【论文阅读纪录】UPSNet: A Unified Panoptic Segmentation Network
前言:
{
今天阅读的还是在之前的awesome semantic segmentation[1] 中看到的论文UPSNet[2],主要针对全景分割(Panoptic Segmentation)[3]。
}
正文:
{
在论文的第一节,作者提到了一个现象:目前分割任务包括语义分割(Semantic Segmentation)和实例分割(Instance Segmentation),忽略了这两种分割之间的联系(其实我之前也以为这两类任务的模型结构可以通用,甚至认为语义分割和实例分割是一个意思)。其区别大概就是:语义分割所分割的是不可数的stuff,而实例分割所分割的是可数的things。
此论文的模型统一了这两种分割,即形成了上述全景分割。
第三节是模型详述。具体结构见图1。
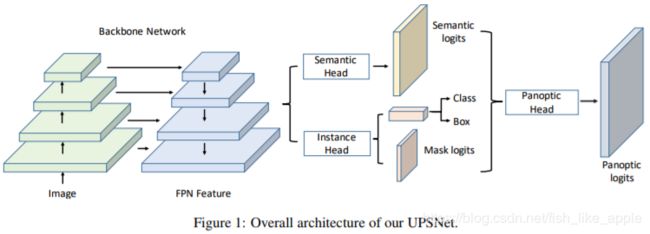
其中Backbone部分是Mask R-CNN(ResNet+FPN),之后是并联的两个Head,最后连接的是Panoptic Head。
Semantic Head的结构如图2所示。
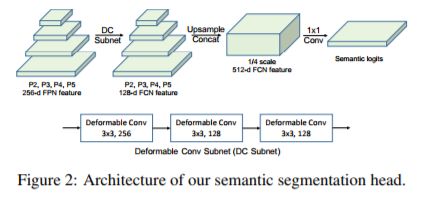
其中P2,P3,P4和P5的尺度分别为原始尺度的1/4,1/8,1/16和1/32,DC Subnet为可变形卷积的子网(四种尺度对应同一个子网)。
Instance Head的结构在这里没有专门的图,作者只是说它有3个输出,如图1所示。
Panoptic Head的结构如图3所示。
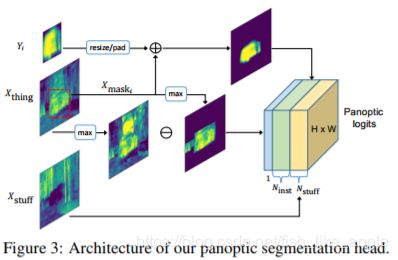
在上图中,Xstuff和Xthing都是Semantic Head的输出(这里可以看出Semantic Head也参与了实例分割),Y是Instance Head的mask输出(Yi指Y中第i个实例的特征图)。Panoptic Head没有对stuff部分进行额外处理,而是对thing部分进行了处理:首先,Xstuff直接就是输出的Ymask;把Xthing在对应bbox外的点全置0得到Xmask,之后,根据Xmask缩放和填充Y以得到Ymask,并且Xmask加上Ymask即得输出的Ninst部分;最后计算max(Xthing)-max(Xstuff),得到的结果即为输出多出来的1部分(max为通道的max,可把张量压缩成一个特征图)。
另外,作者介绍了三种度量:SQ(semantic quality),RQ(recognition quality),PQ(panoptic quality)。具体定义见式1。
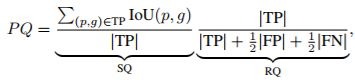 式1
式1
值得一提的是,图3中输出多出的一个通道其实是未知预测,也就是说,当此通道的值最大时,模型不确定对应点的类别。
第四节是实验部分。在COCO数据集上的训练配置为:
- 数据扩增:无;
- 优化相关设置:学习率为0.02(在第60000和80000次迭代时*0.1),权值衰减为0.0001,八个被均衡的损失(semantic head有2个,panoptic head有1个,RPN有2个,instance head有3个);
- 其他:没有BN,batch大小为1,一共训练90000次迭代。
另外,在测试阶段,去重的box IoU 阈值被设为0.5,并且box的置信阈值被设为0.6。
结果如下见表1和表2。
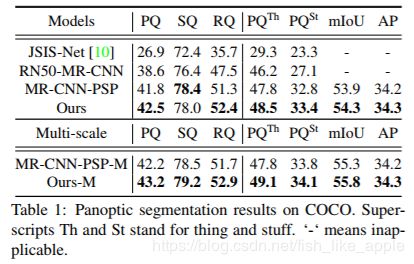
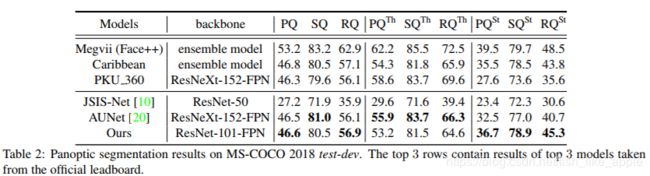
可以看出,新网络在backbone不是很复杂的情况下任然取得了不错的成绩。
}
结语:
{
遗憾的是新模型在COCO上的表现好像不是最好的。我还没了解过表1和表2中的其他模型,之后可能会学习一下。
能力有限,期待提问,欢迎拍砖。
参考资料:
{
[1] https://github.com/mrgloom/awesome-semantic-segmentation
[2] https://arxiv.org/pdf/1901.03784.pdf
[3] https://arxiv.org/pdf/1801.00868.pdf
}
}