支持向量机和随机树(随机森林)两种影像分类方法
一 arcgis10.6种有这两种方法
深度学习与图像分类图像分类是基于不同地物光谱、形状等特征差异将影像转化为分类数据和信息,用于统计分析。ArcGIS Pro支持面向对象分类及基于像素的分类两种方式,提供传统分类和先进的机器学习方法,帮助您向导式完成图像分类与信息提取。

ArcGIS Pro集成的机器学习图像分类方法包括:最大似然分类,随机树,支持向量机等。
在Pro 2.1中,ArcGIS提供2个深度学习相关的GP工具:
Export Training Data for Deep Learning支持将样本处理为深度学习需要数据大小,减少样本处理工作量;

Deep Learning Model to ecd工具,支持将来自Google TensorFlow, Microsoft CNTK或者其他计算框架,生成的深度学习模型。
通过ArcGIS 栅格函数计算框架,训练模型可以直接接入,实现高分图像分类。
网址:http://pro.arcgis.com/zh-cn/pro-app/help/data/imagery/the-image-classification-wizard.htm这个是pro中的
具体说明如下:
1.随机树
随机树分类器是用于图像分类的一种强大技术,它可防止过度拟合,并可处理分割影像及其他辅助栅格数据集。对于标准影像输入,该工具接受具有任意位深度的多波段影像,它还会基于输入训练要素文件对每个要素执行随机树分类(有时称为随机森林分类)。
2.支持向量机
支持向量机 (SVM) 分类器提供了一种强大的分类方法,可用于处理分割栅格输入或标准影像。它不那么容易被噪音、关联波段以及每个类中不平衡的训练场数量或大小所影响。这是一种被研究人员广泛采用的分类方法。
二 百度里面的解释
1.随机树(随机森林)
https://baike.baidu.com/item/%E9%9A%8F%E6%9C%BA%E6%A3%AE%E6%9E%97/1974765?fr=aladdin
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。该分类器最早由Leo Breiman和Adele Cutler提出,并被注册成了商标。
定义
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 Leo Breiman和Adele Cutler发展出推论出随机森林的算法。 而 "Random Forests" 是他们的商标。 这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合 Breimans 的 "Bootstrap aggregating" 想法和 Ho 的"random subspace method"以建造决策树的集合。
根据下列算法而建造每棵树[1] :
用N来表示训练用例(样本)的个数,M表示特征数目。
输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这m个特征,计算其最佳的分裂方式。
每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用)。
随机森林优点
随机森林的优点有[2] :
1)对于很多种资料,它可以产生高准确度的分类器;
2)它可以处理大量的输入变数;
3)它可以在决定类别时,评估变数的重要性;
4)在建造森林时,它可以在内部对于一般化后的误差产生不偏差的估计;
5)它包含一个好方法可以估计遗失的资料,并且,如果有很大一部分的资料遗失,仍可以维持准确度;
6)它提供一个实验方法,可以去侦测variable interactions;
7)对于不平衡的分类资料集来说,它可以平衡误差;
8)它计算各例中的亲近度,对于数据挖掘、侦测离群点(outlier)和将资料视觉化非常有用;
9)使用上述。它可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类。也可侦测偏离者和观看资料;
10)学习过程是很快速的。
随机森林相关概念
1.分裂:在决策树的训练过程中,需要一次次的将训练数据集分裂成两个子数据集,这个过程就叫做分裂。
2.特征:在分类问题中,输入到分类器中的数据叫做特征。以上面的股票涨跌预测问题为例,特征就是前一天的交易量和收盘价。
3.待选特征:在决策树的构建过程中,需要按照一定的次序从全部的特征中选取特征。待选特征就是在目前的步骤之前还没有被选择的特征的集合。例如,全部的特征是 ABCDE,第一步的时候,待选特征就是ABCDE,第一步选择了C,那么第二步的时候,待选特征就是ABDE。
4.分裂特征:接待选特征的定义,每一次选取的特征就是分裂特征,例如,在上面的例子中,第一步的分裂特征就是C。因为选出的这些特征将数据集分成了一个个不相交的部分,所以叫它们分裂特征。
随机森林决策树构建
要说随机森林,必须先讲决策树。决策树是一种基本的分类器,一般是将特征分为两类(决策树也可以用来回归,不过本文中暂且不表)。构建好的决策树呈树形结构,可以认为是if-then规则的集合,主要优点是模型具有可读性,分类速度快。
我们用选择量化工具的过程形象的展示一下决策树的构建。假设现在要选择一个优秀的量化工具来帮助我们更好的炒股,怎么选呢?
第一步:看看工具提供的数据是不是非常全面,数据不全面就不用。
第二步:看看工具提供的API是不是好用,API不好用就不用。
第三步:看看工具的回测过程是不是靠谱,不靠谱的回测出来的策略也不敢用啊。
第四步:看看工具支不支持模拟交易,光回测只是能让你判断策略在历史上有用没有,正式运行前起码需要一个模拟盘吧。
这样,通过将“数据是否全面”,“API是否易用”,“回测是否靠谱”,“是否支持模拟交易”将市场上的量化工具贴上两个标签,“使用”和“不使用”。
上面就是一个决策树的构建,逻辑可以用图1表示:
 图1.决策树构建1
图1.决策树构建1
在图1中,绿颜色框中的“数据”“API”“回测”“模拟交易”就是这个决策树中的特征。如果特征的顺序不同,同样的数据集构建出的决策树也可能不同。特征的顺序分别是“数据”“API”“回测”“模拟交易”。如果我们选取特征的顺序分别是“数据”“模拟交易”“API”“回测”,那么构建的决策树就完全不同了。
可以看到,决策树的主要工作,就是选取特征对数据集进行划分,最后把数据贴上两类不同的标签。如何选取最好的特征呢?还用上面选择量化工具的例子:假设现在市场上有100个量化工具作为训练数据集,这些量化工具已经被贴上了“可用”和“不可用”的标签。
我们首先尝试通过“API是否易用”将数据集分为两类;发现有90个量化工具的API是好用的,10个量化工具的API是不好用的。而这90个量化工具中,被贴上“可以使用”标签的占了40个,“不可以使用”标签的占了50个,那么,通过“API是否易用”对于数据的分类效果并不是特别好。因为,给你一个新的量化工具,即使它的API是易用的,你还是不能很好贴上“使用”的标签。
 图2.决策树的构建2
图2.决策树的构建2
再假设,同样的100个量化工具,通过“是否支持模拟交易”可以将数据集分为两类,其中一类有40个量化工具数据,这40个量化工具都支持模拟交易,都最终被贴上了“使用”的标签,另一类有60个量化工具,都不支持模拟交易,也都最终被贴上了“不使用”的标签。如果一个新的量化工具支持模拟交易,你就能判断这个量化工具是可以使用。我们认为,通过“是否支持模拟交易”对于数据的分类效果就很好。
在现实应用中,数据集往往不能达到上述“是否支持模拟交易”的分类效果。所以我们用不同的准则衡量特征的贡献程度。主流准则的列举3个:ID3算法(J. Ross Quinlan于1986年提出)采用信息增益最大的特征;C4.5算法(J. Ross Quinlan于1993年提出)采用信息增益比选择特征;CART算法(Breiman等人于1984年提出)利用基尼指数最小化准则进行特征选择。
随机森林随机森林构建
决策树相当于一个大师,通过自己在数据集中学到的知识对于新的数据进行分类。但是俗话说得好,一个诸葛亮,玩不过三个臭皮匠。随机森林就是希望构建多个臭皮匠,希望最终的分类效果能够超过单个大师的一种算法。
那随机森林具体如何构建呢?有两个方面:数据的随机性选取,以及待选特征的随机选取。
1.数据的随机选取:
首先,从原始的数据集中采取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。第二,利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。最后,如果有了新的数据需要通过随机森林得到分类结果,就可以通过对子决策树的判断结果的投票,得到随机森林的输出结果了。如下图,假设随机森林中有3棵子决策树,2棵子树的分类结果是A类,1棵子树的分类结果是B类,那么随机森林的分类结果就是A类。 图3.数据的随机选取
图3.数据的随机选取
2.待选特征的随机选取
与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。下图中,蓝色的方块代表所有可以被选择的特征,也就是目前的待选特征。黄色的方块是分裂特征。左边是一棵决策树的特征选取过程,通过在待选特征中选取最优的分裂特征(别忘了前文提到的ID3算法,C4.5算法,CART算法等等),完成分裂。右边是一个随机森林中的子树的特征选取过程。
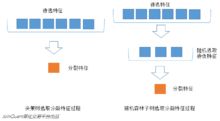 图4.待选特征的随机选取
图4.待选特征的随机选取
2.支持向量机
支持向量机(Support Vector Machine,SVM)是Corinna Cortes和Vapnik等于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
在机器学习中,支持向量机(SVM,还支持矢量网络)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,用于分类和回归分析。
简介
支持向量机方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折中,以求获得最好的推广能力 。
支持向量机总体概述:
在机器学习中,支持向量机(SVM,还支持矢量网络)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,用于分类和回归分析。给定一组训练样本,每个标记为属于两类,一个SVM训练算法建立了一个模型,分配新的实例为一类或其他类,使其成为非概率二元线性分类。一个SVM模型的例子,如在空间中的点,映射,使得所述不同的类别的例子是由一个明显的差距是尽可能宽划分的表示。新的实施例则映射到相同的空间中,并预测基于它们落在所述间隙侧上属于一个类别。除了进行线性分类,支持向量机可以使用所谓的核技巧,它们的输入隐含映射成高维特征空间中有效地进行非线性分类。
支持向量机有关介绍:
更正式地说,一个支持向量机的构造一个超平面,或在高或无限维空间,其可以用于分类,回归,或其它任务中设定的超平面的。直观地,一个良好的分离通过具有到任何类(所谓官能余量)的最接近的训练数据点的最大距离的超平面的一般实现中,由于较大的裕度下分类器的泛化误差。而原来的问题可能在一个有限维空间中所述,经常发生以鉴别集是不是在该空间线性可分。出于这个原因,有人建议,在原始有限维空间映射到一个高得多的立体空间,推测使分离在空间比较容易。保持计算负荷合理,使用支持向量机计划的映射被设计成确保在点积可在原空间中的变量而言容易地计算,通过定义它们中选择的核函数k(x,y)的计算以适应的问题。
在高维空间中的超平面被定义为一组点的点积与该空间中的向量是恒定的。限定的超平面的载体可被选择为线性组合与参数\alpha_i中发生的数据的基础上的特征向量的图像。这种选择一个超平面,该点中的x的特征空间映射到超平面是由关系定义:\字型\sum_i\alpha_ik(x_i中,x)=\mathrm{常数}。注意,如果k(x,y)变小为y的增长进一步远离的x,在求和的每一项测量测试点x的接近程度的相应数据基点x_i的程度。以这种方式,内核上面的总和可以被用于测量各个测试点的对数据点始发于一个或另一个集合中的要被鉴别的相对接近程度。注意一个事实,即设定点的x映射到任何超平面可以相当卷积的结果,使集未在原始空间凸出于各之间复杂得多歧视。
支持向量机相关知识
我们通常希望分类的过程是一个 机器学习的过程。这些数据点是n维实空间中的点。我们希望能够把这些点通过一个n-1维的 超平面分开。通常这个被称为 线性 分类器。有很多分类器都符合这个要求。但是我们还希望找到分类最佳的平面,即使得属于两个不同类的数据点间隔最大的那个面,该面亦称为最大间隔 超平面。如果我们能够找到这个面,那么这个分类器就称为最大间隔分类器。支持向量机支持原因
支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的 超平面的两边建有两个 互相平行的超平面。建立方向合适的分隔 超平面使两个与之平行的超平面间的距离最大化。其假定为,平行 超平面间的距离或差距越大,分类器的总误差越小。一个极好的指南是C.J.C Burges的《模式识别支持向量机指南》。
支持向量机支持向量概述
所谓支持向量是指那些在间隔区边缘的训练样本点。 这里的“机(machine,机器)”实际上是一个 算法。在机器学习领域,常把一些算法看做是一个机器。支持向量机(Support vector machines,SVM)与 神经网络类似,都是学习型的机制,但与神经网络不同的是SVM使用的是数学方法和优化技术。
支持向量机相关技术支持
支持向量机是由Vapnik领导的AT&T Bell实验室研究小组在1995年提出的一种新的非常有潜力的分类技术,SVM是一种基于统计学习理论的 模式识别方法,主要应用于模式识别领域。由于当时这些研究尚不十分完善,在解决模式识别问题中往往趋于保守,且 数学上比较艰涩,这些研究一直没有得到充分的重视。直到90年代,统计学习理论 (Statistical Learning Theory,SLT)的实现和由于神经网络等较新兴的机器学习方法的研究遇到一些重要的困难,比如如何确定网络结构的问题、过学习与欠学习问题、局部极小点问题等,使得SVM迅速发展和完善,在解决小样本、非线性及 高维模式识别问题中表现出许多特有的优势,并能够推广应用到 函数 拟合等其他机器学习问题中。从此迅速的发展起来,已经在许多领域( 生物信息学,文本和手写识别等)都取得了成功的应用。
在 地球物理反演当中解决 非线性反演也有显著成效,例如(支持向量机在预测地下水涌水量问题等)。已知该 算法被应用的主要有: 石油测井中利用测井资料预测地层 孔隙度及 粘粒含量、 天气预报工作等。
支持向量机中的一大亮点是在传统的最优化问题中提出了 对偶理论,主要有最大最小对偶及 拉格朗日对偶。
SVM的 关键在于核函数。低 维空间向量集通常难于划分,解决的方法是将它们映射到 高维空间。但这个办法带来的困难就是计算 复杂度的增加,而 核函数正好巧妙地解决了这个问题。也就是说,只要选用适当的 核函数,就可以得到 高维空间的分类函数。在SVM理论中,采用不同的 核函数将导致不同的SVM算法。
在确定了核函数之后,由于确定核函数的已知数据也存在一定的 误差,考虑到推广性问题,因此引入了松弛系数以及惩罚系数两个参变量来加以校正。在确定了 核函数基础上,再经过大量对比实验等将这两个系数取定,该项研究就基本完成,适合相关学科或业务内应用,且有一定能力的推广性。当然误差是绝对的,不同学科、不同专业的要求不一。
支持向量机的理解需要数据挖掘或机器学习的相关背景知识,在没有背景知识的情况下,可以先将支持向量机看作简单分类工具,再进一步引入核函数进行理解。 [1]