多种文本分类模型tensoflow实现
导读:文本分类是NLP领域一项基础工作,在工业界拥有大量且丰富的应用场景。传统的文本分类需要依赖很多词法、句法相关的human-extracted feature,自2012年深度学习技术快速发展之后,尤其是循环神经网络RNN、卷积神经网络CNN在NLP领域逐渐获得广泛应用,使得传统的文本分类任务变得更加容易,准确率也不断提升,本文主要内容整理自网络,汇集了2014年以来,DL在文本分类领域相关的6篇论文,主要从CNN、RNN、Attention、RNN+CNN,或Word-level、Character-level角度出发,提升文本分类准确率。
文本附论文及源码下载地址。
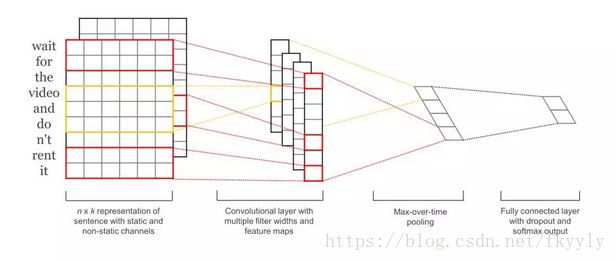
Convolutional Neural Networks for Sentence Classification
主要内容:基于预先训练好的word embedding,采用卷积神经网络( CNN )训练了一个word-level的句子分类器,并进行了一些列的实验来验证分类效果。实验证明,一个简单的CNN模型,只需要调整少量超参数和word embedding,在多个标准数据集上都取得了很好的效果。根据特定的任务对word embedding进一步fine-tuning,可以进一步提高分类效果。此外,还提出了一些对模型结构的进行简单修改的建议,以允许模型同时使用task-specific embedding和预先训练好的static embedding。
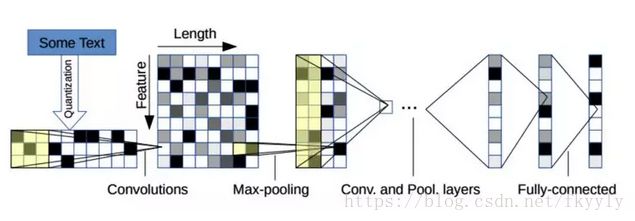
Character-level Convolutional Networks for Text Classification Very Deep Convolutional Networks for Text Classification
主要内容:本文主要研究字符级(character-level)卷积网络( ConvNets )在文本分类中的应用。构建了几个大规模数据集,以证明字符级的卷积网络可以获得更好的分类结果。并与传统模型(如bag-of-words、n - gram及TFIDF变体)和深度学习模型(如基于单词的ConvNets和递归神经网络)进行了比较。
Very Deep Convolutional Networks for Text Classification
主要内容:本文是首次将非常深度卷积网络应用于文本处理。NLP领域使用最多的DL模型有递归神经网络,特别是LSTMs和卷积神经网络。但与计算机视觉领域的深层卷积网络(Google InceptionNet,ResNet)相比,NLP常用的深度学习模型深度还是比较浅。本文提出了一种新的,character-level的文本处理架构( VDCNN ),只使用小的卷积和池化操作。实验证明,模型的性能随着深度的增加而增加:最后达到29个卷积层,并在多个文本分类任务上的取得了最优的成绩。

Text Classification Improved by Integrating Bidirectional LSTM with Two-dimensional Max Pooling
主要内容:递归神经网络( RNN )是自然语言处理( NLP )任务中最常用的网络结构之一,因为它的递归结构非常适合处理不同长度的文本。RNN可以基于word的embedding,把整个句文本抽取成一个矩阵。这个矩阵包括两个维度:时间步长维度和特征向量维度。现有的大多数模型通常只在时间步长维度上通过一维( 1D )max-pooling操作或基于注意力的操作来把整个整个句子转换成一个固定长度的向量。但这就存在一个问题:特征向量维上的特征向量之间并不是相互独立的,简单地在时间步长维度上单独应用1D的max-pooling可能破坏特征表示的结构。相反,在二维上应用二维( 2D )pooling操作可以获得更多对序列建模任更有意义的特征。为了整合矩阵的两个维度上的特征,本文提出使用2D max-pooling操作来获得文本的固定长度表示。本文还利用二维卷积对矩阵中更有意义的信息进行了采样。对情感分析、问题分类、主观性分类和新闻组分类6个文本分类任务进行了实验。与现有模型相比,所提出的模型在6个任务中的4个任务上取得了最优的结果。
![]()
Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
主要内容:关系分类是自然语言处理领域的一项重要语义处理任务。但存在两个问题:1、即使是最先进的系统仍然需要依赖一些lexical resources(如WordNet )或NLP系统(如依赖与句法分析和命名实体识别)来获得高级特征。2、重要信息会出现在句子的任何位置。针对这些问题,本文提出了基于注意力机制的双向长短期记忆网络( Att-BLSTM )来捕捉句子中最重要的语义信息。在SemEval - 2010关系分类任务上的进行试验,结果证明该方法优于现有的大多数方法。

Recurrent Convolutional Neural Networks for Text Classification
主要内容:文本分类是许多NLP应用中的基础任务。传统的文本分类器往往依赖于许多人为设计的特征,如字典、知识库和特殊的树结构。与传统的文本分类方法相比,本文将卷积神经网络和循环神经网络相结合,提出了一种无需人为feature的递归卷积神经网络。在模型结构中中,采用一种递归结构来尽可能地捕获上下文信息,学习word的表示,这与传统的基于窗口的神经网络相比,引入更少的噪声。还采用了一个max - pooling层,自动判断哪些词在文本分类中起着关键作用,以捕获文本中的关键信息。在四个常用数据集上进行了实验,实验结果表明,在多个数据集上,特别是在文档级数据集上,该方法的性能优于现有的方法。

论文及源码下载地址
源码下载地址:
https://github.com/lbda1/text-classification(基于text cnn,并在cnn之前加lstm或者双向的lstm)
https://github.com/lbda1/text-classification-models-tf
论文下载地址:
链接: https://pan.baidu.com/s/1mB0YzlWiU2m0ryu3zWAUyQ
密码: 4xh7