《啊哈!算法》读书笔记
《啊哈!算法》
零零散散花了一周的时间阅读了《啊哈!算法》。这本书内容相对基础,适合初学者时阅读(当然,大神也可以温故而知新)。《啊哈!算法》这本书中的算法举例贴近生活,语言诙谐幽默,不会让人产生枯燥感,并配有很多幽默的插图。算法讲解通俗易懂,并配有详细C语言代码和注释,是一本初学者不易错过的好书。注:书作者偶尔会在书中卖萌的。已掌握的知识点在下面不在赘述,只记录觉得需要记忆整理的东西,作为自己的读书笔记。包括一些小技巧、新概念、生疏算法等。内容仍比较杂乱,需要进一步细化整理。
来两张配图
快排:
冒泡排序:
《啊哈!算法》中涉及的数据结构有栈、队列、链表、树、并查集、堆和图等;涉及的算法有排序、枚举、深度和广度优先搜索、图的遍历,当然还有图论中不可以缺少的四种最短路径算法、两种最小生成树算法、割点与割边算法、二分图的最大匹配算法等。
第一章 排序
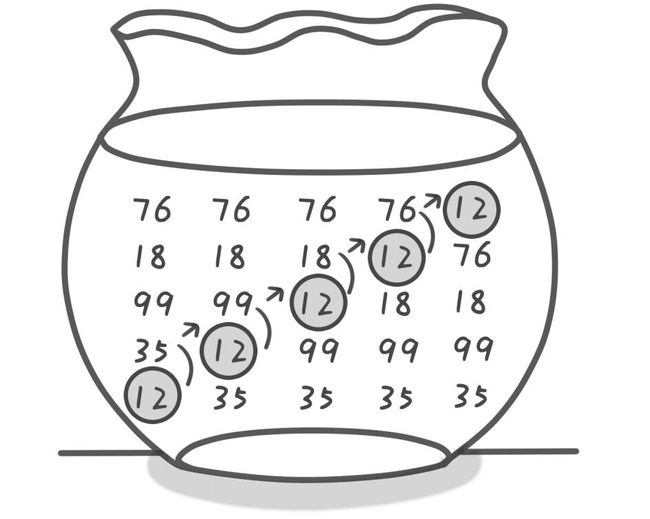
桶排序、冒泡排序、快速排序
1.当需要对5个人的名字和分数排序:
| 名字 |
Huhu |
Haha |
Hengheng |
Gaoshou |
Xixi |
| 分数 |
5 |
3 |
5 |
2 |
8 |
使用简单的桶排序只能对分数进行排序,如何找分数对应的人呢?
可以使用”结构体+排序算法”解决
struct student{
char name[21];
Int score;
}2.快速排序中
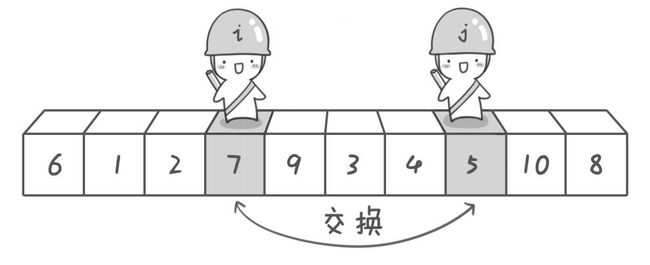
待排矩阵为A[]:
| 6 | 1 | 2 | 7 | 9 | 3 | 4 | 5 | 10 | 8 |
如果设置基准数是最左边的数,最左边的哨兵为i,最右边的那么需要哨兵j先走。因为这样才能保证最后哨兵i和j相遇的时候,A[i]=A[j]>=A[1]。这样与A[j]与A[1]交换后才满足快排算法分组要求,哨兵左边的数小于等于哨兵,右边的数大于等于哨兵。
3.数列去重并排序(只保留不同的数,并从小到大排序)
方法1:先去重,后排序
例:桶排序
去重代码:
%init
for(i=1;i<=n;i++){
scanf(“%d”,&t);
a[t]=1;//标记出现过的数
}
%printf方法2:先排序,后去重
例:冒泡排序
去重代码:
%sort
for(i=2;i<=n;i++){
if(a[i] != a[i-1])/如果当前这个数是第一次出现就输出
Printf(“%d”,a[i]);
}第二章 栈、队列、链表
1.队列的队首head和队尾的下一个位置tail
问题:为什么tail不直接记录队尾?
答:队首和队尾重合时会带来一些麻烦。我们规定队首和队尾重合时,队列为空。(其实也可以直接记录队尾,依据自己情况而定)
2.栈解密回文很方便
3.链表
链表的另一种表现形式(不用指针,数组形式实现)
模拟链表:数组data存储序列中的每一个数,数组right存放序列中每一个数右边的数是谁
如果要表示链表2->3->4->8->9->10->18->26->32
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
| Data |
2 |
3 |
4 |
8 |
9 |
10 |
18 |
26 |
32 |
|
| Right |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
0 |
如果在8 的前面插入 6 , 2->3->4-> 6->8->9->10->18->26->32 那么数组修改 : 注:right[0] 表示右边没有元素
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
| Data |
2 |
3 |
4 |
8 |
9 |
10 |
18 |
26 |
32 |
6 |
| Right |
2 |
3 |
10 |
5 |
6 |
7 |
8 |
9 |
0 |
4 |
第三章 枚举
1.暴力枚举问题
可以思考是否可以采用深度优先搜索(DFS)和广度优先搜索(BFS)代替,从而简化算法。
第四章 搜索
深度优先搜索和广度优先搜索
1.深度优先搜索基本模型
Void dfs(int step)
{
判断边界//边界中注意ruturn
尝试每一种可能 for(i=1;i<=n;i++)
{
继续下一步 dsf(step+1);
}
返回
}2.Floodfill漫水填充法(也称种子填充法)
3.DFS与BFS时间复杂度都是O(|V| + |E|),其中|V|是节点的数目,而|E|是图中边的数目。
第五章 图
1图是一种比线性表和树更为复杂的数据结构
线性表:元素之间是线性关系,即表中元素最多一个直接前驱和一个直接后继。
树:元素之间是层次关系。除根外,元素只有唯一直接前驱,但可以有若干个直接后继。
图:任意的两个元素都可能相关,即图中任一元素可以有若干个直接前驱和直接后继,属于网状结构类型。
注意:实际上,树是图的特列---有向无环图
2.图的邻接矩阵存储法和邻接表存储法
第六章 最短路径
最短路径算法对比分析
|
|
Floyd |
Dijkstra |
Bellman-Ford |
队列优化的Bellman-Ford |
| 空间复杂度 |
O(N^2) |
O(M) |
O(M) |
O(M) |
| 时间复杂度 |
O(N^3) |
O((M+N)logN) |
O(NM) |
最坏是O(NM) |
| 适用情况 |
1.稠密图 2.和顶点关系密切 |
1.稠密图 2.和顶点关系密切 |
1.稀疏图 2.和边关系密切 |
1.稀疏图 2.和边关系密切 |
| 负权 |
可以解决负权 |
不能解决负权 |
可以解决负权 |
可以解决负权 |
注:其中N表示点数,M表示边数
Floyd算法虽然总体时间复杂度,但是可以解决负权边(不能解决负权环,实际上这几种都无法解决负权回路,因为一直循环下去总能找到更小的路径),并且均摊到每一点对上,在所有的算法中还是比较好的. Floyd算法代码复杂度小也是一大优势. Dijkstra算法最大的弊端就是无法适应有负权边的图,但Dijkstra具有很好的可扩展性,另外在Dijkstra算法在选择剩余不在最短路径顶点的集合中选择最小值是可以堆优化,这样算法的时间复杂度可以达到O(MlogN). 当图中含有负边时,使用Bellman-Ford或者队列优化的Bellman-Ford算法.
第七章 树
1.树其实就是不含回路的无向图
2.堆是一种特殊的特殊的完全二叉树
3.优先队列:支持插入元素和寻找最大(小)值元素的数据结构。
如果使用普通队列来实现这个两个功能,那么寻找最大元素需要枚举整个队列,这样的时间复杂度比较高。如果已排序好的数组,那么插入一个元素则需要移动很多元素,时间复杂度依旧很高。而堆就是一种优先队列的实现,可以很好的解决这两种操作。
4.堆还经常被用来求一个数列中第K大的数。只需要建立一个大小为K的最小堆,堆顶就是第K大的数。如果求一个数列中第K小的数,只最需要建立一个大小为K的最大堆,堆顶就是第K小的数,这种方法的时间复杂度是O(NlogK)。当然你也可以用堆来求前K大的数和前K小的数。
5.并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示。
第八章 更多精彩算法
1.最小生成树
Kruskal算法是一步步地将森林中的树进行合并,而Prim算法则是通过每次增加一条边来建立一棵树
Kruskal算法适用于稀疏图,没有使用堆优化的Prim算法适用于稠密图,使用了堆优化Prim算法则适用于稀疏图。
2.图的割点与割边
3.二分图最大匹配
第九章 还能更好吗——微软亚洲研究院面试