CS231n Lecture 11:图像分割与检测(各种R-CNN, YOLO, SSD)
CS231n Lecture 11:图像分割与检测
图像的分割和检测的相关任务有不同的粒度,我们首先明确一下有关概念:
- 语义分割(Semantic Segmentation):将每个像素标注为某一类别,是一个分类问题。该任务不区分实例,即同一类别的不同实例都标为同一颜色(如下图中的两头牛);

- 单目标检测:只识别图像中的一个目标,并标出bounding box,此任务可以理解为分类+定位;

- 目标检测(Object Detection):识别图像中的所有目标,并分别标出bounding box;

- 实例分割(Instance Segmentation):识别图中所有目标,并标出它们的精确边界。

一、语义分割
滑动窗口?
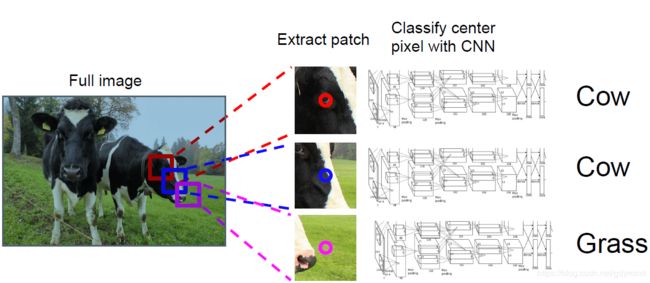
现在尝试实现语义分割。为了预测某个像素所属的类别,我们可以以这个像素为中心在原图中裁切出一个子图(Patch),并对这个子图进行图像分类(Classification)。我们使用滑动窗口依次对每个像素对应的patch进行分类,最终得到结果。
这样做理论上是可以的,但显然计算量太大,有许多冗余计算——patch间的重合部分的feature map是相同的。
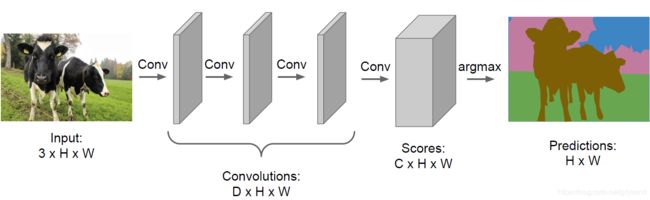
直接上CNN?
我们可以直接串联若干卷积层,输出C个[H x W]的feature map作为结果(C为类别数),第i个feature map代表各像素属于类别i的概率。但这需要需要人工标注大量的训练数据(给图片上的像素表类别),成本很高。除此之外,由于所有层产生的feature map与原图大小相同,当网络较深、输入图像分辨率较高是计算量和内存占用量都很大。
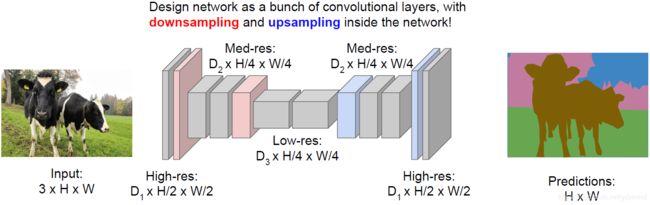
下采样+上采样
如前文所属保持feature map大小问题很大,所以我们可以先将feature map逐步缩小,然后再逐步变大。这样网络较深时中间部分的计算量也比较小。
有兴趣可以参考下面两篇paper:
- Fully Convolutional Networks for Semantic Segmentation, CVPR 2015
- Learning Deconvolution Network for Semantic Segmentation, ICCV 2015
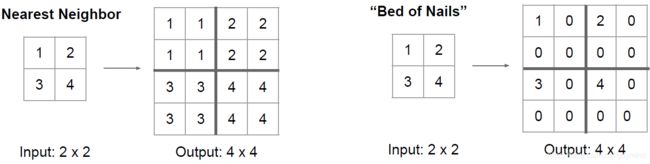
卷积操作很容易做到下采样,我们现在来讨论如何做上采样。
- 反池化(UnPooling):可以用池化的逆操作,通过复制值或 填充常数0等操作增加feature map大小(其中UnMaxPooling在MaxPooling的对应位置保留数字,其他位置填充零),见下图
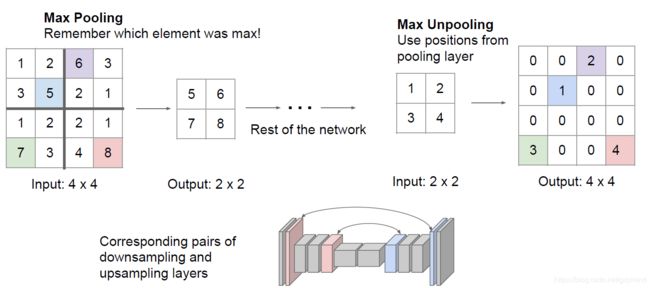
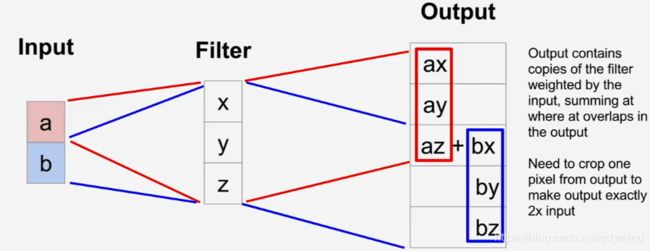
- 使用转置卷积(Transpose Convolution):分别将输入的feature map上的值与kernel的每个元素相乘,得到的矩阵作为输出,换言之,是分别将输入的feature map上的每个值作为kernel的权重。

若得到的结果有重叠(如上图的红色和蓝色有1x3的相交区域),则把相交部分的数值相加。
注意,这个操作也常被称为反卷积(DeConvolution),但实际上它并不是卷积的逆操作。
一维的转置卷积更好理解,如下图,输入[a b],kernel为[x y z],经过转置卷积的结果为[ax ay az+bx by bz]
二、单目标检测
我们可以将目标检测作为一个回归(Regression)任务。例如,将图片输入AlexNet,最后并行加上两个全连接层,分别进行分类和定位。其中,分类的输出是对每一类打分,这部分使用SoftMax Loss;而定位的输出为四个数字,分别代表bounding box的左上角横纵坐标和宽高,这部分使用L2 Loss。

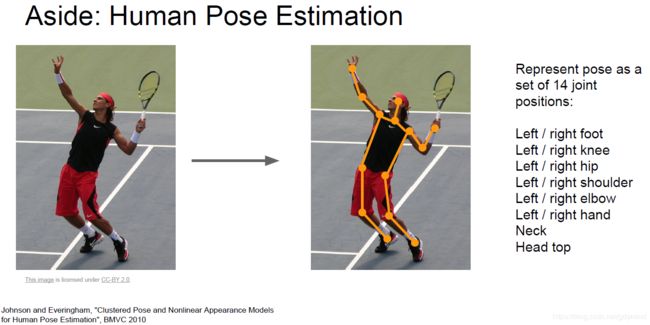
这种看做回归问题的方法也可以用于其他的一些问题(只要所需信息的个数固定,如bounding box需要四个数字)。比如下图中的识别人体姿态,我们只需预测14个关键点的位置:
三、目标检测
目标检测需要找出所有目标的bounding box并标出类别,由于图中目标数量未知,因此不能简单地处理为分类+定位问题。
我们可以考虑前面提到的先提取patch的方法。对于每个patch,我们对它进行分类,测试其是否属于某类目标,或者是否是背景(归为“背景类”代表此处没有目标)。这种方法首先要解决问题是怎样找合适的patch。
我们不可能穷举所有可能的patch。实际上,我们使用的**区域推荐(Region Proposal)**的方法:先找出可能包含目标的候选框,然后识别每个候选框中是否包含目标。
下面介绍目标检测网络的发展~
R-CNN
R-CNN中的Region Proposal方法叫做Selective Search(一种传统算法,非CNN),它会约产生2000个候选区域(Regions of Interest, ROI)。之后,每个候选区域的图像会规格化到统一的大小,并分别送入一个使用ConvNet,最后用SVM进行分类。
R-CNN还会输出四个数字对候选框进行修正,注意这个修正不仅可能使候选框变小,还可能让它变大(比如这个框框出了一个没有头的人,那么网络可能推断出上方会有个人头,因此上边界变大)。
R-CNN存在以下问题:
- 计算量大(处理2000个候选区域)
- 训练慢(84小时),占用空间多
- 训练完成后,运行速度也慢(使用VGG16时,每张图片要处理47s)
Fast-RCNN
我们不再分别将图像中的patch输入ConvNet,而是将整张图片输入ConvNet,得到一张整张图feature map,然后将RoI所对应的位置的feature map裁切出来。
同样的,如果我们使用全连接层做接下来的分类的话,裁切出来的feature map的patch必须规格化到固定的大小。这个操作使用RoI Pooling层实现的。

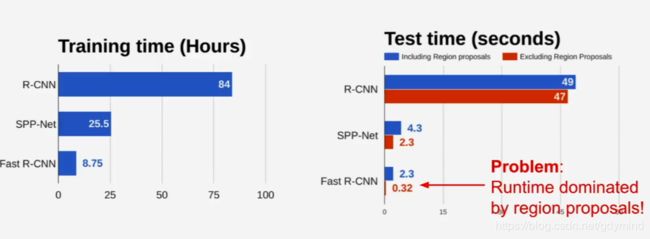
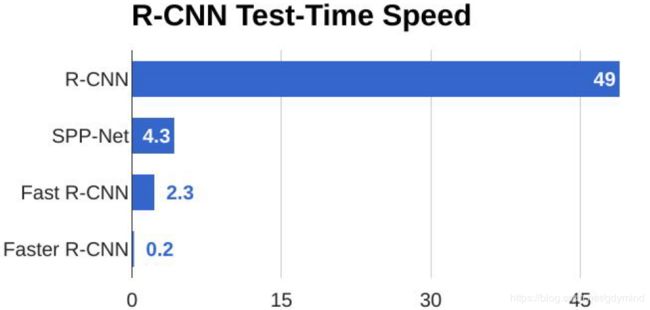
Faster R-CNN的的测试用时非常短,其中主要用时花在在Region Proposal上(见下图)。所以我们要想再加速就必须优化Region Proposal,而下面的Faster R-CNN就解决了这个问题。
Faster R-CNN
Faster R-CNN中的Region Proposal不再用传统算法做,而是使用称为Region Proposal Network (RPN)的网络来从feature中预测候选框,也就是说,现在的候选框也是学习出来的了。
整个网络设计如下图:图像经过一个CNN输出feature map,将该feature map输入RPN产生若干RoI,之后的处理方式和Fast R-CNN就相同了。
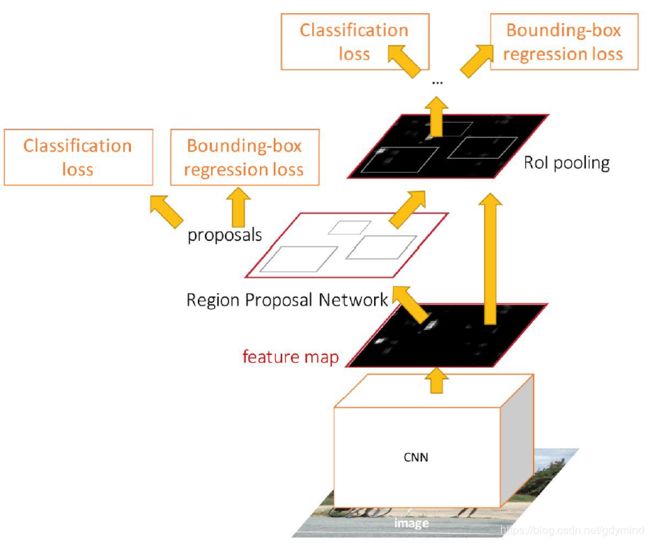
网络同样使用multi-task loss,共有下面四个loss:
- RPN 分类是否是目标的loss
- RPN回归候选框坐标的loss
- 对每个类别打分的loss
- 最终bounding box坐标的loss
注意到其中RPN的结果没有ground truth,那我们怎样评价一个候选框应不应该是候选框呢?Faster R-CNN中采取的方法是:如果一个候选框和某一个目标重合较大,它被认为是合适的候选框,反之不是。
使用RPN,Faster R-CNN的测试用时又大大缩短:
YOLO和SSD
R-CNN、Fast R-CNN和Faster R-CNN中的“R”代表区域(Region),它们都是基于区域候选的方法来做目标检测的(称作Region-based methods for object detection)。除了这样的方法,还有一些直接一个过程做完所有事情的网络,比较典型的有YOLO和SSD。
YOLO和SSD不再对每个候选框单独处理,而是将目标检测视为回归问题,使用某种CNN,将所有的预测框同时给出。
将整张图片划分为几个粗略的网格(Grid)(比如7x7的网格),在每个网格中存在固定数目(设这个数字为B)的base bounding box。
我们要预测的东西有:
- 真实框与base bounding box的差异
- 给出每个base bounding box的置信度,即包含目标的可能性
- 这个bounding box属于各类别的分数
综上,所以最终网络会输出7x7x(5B+C)个数字。其中C为类别数,每个7x7的网格中有B个base bounding box,每个base bounding box需要回归5个数字(4个表示修正坐标的数字和1个表示置信度的数字)。
四、实例分割
实例分割做的最好的网络是Mask R-CNN,它是上面方法的综合,对于每个RoI,它都再预测一个Binary Mask来像素级地刻画实例边界,网络设计如下:
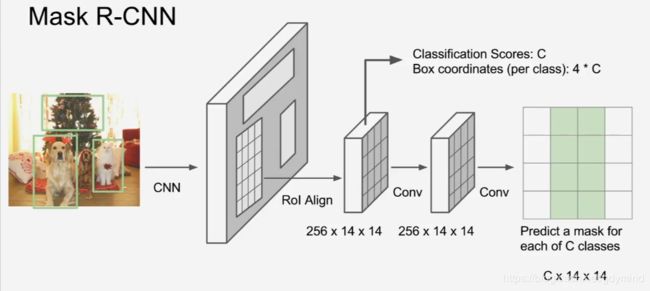
这个方法的结果非常好:

五、网络对比
以上网络都是用Microsoft COCO数据集进行训练的,其中大约有200,000张图片,80个类别,每张图平均有五六个实例。
这些网络需要调整的参数十分复杂,如使用什么网络(VGG16,、ResNet等)、使用什么检测框架(Faster R-CNN、R-FCN等),不同设置的精度和速度都有差异,CVPR 2017的中paper“Speed/accuracy trade-offs for modern convolutional object detectors”对这些不同的选择进行了详尽的比较。
