YOLO系列论文笔记--YOLOv1
YOLOv1
优点
--预测为false positives的样例比较少,主要表现在YOLO是对整张图片进行处理,能够索取整体图片的上下文信息,不像滑动窗口和基于区域建议技术(如Fast R-CNN),它是以图像块为单位,用以对目标进行识别;
--YOLO比DPM和R-CNN等顶级检测方法更具优势,在实验上表现在利用自然图像训练并在艺术品测试,其检测性能更优,究其本质,是由于YOLO学习目标特征的普遍化;
缺点
--其准确率落后于最新的检测系统;YOLO能够很快识别图像中的物体,但是很难精确的定位,尤其是小物体;(a原因?)
速度
--YOLO:45 frames per second(fps)(在没有批处理,硬件环境:Titan X GPU);意味着处理视频流的实时性少于25毫秒的延迟;
--Fast YOLO(tiny YOLO):155fps;与其他实时监测系统相比,该模型的mAP是其他系统的两倍;
检测流程(建模)
--模型流程(详细的建模步骤和后面的网络模型并没有严格的匹配,可以认为网络也可以按照这个流程完成目标的检测):

--将输入图片分割成S*S的网格
--每个网格预测B个bounding boxes(bounding boxes包括置信度分数confidence和其坐标或者偏置(x,y,w,h),(x,y)为中心坐标,w为该box的宽,h为高,confidence表示预测的box与任意真实box的IOU;
confidence=![]()
--每个网格还会预测C个条件概率,表示该网格包含目标的概率;
--由以上可知,类出现在盒子的概率与预测的目标框适合真实目标的程度为:
![]()
--根据以上流程,如下的网络只需预测一个S*S*(B*(4+1)+C)的向量,该向量用于最终回归框的生成,以及训练时损失的计算;
网络框架
--网络模型受GoogleLeNet启发;包含24个卷积层和2个全连接层;Fast YOLO使用9个卷积层;

训练
--预训练模型:利用如上网络框架的前20个卷积层+1平均池化层+1全连接层组成分类框架和ImageNet 1000-class比赛数据集训练大约一周的时间,并且在ImageNet2012验证集上single crop top-5准确率达到88%;其训练集图片设计为224*224(因为后期用于检测时需要细粒度视觉信息),YOLO网络训练集图片大小的一半;
--YOLO的网络框架是预训练模型框架后添加4个卷积层和2个全连接层,在训练时随机初始化;(实验发现,在预训练模型后添加卷积层和全连接层能够提高性能。)
--最终层激活函数为linear(y=x);其他所有层激活函数为leaky;
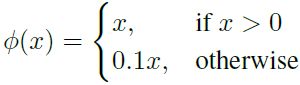
--预测输出:class probabilities和BBs坐标((x,y)为中心坐标的偏置,处于0-1;w,h为BBs的宽和高,利用图像的宽和高正则化为0-1之间);
--损失优化时,(1)由于每张图片中的许多网格中不包含目标,使得其计算的置信度分数趋于0,如果误差和中各种误差的权重相等,则会导致模型的不稳定性以及在训练过程中提前出现分歧;其处理方法为使包含目标的网格拥有大的梯度,也就是说,其误差在误差和中有一个大的比重;所以在最终损失中,包含目标的boundingbox的损失权重设置为5,不包含的设置为0.5;(2)为了解决小boundingbox的小偏差比大BBs的重要,模型预测BBs的宽和高的平方根(由于预测的宽和高处于0到1之间,平方根属于比宽和高大的值,在计算损失时,就缓和了小BBs对小偏差的敏感程度)已达到目的;
--损失函数:

--特此说明,对为什么这样计算损失的理解:每个网格期望有一个最优目标框(具有该网格预测的目标框与真实目标框的最大IOU值)。在计算损失时,认为该网格预测的置信度分数和该网格预测目标框与真实目标框的最大IOU值有关。置信度的损失是利用每个Cell的最优目标框与ground truth的IOU作为监督信息计算(IOU为0时,就证明无目标,就会计算无目标对象的置信度损失);当Cell在ground truth内时,计算当前cell的分类损失;坐标损失只计算最优目标框的,包括中心坐标和该框的宽和高的平方根的损失;
--数据集:PASCAL VOC 2007和2012的训练集和验证集上训练;VOC2007的测试集上测试;
--训练参数:135 epochs;momentum 0.9;decay 0.0005;学习率:前75epochs:开始时为10^-3,然后慢慢的变为10^-2,开始时的高学习率会因为模型的不稳定使得模型分歧;接下来的30epochs为10^-3;最后的30epochs为10^-4;
--知识点积累:(1)epoch代表过完一次所有的训练数据;(2)momentum,动量来源于牛顿定律,基本思想是为了找到最优加入“惯性”的影响,当误差曲面中存在平坦区域,SGD就可以更快的学习;(3)decay,上述decay指的是权值训练过程中,正则化权值的衰减系数(参照机器学习的正则化L1、L2);
![]() 动量的公式
动量的公式
--防止过拟合采取的措施:(1)dropout,0.5;(2)扩展数据集:对随机缩放和翻转的比例是原始图片大小的20%,并随机调整图片的曝光度和饱和度,调节因子为1.5;
模型分析分析
--网格(grid cell)设计boundingbox的预测中增加了其空间的多样性,无论训练以何种方式计算损失,但在预测时,它能够把大的目标或者网格中有相邻边界的目标在多个网格中进行多次预测,使得这些目标能够被很好的预测;非极大值抑制的方法使mAP增加了1-2个百分点;
--YOLO的局限性:(1)强加在boundingbox上空间约束(每个网格只能预测两个boxes和一个类)限制了模型预测相邻目标的box的数量;模型不能够很好的预测成群出现的小目标;(2)模型所能预测的box的比例和大小有限(所能预测的比例和大小只能是训练数据中出现的);预测box的特征比较粗糙(训练经历了多次下采样);(3)损失函数的近似性(处理小box和大box的误差的方法相同,没有充分考虑到小误差对于小box的IOU比大box的大,使得主要错误来源于定位错误);
与其他检测系统的比较
--DPM(Deformable parts models):建立图片金子塔,计算每层的31维特征图谱,运用训练好的模型(rootfilter和part filter)进行卷积,然后累加,最终达到检测的目的;
DPM详情:https://blog.csdn.net/sysu_yuhaibao/article/details/76599926?fps=1&locationNum=6
区别:DPM使用分离步骤提取静态特征、分类区域并且对高分区域预测boundingbox;而YOLO利用统一的网络实现特征提取、边界框预测、非最大值抑制和上下文推理。由于YOLO优化的动态性,使得该框架比DPM模型具更快更准确;
--RCNN:流程:Selective Search生成潜在的boundingboxes——卷积神经网络提取特征——SVM判别是目标的分数并且用线性模型调整boundingbox的位置——非最大值回归淘汰重复的boxes;由于每个过程需独立调整进行精确调整,使得非常耗时(测试一张图片40ms以上);
区别:两者具有相似之处,都使用卷积特征预测出潜在的box以及这些box的分数;YOLO的grid cell方法具有空间局限性,减轻了同一目标的多次检测,并且YOLO将多个单一的部分组合成单一流程,最终能够联合优化;
--其它Fast检测器(Fast R-CNN和Faster R-CNN):Fast 和Fater总体来说是通过共享计算能力和利用卷积神经网络代替SS方法提高R-CNN的速度,尽管如此(速度和准确率普遍提高),其仍不能达到实时性能;
--总结性知识:很多研究都集中在加速DPM通道(加速HOG计算、使用级联和使用GPU加速),最终,30HZ DPM达到实时性要求;而YOLO提出了一种全新的思路;很多检测器利用更少的变化在单一类上进行优化,而YOLO属于通用目标检测;
--DeepMultiBox:定位+识别;MultiBox不能执行通用目标检测,它仍然是一个大的通道;两者都使用卷积神经网络预测boundingbox,但Yolo是整体检测流程;
--OverFeat:分类+定位;训练一个卷积神经网络来执行定位和调整定位器来执行检测;非连贯性系统;
--MultiGrasp:预测一个可能包含的目标的抓取区域,不需要估计大小、位置、目标的边界和类;
实验
--与其它检测系统的比较:

--在VOC2007上的错误分析:Correct: correct class and IOU > 0.5; Localization: correct class, 0.1 < IOU <0.5; Similar: class is similar, IOU > 0.1;Other: class is wrong, IOU > 0.1; Background: IOU <0.1 for any object;

--Fast R-CNN与YOLO的联合使用

由于YOLO与Fast R-CNN在测试时出现不同类型的错误,所以联合起来才能更有效的提升Fast R-CNN的检测性能;
--在VOC2012上的结果


