Selenium+Request+Beautifulsoup(周杰伦,林俊杰歌词爬取)
爬去JZ的歌词是为了做一个NlLP的任务,这里是在python上使用Selenuim+Requests+BeautifulSoup实现的。使用selenuim是因为会涉及到动态网页抓取,又使用Request的原因是selenium对网页抓取时是要先进行加载的因此很耗时间,而Request不需要网页加载。对网页解析既使用了selenium也是使用BeautifulSoup
爬取的网站是千千音乐
第一种方案:
千千音乐上面可以直接搜索:周杰伦 歌词,然后点击歌词,可以得到如下界面。每一页有二十首歌的g歌词,通过分析每一页的网址是规律可行变化的。:
第一页url:http://music.taihe.com/search/lrc?key=周杰伦 歌词&start=0&size=20&third_type=0
第二页url:http://music.taihe.com/search/lrc?key=周杰伦 歌词&start=20&size=20&third_type=0
第三页url:http://music.taihe.com/search/lrc?key=周杰伦 歌词&start=40&size=20&third_type=0


可以看见URL的变化就是start后面的数字0,20,40,…。那么这样问题就变得简单了。
优点:这个方案优点是可以直接Requests进行静态网页抓取,然后使用BeautifulSoup进行解析.
缺点:网页显示歌词数量776,但实际上可能有重复,有的可能是由于出现周杰伦名字就被搜索出来,因此有很多嘈杂数据.下面介绍另一种方案以及实现代码。
第二种方案
我们直接进入JZ的界面,如下所示,可以看见这里列举的全是JZ的歌曲,一共有26页,每页15首。但是每一页加载是js动态加载的,也就是不可以通过网页规律获取。

我们看一下上面这个页面的源代码(在“告白气球”,点击右键,选择查看元素),可以查看指定元素代码,如下图所示,可以看见“告白气球”歌名对应的标签是“”,其中包含有title也就是歌名,还有href包含有歌曲的ID。这里很重要的就是歌曲的ID,因为后面我们会通过ID变化来静态获取单个歌曲界面。
 在这个歌曲列表界面,需要点击下方的页码才能进入下一个歌曲列表界面,我们看一下其页码元素(也是单击右键,选择查看元素):
在这个歌曲列表界面,需要点击下方的页码才能进入下一个歌曲列表界面,我们看一下其页码元素(也是单击右键,选择查看元素):

可以看见每一个页码对应一个"” tag和一个事件event,这个就需要我们鼠标点击才能进入下页歌曲列表。因此获取歌曲ID时我们使用了selenium来进行动态获取。
我们再点击每一首歌,然后就会进入,该歌曲的界面,比如下面我们点击“告白气球”,就会进入如下界面:
 可以看见,这页有歌词显现,那么说明我们就可以通过分析单首歌的歌曲界面来获得其歌词。而这单首歌曲界面的url是有规律可循的我们来看一下:
可以看见,这页有歌词显现,那么说明我们就可以通过分析单首歌的歌曲界面来获得其歌词。而这单首歌曲界面的url是有规律可循的我们来看一下:
告白气球URL:http://music.taihe.com/song/266322598
夜曲的URL:http://music.taihe.com/song/1191265
可以看出单首歌曲的界面的URL就是:“http://music.taihe.com/song/”+ID。
我们来分析一下该页面歌词块的源码元素(鼠标放在歌词处,单击右键),出现如下源码:

可以看见,“告白气球”的歌词也是动态加载的,并没有实际歌词出现在该处,那么我们可以看见歌词处对应个tag “div”包含歌词的数据链接data-lrclink,我们点击这个链接,可以直接获取该歌词的lrc文件.
这里我们就可以写出第二种方案的路径:
1.通过selenium动态获取歌词ID
2.通过requests静态获取单首歌界面
3.通过BeautifulSoup获取歌词链接
4.在通过requests获取歌词
代码
获取歌词ID:
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import csv
import requests
##为什么用S+R+B,因为页面是动态,先用selenium动态获取信息,用BeautifulSoup来解析.最后下载使用Requests,这是因为Selenium需要加载页面,而requests不需要
driver=webdriver.Firefox()
url_init="http://music.taihe.com/artist/7994?pst=sug"
driver.get(url_init)
page_list=list(range(2,27))
file=open("ID_Name1.csv","w")
writer=csv.writer(file)
def B_get_song_id(page,text):
soup=BeautifulSoup(text,"html.parser")
print("page:",page)
if page==0:
songs = soup.find_all("a", "songlist-songname")
else:
songs=soup.find_all("a","namelink gray")
song=[]
for a in songs:
song_inf={}
song_inf["name"]=a["title"]
song_inf["id"]=a["href"].split("/")[-1]
song.append(song_inf)
print(song)
return song
def S_get_page(driver):
songs=[]
data=B_get_song_id(0,driver.page_source)
songs.extend(data)
for page_num in page_list:
a_list=driver.find_elements_by_css_selector("a.page-navigator-number")
for a in a_list:
if int(a.text)==page_num:
page=int(a.text)
a.click()
time.sleep(10)#加载时间,保证加载完成
data=B_get_song_id(page,driver.page_source)
songs.extend(data)
break
return songs
data=S_get_page(driver)
for song in data:
writer.writerow(song.values())
file.close()
driver.close()
获取歌词:
import pandas as pd
def R_get_text(url):
try:
print("url:",url)
Response=requests.get(url)
Response.raise_for_status()
Response.encoding=Response.apparent_encoding
return Response.text
except:
print("出现错误再Try一次")#这里再try一次是因为,我网速不稳定
try:
print("url:", url)
Response = requests.get(url)
Response.raise_for_status()
Response.encoding = Response.apparent_encoding
return Response.text
except:
print("出现错误")
print("错误地点:", url)
return None
def B_get_lrc_link(text):
soup=BeautifulSoup(text,"html.parser")
lrcbox=soup.find("div","lrc-list")
if lrcbox:
return lrcbox["data-lrclink"]
def get_lrc_link_list(data,url):
lrc_links=[]
for ip in data["IP"]:
id_link={}
text=R_get_text(url+str(ip))
time.sleep(3)#sleep一方面是为了让网页有充足时间加载(主要还是自己网速不稳定),另一方面避免请求过于频繁,对服务器造成负担
if text:
id_link["Link"]=B_get_lrc_link(text)
id_link["IP"]=str(ip)
lrc_links.append(id_link)
return lrc_links
def get_lrc(linklist,path):
for ip_link in linklist:
with open(path+ip_link["IP"]+".txt","w") as f:
lrc=R_get_text(ip_link["Link"])
if lrc:
f.write(lrc)
def main():
data = pd.read_csv("ID_Name1.csv", names=["Name", "IP"])
url = "http://music.taihe.com/song/"
save_path = "LyrcFile/"
lrc_links=get_lrc_link_list(data,url)
get_lrc(lrc_links,save_path)
main()
事实上任意歌手的歌词都可以通过此代码抓取,只需更换url_init
最后获得的歌词列表如下:
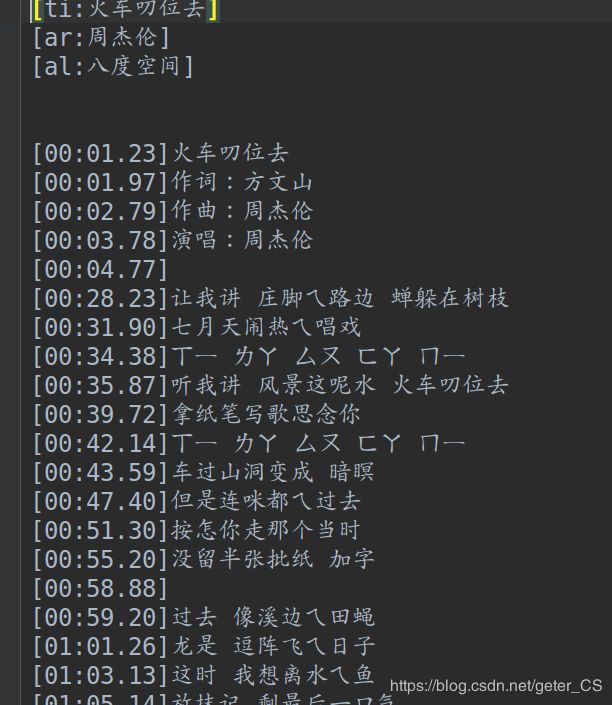
比如204421.txt打开是这样的:
简单词云分析
根据上面爬去的歌词文件,我们这里使用jieba做分词,然后统计词频,做一个简单的词云分析:
from collections import Counter
import jieba
import os
from wordcloud import WordCloud
import numpy as np
import matplotlib.pyplot as pl
def chulitext(lrc):
lrc_pure=[]
if "演唱:周杰伦" in lrc:
lrc=lrc.split("\n")
start = 0
for sentence in lrc:
if start==1:
sentence=sentence.split("]")
if (len(sentence)>=2) and (len(sentence[-1])>=2):
lrc_pure.append(sentence[-1])
if "演唱:周杰伦" in sentence:
start=1
return lrc_pure
def get_pure_lrc(path):
data=[]
for ip in os.listdir(path):
file=path+ip
ip=ip.split(".")[0]
with open(file,"r") as f:
song={}
lrc_pure=chulitext(f.read())
if len(lrc_pure)>0:
song["IP"]=ip
song["Lrc"]=lrc_pure
data.append(song)
return data
def get_lrc_ci(lrc):
ci=[]
for sentence in lrc["Lrc"]:
sentence=list(jieba.cut(sentence))
sentence_del_stop=[]
for word in sentence:
if len(word)>1:
sentence_del_stop.append(word)
ci.extend(sentence_del_stop)
return ci
def get_all_ci(data):
all_ci=[]
for lrc in data:
lrc_ci=get_lrc_ci(lrc)
all_ci.extend(lrc_ci)
return all_ci
def generate_ciyun(cipin):
cipin_dict={}
for ci in cipin:
if ci[0] not in ["活活","四步","两步","这样","一个"]:
cipin_dict[ci[0]]=ci[1]
wc = WordCloud(
font_path='msyh.ttf',
max_words=100,
background_color='white',
width=600,
height=400
)
wc.generate_from_frequencies(cipin_dict)
wc.to_file('JZ.png')
def zhuzhangtu(cipin):
y=[]
x_name=[]
for ci in cipin:
if ci[0] not in ["活活","四步","两步","这样","一个"]:
y.append(ci[1])
x_name.append(ci[0])
if len(y)>=10:
break
x=np.arange(len(y))
pl.figure(1)
pl.bar(x,y,facecolor = 'red', edgecolor = 'white')
pl.xticks(x,x_name,fontproperties="SimHei")
pl.show()
path="LyrcFile/"
data=get_pure_lrc(path)
all_ci=get_all_ci(data)
generate_ciyun(Counter(all_ci).most_common())
zhuzhangtu(Counter(all_ci).most_common())
输出结果:

柱状图显示词频最高的前十个词:

下面是使用代码爬取林俊杰歌词做的分析结果:

