩阵;召回率;精确度/召回率/F1值
data = pd.read_csv('creditcard.csv')
dataMatrix = np.mat(data)
X = dataMatrix[:,:-1]
y = dataMatrix[:,-1]
#print(len(y)) #284807
scaler = StandardScaler().fit(X) #标准化:(x-mean)/std
dataStand = scaler.transform(X)
#print(dataStand[:5,:])
#下采样
numberRecordsFraud = len(data[data.Class == 1]) #为1样本的个数
#print(numberRecordsFraud) #492
fraud_indices = np.array(data[data.Class == 1].index) #为1的样本的索引
#print(fraud_indices)
normal_indices = data[data.Class == 0].index #为0数据的索引
random_normal_indices = np.random.choice(normal_indices,numberRecordsFraud,replace=False)
random_normal_indices = np.array(random_normal_indices)
underSampleIndices = np.concatenate([fraud_indices,random_normal_indices],axis=0) #默认按列进行合并
#print(underSampleIndices.shape) #(984,)
underSampleData = data.iloc[underSampleIndices,:] #把索引还原成对应的数据
#print(underSampleData.shape) #(984, 31)
X_undersample = underSampleData.ix[:,:-1] #需要加ix
y_undersample = underSampleData.ix[:,-1]
"""
loc——通过行标签索引行数据
iloc——通过行号索引行数据
ix——通过行标签或者行号索引行数据(基于loc和iloc 的混合)
同理,索引列数据也是如此!
"""
#交叉验证
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
#用原始数据的测试集来做测试,比下采样的数据要好
x_train_undersample,x_test_undersample,y_train_undersample,y_test_undersample = \
train_test_split(X_undersample,y_undersample,test_size=0.3,random_state=0)
#print(len(x_train)) #199364
#print(len(x_train_undersample)) #688
"""
#用下采样数据来训练和预测
clf = LogisticRegression(C=0.03) #惩罚参数;默认惩罚项为l2(也就是W**2惩罚项)
clf.fit(x_train_undersample,y_train_undersample) #训练
y_pred_undersample = clf.predict(x_test_undersample) #预测
recall_sco = recall_score(y_test_undersample,y_pred_undersample) #召回率
print(recall_sco) #0.9115646258503401
"""
#用原始数据来训练和预测
clf = LogisticRegression(C=0.01)
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
recall_sco = recall_score(y_test,y_pred)
print(recall_sco) #0.564625850340136
#可以看到效果就不是很好
7.过采样(生成少样本的数据):尽量使用过采样而不是下采样
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler #sklearn数据预处理模块
from sklearn.cross_validation import train_test_split,cross_val_score,KFold
#切分数据集分为训练集和测试集;交叉验证评估结果;交叉验证切分的份数(也就是验证的次数)
from sklearn.linear_model import LogisticRegression #逻辑回归模块
from sklearn.metrics import confusion_matrix,recall_score,classification_report
#混淆矩阵;召回率;精确度/召回率/F1值
from imblearn.over_sampling import SMOTE #过采样生成少样本模块
data = pd.read_csv('creditcard.csv')
dataMatrix = np.mat(data)
X = dataMatrix[:,:-1]
y = dataMatrix[:,-1]
#print(len(y)) #284807
scaler = StandardScaler().fit(X) #标准化:(x-mean)/std
dataStand = scaler.transform(X)
#print(dataStand[:5,:])
#过采样
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
oversample = SMOTE() #实例化
#只需要将训练集的少样本数据进行生成,不需要懂测试集
x_train_oversample,y_train_oversample = oversample.fit_sample(x_train,y_train)
print(len(y_train)) #199364
print(len(y_train_oversample)) #398038
#用过采样数据来训练和预测
clf = LogisticRegression(C=0.01)
clf.fit(x_train_oversample,y_train_oversample)
y_pred = clf.predict(x_test)
recall_sco = recall_score(y_test,y_pred)
print(recall_sco) #0.8843537414965986
#可以看到召回率相对于用原始数据显著提高
confusion_mat = confusion_matrix(y_test,y_pred)
print(confusion_mat) #下面的混淆矩阵明显比下采样的混淆矩阵的合理的多
