Pytorch1.0关于Tensor的自我总结
关于Tensor和Numpy
PyTorch的官方介绍是一个拥有强力GPU加速的张量和动态构建网络的库,其主要构建是张量,所以可以把PyTorch当做Numpy来用,Pytorch的很多操作好比Numpy都是类似的,但是其能够在GPU上运行,所以有着比Numpy快很多倍的速度。
使用下述代码可以将numpy ndarray转换到tensor数据类型
import numpy as np
import torch
# 创建一个numpy ndarray size=10*20
a = np,random.randn(10,20)
# 我们可以使用两种方式将numpy的ndarray转换到tensor上
pytorch_tensor1 = torch.Tensor(a)
pytorch_tensor2 = torch.from_numpy(a)
同样,我们也可以将tensor转换到ndarray
# 此方法只对位于CPU上的tensor有效
numpy_ndarray = pytorch_tensor.numpy()
#如果位于GPU上,需要采用如下代码
numpy_ndarray = pytorch_tensor.cpu().numpy()
Tensor放到GPU上
pytorch中的tensor相对于numpy的最大区别就是可以将Tensor放在GPU上进行计算,这样可以极大地加快运算速度。
# 第一种方式是定义cuda数据类型
gpu_tensor = torch.randn(10,20).type(torch.cuda.FloatTensor)
# 第二种方式更简单,推荐使用
gpu_tensor = torch.randn(10,20).cuda(0) # 将tensor放到第一个GPU上
gpu_tensor = torch.randn(10,20).cuda(1) # 将tensor放到第二个GPU上
使用第一种方式将tensor放到GPU上的时候会将数据类型转换成定义的类型,而是用第二种方式能够直接将tensor放到GPU上,类型跟之前保持一致
推荐在定义tensor的时候就明确数据类型,然后直接使用第二种方法将tensor放到GPU上
Tensor的一些属性
print(pytorch_tensor1.shape)
#获取张量的尺寸
# 得到tensor的数据类型
print(pytorch_tensor1.type())
print(pytorch_tensor1.dim())
#得到tensor的维度,比如1维,2维,3维。。。
# 得到tensor的所有元素个数
print(pytorch_tensor1.numel())
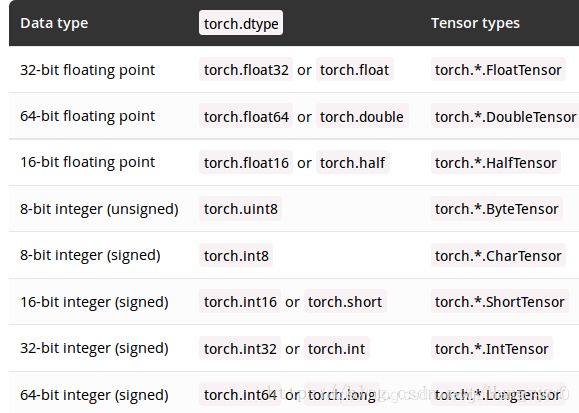
Tensor数据类型
torch.Tensor是一种包含单一数据类型元素的多维矩阵。
Torch定义了七种CPU tensor类型和八种GPU tensor类型:

如果采用torch.Tensor()创建张量,那么它的默认数据类型为torch.FloatTensor.
不同张量之间数据类型的转换:(一般,只要在Tensor后加long(), int(), double(), float(), byte()等函数就能将Tensor的类型进行转换)
tensor = torch.Tensor(3, 5)
torch.long() 将tensor投射为long类型
newtensor = tensor.long()
torch.int()将该tensor投射为int类型
newtensor = tensor.int()
torch.double()将该tensor投射为double类型
newtensor = tensor.double()
如何创建tensor(张量)?
自己在摸索中碰见了很多坑,写在这里总结一下,免得再错!!!
1、典型的tensor构建方法
torch.tensor(data, dtype=None, device=None, requires_grad=False)
#data通常为列表
#dtype通常为上述类型,这个类型不是上表的类似于torch.FloatTensor类型,而应该是类似于torch.float的类型,如下表。
例如:
torch.tensor(data, dtype=torch.float, requires_grad=False)
#device这个参数表示了tensor将会在哪个设备上分配内存。它包含了设备的类型(cpu、cuda)和可选设备序号。如果这个值是缺省的,那么默认为当前的活动设备类型。
通常为
device=torch.device(cuda)
torch.ones(3,3,device=device)
#requires_grad默认为False,可以设置为True
2、从numpy转换得到
3、创建特殊值组成的tensor
torch.zeros(*sizes, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
torch.ones(*sizes, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
torch.randn(*sizes, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
4、安装步长或者区间创建tensor
torch.arange(start=0, end, step=1, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
torch.linspace(start, end, steps=100, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
torch.logspace(start, end, steps=100, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
重大更新
从pytorch 0.4.0 开始,Tensor和Variable类合并了,即现在开始他们两就是一个东西啦!!!(但是Variable也依旧可以使用)
Tensor的一些基本操作
https://blog.csdn.net/qjk19940101/article/details/79555653
https://blog.csdn.net/xholes/article/details/81667211
自动求导
十分需要注意的一个点:只有浮点类型才可以对Tensor设置自动求导,如果是Int类型的话,会报如下错误:
x = torch.IntTensor([[1,2,3],[4,5,6]])
x.requires_grad_(requires_grad=True)
x.requires_grad
RuntimeError: only Tensors of floating point dtype can require gradients``
x = torch.tensor([[1.1, 2.2], [3.3, 4.4]],requires_grad=True)
m = x**2
print(x.requires_grad)
print(m.requires_grad)
out = m.sum()
out.backward()
print(m.grad)
print(x.grad)
True
True
None
tensor([[2.2000, 4.4000],
[6.6000, 8.8000]])
从上面可以看到,变量x和m都可以自动求导(即requires_grad=True),但是只有对x求出了导数,而对m没有求出导数。
个人理解
在自动求导的时候会一直求导到最后一个可以求导的变量(中间结果不会保存),因此只能求出对x导数,没有对m的导数。
如何修改tensor的requires_grad属性?
x = torch.tensor([[1.1, 2.2], [3.3, 4.4]])
m = x**2
m.requires_grad_(requires_grad=True) #修改requires_grad属性
print(x.requires_grad)
print(m.requires_grad)
out = m.sum()
out.backward()
print(m.grad)
print(x.grad)
False
True
tensor([[1., 1.],
[1., 1.]])
None
如何对Tensor的维度进行修改?
1、使用view()对tensor进行reshape
#reshape前后的数据个数要一致
x = torch.randn(3,4,5)
x = x.view(-1, 5)
# -1 表示任意的大小,5表示第二维变成5
print(x.shape)
x = x.view(-1, 5)
# -1 表示任意的大小,5表示第二维变成5
print(x.shape)
torch.Size([12, 5])
torch.Size([3, 20])
2、squeeze()
torch.squeeze(input, dim=None, out=None)
input为输入的tensor
dim为输入的维度,如果该维度对应的维度值为1,就删除,否则不变。如果不输入dim,那么就删除所有维度值为1的维度
x = torch.randn(3,4,1,5)
print(x.size())
b = torch.squeeze(x,2)
print(b.size())
c = torch.squeeze(x,1)
print(c.size())
torch.Size([3, 4, 1, 5])
torch.Size([3, 4, 5])
torch.Size([3, 4, 1, 5])
3、unsqueeze
与squeeze的含义相反
c=torch.Tensor(3)
print(c,c.size())
d = torch.unsqueeze(c,0)
print(d.size())
e = torch.unsqueeze(c,1)
print(e.size())
tensor([1.0426e-42, 0.0000e+00, 1.0426e-42]) torch.Size([3])
torch.Size([1, 3])
torch.Size([3, 1])
torch.max()
torch.max()返回两个结果,第一个是最大值,第二个是对应的索引值;第二个参数 0 代表按列取最大值并返回对应的行索引值,1 代表按行取最大值并返回对应的列索引值。
d=torch.Tensor([[1,3],[2,4]])
value1,index1=torch.max(d,0)
value2,index2=torch.max(d,1)
print(value1,index1)
print(value2,index2)
tensor([2., 4.]) tensor([1, 1])
tensor([3., 4.]) tensor([1, 1])