简单易学的深度学习算法——Wide & Deep Learning
这篇文章是阅读《Wide & Deep Learning for Recommender Systems》后的总结,该文章中提出结合Wide模型和Deep模型的组合方法,对于提升推荐系统(Recommendation System)的性能有很重要的作用。
1、背景
本文提出Wide & Deep模型,旨在使得训练得到的模型能够同时获得记忆(memorization)和泛化(generalization)能力:
- 记忆(memorization)即从历史数据中发现item或者特征之间的相关性。
- 泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。
在推荐系统中,记忆体现的准确性,而泛化体现的是新颖性。
在本文中,利用Wide & Deep模型,使得训练出来的模型能够同时拥有上述的两种特性。
2、Wide & Deep模型
2.1、Wide & Deep模型结构
Wide & Deep模型的结构如下图所示:
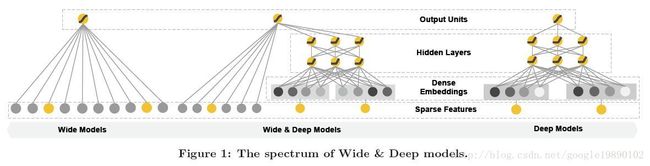
在Wide & Deep模型中包括两个部分,分别为Wide部分和Deep部分,Wide部分如上图中的左图所示,Deep部分如上图中的右图所示。
2.2、Wide模型
Wide模型如上图中的左侧的图所示,实际上,Wide模型就是一个广义线性模型:
其中,特征 x=[x1,x2,⋯,xd] x = [ x 1 , x 2 , ⋯ , x d ] 是一个 d d 维的向量, w=[w1,w2,⋯,wd] w = [ w 1 , w 2 , ⋯ , w d ] 为模型的参数。最终在 y y 的基础上增加Sigmoid函数作为最终的输出。
2.3、Deep模型
Deep模型如上图中的右侧的图所示,实际上,Deep模型是一个前馈神经网络。深度神经网络模型通常需要的输入是连续的稠密特征,对于稀疏,高维的类别特征,通常首先将其转换为低维的向量,这个过程也成为embedding。
在训练的时候,首先随机初始化embedding向量,并在模型的训练过程中逐渐修改该向量的值,即将向量作为参数参与模型的训练。
隐含层的计算方法为:
其中, f f 称为激活函数,如ReLUs。
2.4、Wide & Deep模型的联合训练(joint training)
联合训练是指同时训练Wide模型和Deep模型,并将两个模型的结果的加权和作为最终的预测结果:
训练的方法:
- Wide模型:FTRL
- Deep模型:AdaGrad
3、apps的推荐系统
本文将上述的Wide & Deep模型应用在Google play的apps推荐中。
3.1、推荐系统
对于推荐系统,其最一般的结构如下图所示:

当一个用户访问app商店时,此时会产生一个请求,请求到达推荐系统后,推荐系统为该用户返回推荐的apps列表。
在实际的推荐系统中,通常将推荐的过程分为两个部分,即上图中的Retrieval和Ranking,Retrieval负责从数据库中检索出与用户相关的一些apps,Ranking负责对这些检索出的apps打分,最终,按照分数的高低返回相应的列表给用户。
3.2、apps推荐的特征
模型的训练之前,最重要的工作是训练数据的准备以及特征的选择,在apps推荐中,可以使用到的数据包括用户和曝光数据。因此,每一条样本对应了一条曝光数据,同时,样本的标签为1表示安装,0则表示未安装。
对于类别特征,通过词典(Vocabularies)将其映射成向量;对于连续的实数特征,将其归一化到区间 [0,1] [ 0 , 1 ] 。

3.3、度量的标准
度量的指标有两个,分别针对在线的度量和离线的度量,在线时,通过A/B test,最终利用安装率(Acquisition);离线则使用AUC作为评价模型的指标。
参考文献
- Cheng H T, Koc L, Harmsen J, et al. Wide & Deep Learning for Recommender Systems[J]. 2016:7-10.
- wide & Deep 和 Deep & Cross 及tensorflow实现
- Wide & Deep 的官方实现
- 深度学习在 CTR 中应用
- 《Wide & Deep Learning for Recommender Systems 》笔记
- 深度学习在美团点评推荐平台排序中的运用
- tensorflow线性模型以及Wide deep learning