机器学习算法-线性回归
机器学习算法-线性回归
- 一. 理论基础
- 1.1 凸函数
- 1.2 线性
- 1.3 极大似然估计
- 二. 线性回归模型(目标函数)
- 2.1 线性回归定义
- 2.2 线性回归模型
- 三. 代价函数求解
- 3.1 定义代价函数的方法
- 3.1.1 最小二乘法
- 3.1.2 极大似然法
- 3.2 代价函数求解
- 3.2.1 正规方程
- 3.2.2 梯度下降
- 3.2.3 正规方程和梯度下降比较
- 四. 模型评估
- 五. Sklearn 参数说明
- 六. 理解L1和L2
- 参考
一. 理论基础
1.1 凸函数
某个向量空间的凸子集(区间)上的实值函数,如果在其定义域上的任意两点 ,有 f(tx + (1-t)y) <= tf(x) + (1-t)f(y),则称其为该区间上的凸函数;
更直观的理解:

1.2 线性
线性不等于直线
线性函数的定义是:一阶(或更低阶)多项式,或零多项式。
当线性函数只有一个自变量时,y = f(x);
但如果有多个独立自变量,表示为:
f ( x 1 , x 2 , . . . . . . ) = a + b 1 x 1 + . . . . . . . . + b k x k f(x_1,x_2,......) = a+b_1x_1+........+ b_kx_k f(x1,x2,......)=a+b1x1+........+bkxk
总结: 特征是一维的,线性模型在二维空间构成一条直线;特征是二维的,线性模型在三维空间中构成一个平面;若特征是三维的,则最终模型在四维空间中构成一个体;以此类推……
1.3 极大似然估计
极大似然估计:从样本中随机抽取n个样本,而模型的参数估计量使得抽取的这n个样本的观测值的概率最大。最大似然估计是一个统计方法,它用来求一个样本集的概率密度函数的参数。
二. 线性回归模型(目标函数)
2.1 线性回归定义
利用线性函数对一个或多个自变量 (x 或 ( x 1 , x 2 , . . . . . . . , x k x_1,x_2,.......,x_k x1,x2,.......,xk))和因变量(y)之间的关系进行拟合的模型
2.2 线性回归模型
一般线性模型表示:
y ^ = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . . . . θ n x n \hat{y} = θ_0+θ_1x_1+\theta_2x_2+......\theta_nx_n y^=θ0+θ1x1+θ2x2+......θnxn
其中 x 1 , x 2 x_1,x_2 x1,x2等表示不同的特征, θ 0 , θ 1 \theta_0,\theta_1 θ0,θ1等表示权重; 通过向量的形式表示为: y ^ = h θ ( x ) = θ T x \hat{y}=h_\theta(x)=\theta^Tx y^=hθ(x)=θTx
三. 代价函数求解
3.1 定义代价函数的方法
3.1.1 最小二乘法
线性模型用一个直线(平面)拟合数据点,找出一个最好的直线(平面)即要求每个真实点距离平面的距离最近。即使得残差平方和(Residual Sum of Squares, RSS)最小:
R S S ( X , h θ ) = ∑ i = 0 m ( θ T x i − y i ) 2 RSS(X,h_\theta)= \sum^m_{i=0}(\theta^Tx^i-y^i)^2 RSS(X,hθ)=i=0∑m(θTxi−yi)2
另一种情况下,为消除样本量的差异,也会用最小化均方误差(MSE)拟合:
M S E ( X , h θ ) = 1 m ∑ i = 0 m ( θ T x i − y i ) 2 MSE(X,h_\theta)= \frac{1}{m}\sum^m_{i=0}(\theta^Tx^i-y^i)^2 MSE(X,hθ)=m1i=0∑m(θTxi−yi)2
3.1.2 极大似然法
真实值与预测值存在的差异(用 ε表示误差): y ( i ) = θ T x i + ε ( i ) y^{(i)} = \theta^Tx^i +\varepsilon^{(i)} y(i)=θTxi+ε(i)
且误差 ε ( i ) \varepsilon^{(i)} ε(i) 是独立并且同分布的, 并且服从均值为 0 方差 为 θ 2 \theta^2 θ2的高斯分布:
p ( ε ( i ) ) = 1 2 π σ e x p ( − ( ε ( i ) ) 2 2 σ 2 ) p(\varepsilon^{(i)})= \frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{{(\varepsilon^{(i)})^2}}{2\sigma^2}) p(ε(i))=2πσ1exp(−2σ2(ε(i))2)
p ( ε ( i ) ) = p ( y ( i ) ∣ x i , ε ( i ) ) p(\varepsilon^{(i)}) = p(y^{(i)}\mid x^i,\varepsilon^{(i)}) p(ε(i))=p(y(i)∣xi,ε(i))
查看具体推导
3.2 代价函数求解
3.2.1 正规方程

wiki矩阵求导
3.2.2 梯度下降
-
批量梯度下降(Batch Gradient Descent)
批量梯度下降法,是梯度下降法最常用的形式,具体做法也就是在更新参数时使用所有的样本来进行更新。
θ i = θ i − α ∑ j = 0 m ( h θ ( x 0 j , x 1 j . . . . . . . , x n j ) − y j ) x i \theta_i=\theta_i-\alpha\sum^m_{j=0}{(h_\theta(x^j_0,x^j_1.......,x^j_n)-y^j)x^i} θi=θi−αj=0∑m(hθ(x0j,x1j.......,xnj)−yj)xi
优点:得到全局最优解;易于并行实现
缺点:当样本数目很多时,训练过程会很慢
查看具体推导 -
随机梯度下降(Stochastic Gradient Descent)
随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度。对应的更新公式是:
θ i = θ i − α ( h θ ( x 0 j , x 1 j . . . . . . . , x n j ) − y j ) x i \theta_i=\theta_i-\alpha{(h_\theta(x^j_0,x^j_1.......,x^j_n)-y^j)x^i} θi=θi−α(hθ(x0j,x1j.......,xnj)−yj)xi
优点:训练速度快
缺点:准确度下降,可能跳出最优解,不是全局最优 -
小批量梯度下降法(Mini-batch Gradient Descent)
进行迭代时选用部分样本, 1θ i = θ i − α ∑ j = t t + x − 1 ( h θ ( x 0 j , x 1 j . . . . . . . , x n j ) − y j ) x i \theta_i=\theta_i-\alpha\sum^{t+x-1}_{j=t}{(h_\theta(x^j_0,x^j_1.......,x^j_n)-y^j)x^i} θi=θi−αj=t∑t+x−1(hθ(x0j,x1j.......,xnj)−yj)xi
3.2.3 正规方程和梯度下降比较
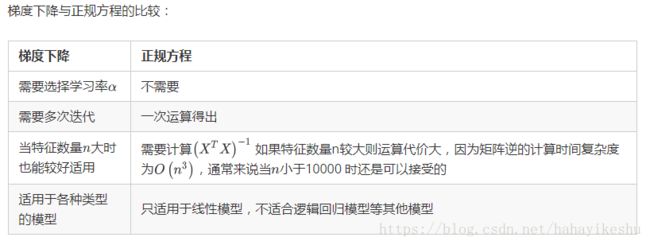
四. 模型评估
回归评价指标 MSE(均方误差)、RMSE(均方根误差)、MAE(平均绝对误差)、R-Squared;Sklearn 中使用R-squared
查看几种误差详细介绍
五. Sklearn 参数说明
参考Datawhale
六. 理解L1和L2
为什么L1正则化可以产生稀疏模型(L1是怎么让系数等于零的),以及为什么L2正则化可以防止过拟合
参考
1.吴恩达机器学习
2.线性回归-Datawhale
3.机器学习回归分析-线性回归
4.李烨-机器学习极简入门课
5.线性回归-爖