数字音频Mixer算法
1.1 问题提出
Mix的意思是混音,无论在自然界,还是在音频处理领域这都是非常普遍的现象。自然界里你能同时听到鸟鸣和水声,这是因为鸟鸣和水声的波形在空气中形成了叠加,耳朵听到后能区分鸟鸣和水声这两种波形。
在数字音频领域也是一样,比如你也可以一边打CS一边听歌,这是因为计算机把两个声音波形做了叠加。但是不同的是,计算机中的叠加,很容易造成越界。
比如
int plus1(int num0, int num1){
return num0+num1;
}
如果赋值int num0=0x70000000和int num1=0x70000000,运行后的result是0xE0000000,变换为十进制为-536870912。两个正数相加得到了负数,结果自然是错的。
我们知道,一个char的补码所能表示的数值范围是[-128, 127],写成16进制是[0x80,0x7F]。而一个int的补码的范围是[0x80000000,0x7FFFFFFF]。超出这个范围就是溢出。
如何防止溢出呢?最简单的做法是拓宽存储数据的容器,比如:
long long plus1(int num0, int num1){
return (long long)num0+(long long)num1;
}
赋值int num0=0x70000000和int num1=0x70000000,运行后的result是0xE0000000,变换为十进制为3758096384。这次没有溢出。
1.2 公式
怎么能做到不溢出呢?考虑这个公式
Z=A+B−AB,
如果A和B都在[0,1]范围内,那么:
0<=(1-A)(1-B)=1-A-B+AB<=1,那么
0<=Z<=1
这样,如果我们把A,B看做是两个输入波形,Z看做是一个输出波形的话,Z的上界和下界也在A和B的上界和下界内。也就是说,Z是不会溢出的。
对于3个输入信号来说,按照(1-A)(1-B)(1-C)运算,易得
Z=A+B+C−AB−AC−BC+ABC.
而对于取值范围不在[0,1]的信号,可以先转化为[0,1]来做。
比如A,B均在[0,255]范围内,则A/255在[0,1]内,则
Z/255=A/255+B/255-(A/255)*(B/255),那么
Z=A+B-AB/255
对于有符号的数,取值范围在[-128,127],则A’=(A+128)/255取值在[0,1]内,则
Z’=A’+B’−A’*B’,代入可得
(Z+128)/255=(A+128)/255+(B+128)/255-(A+128)/255*(B+128)/255,则
Z=A+B-(A+128)(B+128)/255+128
这种算法可以认为是简单的对输入信号进行了相加,并为了避免溢出,压缩了两个信号的和的波形。但是这种算法有个致命的缺点,那就是当两个信号相加没有溢出时,这种算法仍然压缩了波形,导致音质受损。而且过多的加减乘除的运算,会提升整个系统的功耗和复杂性,也会在四舍五入中降低数据的精度。
说句题外话,为了避免运算中声音信号精度的丢失,目前业界高端音频处理系统里都是用32位float采样来进行运算的,而输出的时候转化为16bit。
1.3 Android做法
我们看看成熟的软件是怎么做的。Android的Mixer在AudioMixer.cpp这个文件里,它针对不同的情况,有各种执行混音操作的函数,下面这个函数是处理无需重采样的立体声音频的。
voidAudioMixer::process__genericNoResampling(state_t* state, int64_t pts)
我们来看看它的处理方式:它是把各个track的声音数据相加。所谓声音数据,可以认为是一个个的采样点,Android默认支持的采样精度是16bit的,格式为signedPCM,所以每个采样点用有符号的16位数int16_t表示。如果直接加16bit的数据,肯定会造成16bit的值溢出,Android的做法是强转成int32_t,相加,并把和赋值给了32bit的数。注意,相加前乘上了音量,而表达音量的数据类型也是int32_t。这样,就能保证在这个过程中是不会溢出的。
voidAudioMixer::track__16BitsStereo(track_t* t, int32_t* out, size_t frameCount,
int32_t* temp __unused, int32_t* aux){
int32_t vl =t->prevVolume[0];
nt32_t vr =t->prevVolume[1];
const int16_t*in = static_cast
*out++ += (vl>> 16) * (int32_t) *in++;
*out++ += (vr>> 16) * (int32_t) *in++;
}
此时,混音后的数据已经存在out指向的buffer里了,然后再调用
convertMixerFormat(out, t1.mMixerFormat,outTemp, t1.mMixerInFormat, BLOCKSIZE * t1.mMixerChannelCount);
其中有函数ditherAndClamp,这个是把int32_t格式的源数据sums消减成int16_t,并把左右声道一起放入int32_t格式的out中。
void ditherAndClamp(int32_t* out, constint32_t *sums, size_t c)
{
size_t i;
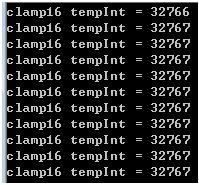
for (i=0 ; i int32_t l = *sums++; int32_t r = *sums++; int32_t nl = l >> 12; int32_t nr = r >> 12; l = clamp16(nl); r = clamp16(nr); *out++ = (r<<16) | (l & 0xFFFF); } } 看它的做法,一个声道的32bit的输入,先右移12位,也就是保留前20位,然后clamp16(clamp是“夹”的意思)成16位,此时左右声道都是16位的了。然后再把右声道放高位,左声道放低位这么组成一个32bit的数。 下面看看clamp16到底做了什么: static inline int16_t clamp16(int32_tsample) { if ((sample>>15) ^ (sample>>31)) sample = 0x7FFF ^ (sample>>31); return sample; } 这个函数仅仅是把溢出部分粗暴的去掉了。下面的测试程序可以很直观的看出来: int test() { for(int i=32766; i<=32776; i++){ int temp = clamp16(i); cout << "clamp16 tempInt = " << temp < } return 0; } 输出是: 我们知道,16位的有符号数的上界是0x7FFF,也就是32767。通过测试结果发现,小于它的数得到了保留,如32766;而大于它的数都被夹(clamp)到了32767。 那么,为什么Android要这么做呢?为什么不去优雅的保留信号的波形,而是选择让它直接消减掉呢(尽管这样势必会造成听感上的Distortion)? 可能就是因为 1. 混音的情况比较少见 2. 混音后溢出的情况也比较少见 3. 如果努力去保留信号的波形,势必会造成上一节提出的问题