机器学习算法——集成方法(Ensemble)之Stacking
本文是基于《kaggle比赛集成指南》来进行总结的概述什么是集成学习,以及目前较为常用的技术。这里主讲的集成学习技术用于分类任务,关于回归和预测这块不太了解,读者可自行查询相应博客或者论文。
1 什么是模型的集成?
集成方法是指由多个弱分类器模型组成的整体模型,我们需要研究的是:
- ① 弱分类器模型的形式
- ② 这些弱分类器是如何组合为一个强分类器
学习过机器学习相关基础的童鞋应该知道,集成学习有两大类——以Adaboost为代表的Boosting和以RandomForest为代表的Bagging。它们在集成学习中属于同源集成(homogenous ensembles)方法;而今天我将主要对一种目前在kaggle比赛中应用的较为广泛的集成方法——Stacked Generalization (SG),也叫堆栈泛化的方法(属于异源集成(heterogenous ensembles)的典型代表)进行介绍。

如上图,弱分类器是灰色的,其组合预测是红色的。图中展示的是温度——臭氧的相关关系。
2 堆栈泛化(Stacked Generalization)的概念
作为一个在kaggle比赛中高分选手常用的技术,SG在部分情况下,甚至可以让错误率相比当前最好的方法进一步降低30%之多。
以下图为例,简单介绍一个什么是SG:
- ① 将训练集分为3部分,分别用于让3个基分类器(Base-leaner)进行学习和拟合
- ② 将3个基分类器预测得到的结果作为下一层分类器(Meta-learner)的输入
- ③ 将下一层分类器得到的结果作为最终的预测结果
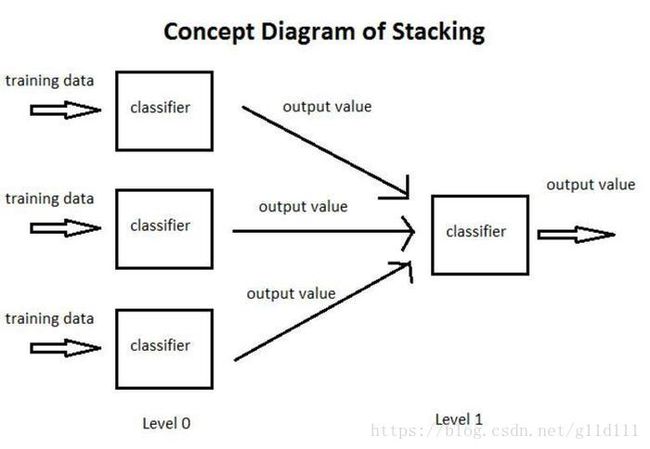
这个模型的特点就是通过使用第一阶段(level 0)的预测作为下一层预测的特征,比起相互独立的预测模型能够有更强的非线性表述能力,降低泛化误差。它的目标是同时降低机器学习模型的Bias-Variance。
总而言之,堆栈泛化就是集成学习(Ensemble learning)中Aggregation方法进一步泛化的结果, 是通过Meta-Learner来取代Bagging和Boosting的Voting/Averaging来综合降低Bias和Variance的方法。 譬如: Voting可以通过kNN来实现, weighted voting可以通过softmax(Logistic Regression), 而Averaging可以通过线性回归来实现。
3 一个小例子
上面提到了同源集成经典方法中的Voting和Averaging,这里以分类任务为例,对Voting进行说明,那么什么是Voting呢?
Voting,顾名思义,就是投票的意思,假设我们的测试集有10个样本,正确的情况应该都是1:
我们有3个正确率为70%的二分类器记为A,B,C。你可以将这些分类器视为伪随机数产生器,即以70%的概率产生”1”,30%的概率产生”0”。
下面我们可以根据从众原理(少数服从多数),来解释采用集成学习的方法是如何让正确率从70%提高到将近79%的。
All three are correct
0.7 * 0.7 * 0.7
= 0.3429
Two are correct
0.7 * 0.7 * 0.3
+ 0.7 * 0.3 * 0.7
+ 0.3 * 0.7 * 0.7
= 0.4409
Two are wrong
0.3 * 0.3 * 0.7
+ 0.3 * 0.7 * 0.3
+ 0.7 * 0.3 * 0.3
= 0.189
All three are wrong
0.3 * 0.3 * 0.3
= 0.027我们看到,除了都预测为正的34,29%外,还有44.09%的概率(2正1负,根据上面的原则,认为结果为正)认为结果为正。大部分投票集成会使最终的准确率变成78%左右(0.3429 + 0.4409 = 0.7838)。
注意,这里面的每个基分类器的权值都认为是一样的。
4 堆栈泛化的发展
下面内容摘自 史春奇 https://www.jianshu.com/p/46ccf40222d6
最早重视并提出Stacking技术的是David H. Wolpert,他在1992年发表的论文Stacked Generalization
它可以看做是交叉验证(cross-validation)的复杂版, 通过胜者全得(winner-takes-all)的方式来进行集成的方法。
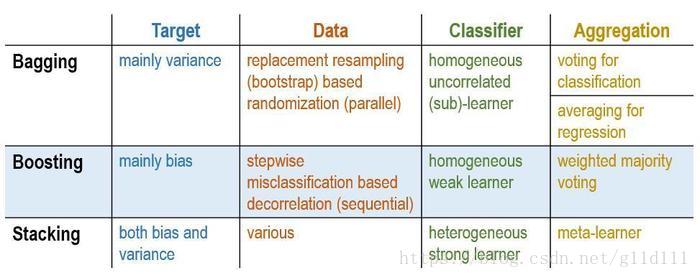
上图是Stacking和Boosting及Bagging在目标,数据,分类器和集成方式的差别。其实, Stacking具有的灵活和不确定性,使得它既可以来实现Bagging方式, 又可以来实现Boosting方式。
理论方面,SG被Wolpert在1992年提出后,Leo Breiman在1996年把广义线性模型(Generalized Linear Model)和SG方法结合起来提出了 “Stacked Regressions”。 再之后,来自加州伯克利分销(UC Berkeley)的Mark J. van der Laan在2007的时候在表述Super Learner的时候, 从理论上证明了Stacking方法的有效性。
实践方面, 除了SG理论本身的突破之外, SG应用的广度和深度也在不停的突破, 其中一个是训练数据的分配(Blending的出现); 而另外一个是深层(3层以上)Stacking的出现。目前,可以通过在python中使用mlxtend库来完成Stacking。
5 常见的Meta-Learner选取
本节内容全部摘录自今我来思,堆栈泛化(Stacked Generalization)
统计方法的Meta-Learner:
Voting ( Majority based, Probabilitybased)
Averaging (Weighted, Ranked)
经典容易解释的机器学习算法:
Logistic Regression (LR)
Decision Tree (C4.5)
非线性(non-linear)机器学习算法:
Gradient Boosting Machine (GBM,XGBoost),
Nearest Neighbor (NN),
k-Nearest Neighbors (k-NN),
Random Forest (RF)
Extremely Randomized Trees (ERT).
加权一次/二次线性(Weighted Linear / Quadratic)模型
Feature weighted linear stacking
Quadratic - Linearstacking
Multiple response 分析(非线性)框架
Multi-response linear regression (MLR)
Multi-response model trees (MRMT)
其他, 在线学习, 神经网络,遗传学习, 群体智能
6.1 在线学习 Online stacking (OS)
Linear perceptron with online random tree Random bit regression (RBR) Vowpal Wabbit (VW) Follow the Regularized Leader (FTRL)6.2 神经网络Artificial neural network (ANN)
2 layer - ANN 3 layer - ANN6.3 遗传学习 Genetic algorithm (GA)
GA-Stacking6.4 群体智能 Swarm intelligence (SI)
Artificial bee colony algorithm
另外, 这有个文章列表显示从1997年到2013年, Meta-learner的设置越来越新颖广泛:

综上, SG是很强大的集成方式, 某种意义上, 和深度学习类似, 纵向增加了学习深度, 但是也增加了模型复杂型和不可解释性。如何精心的选择Meta-learner 和 Base-learner, 训练方式, 评价标准等也是要重视的经验。
参考资料
- 今我来思,堆栈泛化(Stacked Generalization)
- kaggle比赛集成指南
- Stacked_Generalization
- KAGGLE ENSEMBLING GUIDE