一个验证码破解的完整演示
这篇博客主要讲如何去破解一个验证码,for demo我会使用一个完整的工程来做,从原始图片到最终的识别结果,但是破解大部分的验证码其实是个很费力的活,对技术要求反而不是特别高,为什么这么说呢? 主要原因有以下几点:
- 你需要验证码的正确答案作为监督,所以基本是人来识别然后写答案
- CNN之类的DL方法对验证码这种简单的图像识别能力非常高
所以,破解的话你需要有耐心
破解流程
破解验证码其实最终归类为classification问题,毫无疑问需要NN(neural network),还有图像学(digital image)的知识
所以破解的流程大概是这样的:
- 预处理(preprocess)
- 分割字符(split)
- 识别单个字符(classification)
预处理主要用到的是图形学的相关知识,比如:
- 二值化
- CFS
- 连通域
之类的
分割字符这里就比较麻烦了,要视具体情况而定,比如下面这两种:

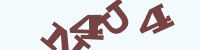
对于第一种,很明显的是可以直接分割,因为根本不粘连啊,但是对于第二种你恐怕要动点心思了
识别单个字符,这个可能是最没有技术含量的,现在大量的cnn使用,识别简单的验证码字符完全不是问题,比如caffe+mnist就完全可以,当然最后的识别效果取决与你之前做的样本的好坏
preprocess
首先说下我这次演示的需要破解的验证码,如下所示:



主要有上面的三种样子,我们对其观察可以知道以下事实:
(1) 大部分字符是不粘连的
(2) 字体的变化的样式基本就三种,不是很多
所以,针对验证码的特点,我的具体的破解的流程是这样的:
- CFS获得图像块
- NN的方法获得图像块中字符的个数
- 平均分割图像块获得单个字符
- 识别单个字符获得答案
可能有人会问,为何要使用NN的方法获得图像块中字符的个数? 直观上来说,包含三个字符的图像块比包含两个字符的图像块肯定要宽啊!
这个我在使用CFS获得图像块之后进行了统计,发现使用宽度来判定会产生大面积的误判,因为有的三个字符黏在一起其宽度反而比两个的要小,所以就使用NN啦
二值化
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
#180作为阈值
retval__, binary_im = cv2.threshold(img, 180, 1, cv2.THRESH_BINARY) 顶格
for x in xrange(0, binary_im.shape[0]):
line_val = binary_im[x]
# 不全部是白色(1)
if not (line_val == 1).all():
line_start = x
break
for x1 in xrange(binary_im.shape[0]-1, -1, -1):
line_val = binary_im[x1]
# 不全部是白色(1)
if not (line_val == 01).all():
line_end = x1
break
for y in xrange(0, binary_im.shape[1]):
col_val = binary_im[:, y]
# 不全部是白色(1)
if not (col_val == 1).all():
col_start = y
break
for y1 in xrange(binary_im.shape[1]-1, -1, -1):
col_val = binary_im[:, y1]
# 不全部是白色(1)
if not (col_val == 1).all():
col_end = y1
break
ding_ge_im = binary_im[line_start:line_end, col_start:col_end]CFS
from skimage.measure import regionprops
from skimage.morphology import label
im_bw = binary_img(img_path)
# CFS
label_image, num_of_region = label(im_bw, neighbors=8, return_num=True)CFS之后的处理
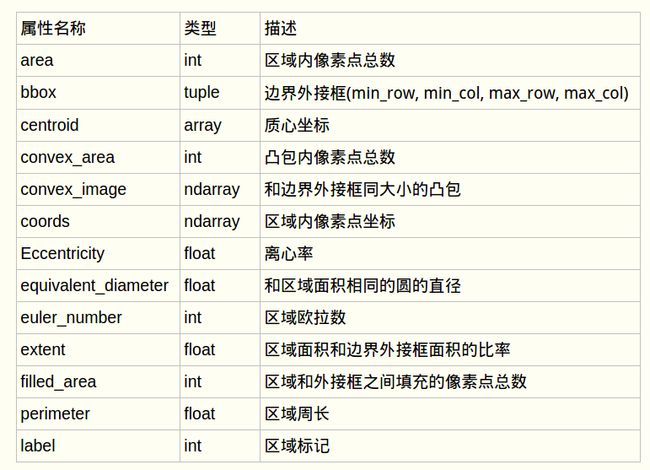
对于CFS之后的图像(label_image),我们还需要进行处理,比如被包含的就不要了,质心之间靠的太近的可以合并,这里列出我们可以由label_image获得的相关信息(比如坐标,质心等):
对于我们的验证码,我采用的是三个策略:
- 被包含的区域忽略
- 像素少于30的区域忽略
- 宽高等于图片的宽高的区域之间取交集
for region in regionprops(label_image):
# 跳过包含像素过少的区域
if region.area < 30:
continue
minr, minc, maxr, maxc = region.bbox
# coord_r, coord_c = region.centroid
coordinates_of_all_region[index] = np.array([minr, minc, maxr, maxc])
# centroid_of_all_region[index] = np.array([coord_r, coord_c])
pixels_of_all_region[index] = region.area
index += 1
# 判断X代表的区域是否被包含
for y in xrange(0, coordinates_of_all_region.shape[0]):
if (coordinates_of_all_region[y] == 0).all() or (y == x):
continue
minr_, minc_, maxr_, maxc_ = coordinates_of_all_region[y]
if minr >= minr_ and maxr <= maxr_ and minc >= minc_ and maxc <= maxc_:
coordinates_of_all_region[x] = np.zeros((1, 4)) - 1 # 被包含的区域矩形坐标置为-1
# centroid_of_all_region[x] = np.zeros((1, 2)) - 1 # 被包含的区域的质心坐标置为-1
pixels_of_all_region[x] = -1 # 被包含的区域的像素数目置为-1
break
# 有部分的图像存在定位重合的现象(宽度为高度50),进行合并
all_done = False
for x in xrange(0, coordinates_of_all_region.shape[0]):
if not all_done:
for y in xrange(0, coordinates_of_all_region.shape[0]):
if y == x:
continue
if (coordinates_of_all_region[x][0] == coordinates_of_all_region[y][0] == 0) and (coordinates_of_all_region[x][2] == coordinates_of_all_region[y][2] == 50):
# minrow_x = minrow_y and maxrow_x = maxrow_y
# 合并两个区域
min_r_2 = coordinates_of_all_region[x][0]
min_c_2 = min(coordinates_of_all_region[x][1], coordinates_of_all_region[y][1])
max_r_2 = coordinates_of_all_region[x][2]
max_c_2 = min(coordinates_of_all_region[x][3], coordinates_of_all_region[y][3])
coordinates_of_all_region[x] = np.array([-1, -1, -1, -1])
coordinates_of_all_region[y] = np.array([min_r_2, min_c_2, max_r_2, max_c_2])
all_done = True
break预测CFS块包含的字符数
这里我使用的是Keras,具体的安装方法可以看下我的关于Keras的博客ubuntu下安装Keras
典型的长度是这样的:
- 单个字符: 23 pixel
- 两个字符: 59 pixel
- 三个字符: 105 pixel
- 四个字符: 140 pixel
- 宽度超过145 pixel认为是4个字符
识别长度的过程是判断某个CFS块的宽度距离上述典型长度的和,找出最小值,比如某个宽度是65,则:
sum1 = (65-23) + (65-59) = 43
sum2 = (65-59) + (105-65) = 41
sum3 = (105-65) + (140-65) = 115
最小值是41,距离59和65比较近,则猜测为2或者3个字符
分别训练三个model,用来判断长度,如下:
model 1
model = Sequential()
model.add(Convolution2D(4, 5, 5, input_shape=(1, 30, 40), border_mode='valid'))
model.add(Activation('tanh'))
model.add(Convolution2D(8, 5, 5, input_shape=(1, 26, 36), border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.55))
model.add(Convolution2D(16, 4, 4, input_shape=(1, 11, 16), border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.60))
model.add(Flatten())
model.add(Dense(input_dim=16*4*6, output_dim=256, init='glorot_uniform'))
model.add(Activation('tanh'))
model.add(Dense(input_dim=256, output_dim=2, init='glorot_uniform'))
model.add(Activation('softmax'))model 2
model = Sequential()
model.add(Convolution2D(8, 5, 5, input_shape=(1, 40, 100), border_mode='valid'))
model.add(Activation('tanh'))
model.add(Convolution2D(8, 5, 5, input_shape=(1, 36, 96), border_mode='valid'))
model.add(Activation('tanh'))
model.add(Convolution2D(8, 5, 5, input_shape=(1, 32, 92), border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 3)))
model.add(Dropout(0.45))
model.add(Convolution2D(16, 4, 4, input_shape=(1, 14, 29), border_mode='valid'))
model.add(Activation('tanh'))
model.add(Convolution2D(16, 4, 4, input_shape=(1, 11, 26), border_mode='valid'))
model.add(Activation('tanh'))
model.add(Convolution2D(16, 4, 4, input_shape=(1, 8, 23), border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.55))
model.add(Flatten())
model.add(Dense(input_dim=16*2*10, output_dim=256, init='glorot_uniform'))
model.add(Activation('tanh'))
model.add(Dropout(0.65))
model.add(Dense(input_dim=256, output_dim=128, init='glorot_uniform'))
model.add(Activation('tanh'))
model.add(Dropout(0.40))
model.add(Dense(input_dim=128, output_dim=2, init='glorot_uniform'))
model.add(Activation('softmax'))model 3
model = Sequential()
model.add(Convolution2D(8, 5, 5, input_shape=(1, 55, 130), border_mode='valid'))
model.add(Activation('tanh'))
model.add(Convolution2D(8, 5, 5, input_shape=(1, 51, 126), border_mode='valid'))
model.add(Activation('tanh'))
model.add(Convolution2D(8, 5, 5, input_shape=(1, 47, 122), border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 3)))
model.add(Dropout(0.45))
model.add(Convolution2D(16, 4, 4, input_shape=(1, 21, 39), border_mode='valid'))
model.add(Activation('tanh'))
model.add(Convolution2D(16, 4, 4, input_shape=(1, 18, 36), border_mode='valid'))
model.add(Activation('tanh'))
model.add(Convolution2D(16, 4, 4, input_shape=(1, 15, 33), border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.55))
model.add(Flatten())
model.add(Dense(input_dim=16*6*15, output_dim=256, init='glorot_uniform'))
model.add(Activation('tanh'))
model.add(Dropout(0.60))
model.add(Dense(input_dim=256, output_dim=128, init='glorot_uniform'))
model.add(Activation('tanh'))
model.add(Dropout(0.40))
model.add(Dense(input_dim=128, output_dim=2, init='glorot_uniform'))
model.add(Activation('softmax'))获得字符个数之后就可以均分获得单个字符
单个字符识别
我之前也是训练了个cnn modelusing Keras,但是精度只有大概85%(48个类),后来改用Caffe+mnist精度到了89%,稍好
model 4
model = Sequential()
model.add(Convolution2D(8, 5, 5, input_shape=(1, 28, 28), border_mode='valid'))
model.add(Activation('tanh'))
model.add(Dropout(0.5))
model.add(Convolution2D(16, 3, 3, input_shape=(1, 24, 24), border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, 3, 3, input_shape=(1, 11, 11), border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(input_dim=32*4*4, output_dim=256, init='glorot_uniform'))
model.add(Activation('tanh'))
model.add(Dense(input_dim=256, output_dim=128, init='glorot_uniform'))
model.add(Activation('tanh'))
model.add(Dropout(0.4))
model.add(Dense(input_dim=128, output_dim=48, init='glorot_uniform'))
model.add(Activation('softmax'))Caffe版本的大家参考我的另外一篇博客Caffe使用自己的数据训练,很简单就可以搞定
总结
对于验证码的破解,主要的工作就是让验证码的所有字符分开,之后使用字符的单个识别就可以识别,过程中会用到图像处理的方法,cnn的方法等
上述的代码我已经打包好放在我的github上,验证码破解demo完整源码,大家下载下来,装好Keras和Caffe环境后,直接运行demo.py就可以得到识别结果,由于没时间优化的原因,识别率只有46%,但是相信作为demo还是可以的,有问题欢迎留言讨论!