Neo4j学习(3):操作图数据库的语言--Cypher
Cypher是一种用来处理图数据库的语言,语法比较简单。
1 查询数据库里的数据
match(n) return nmatch是匹配规则,(n)表示所有节点,语法要求加上小括号。
return n表示返回匹配到的所有节点
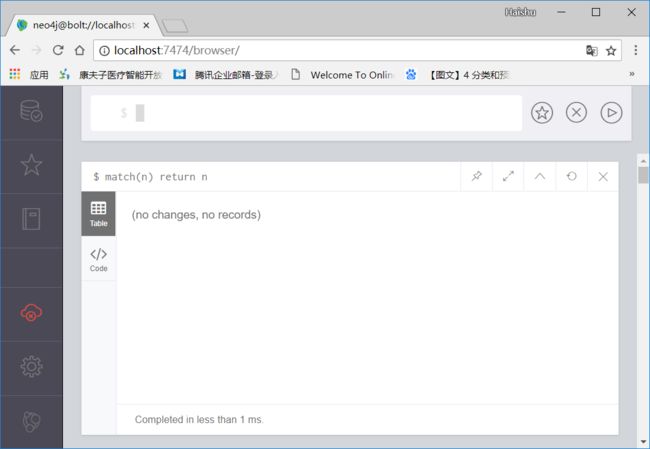
刚安装完,数据库里没有数据。所以显示“no records”。
2 创建一个节点
CREATE (p1:Person { name: "Liu Da", age: 20})p1是变量名,Person是节点名,{}内包含了节点的两个属性。

查询数据库中的所有节点
match(n) return n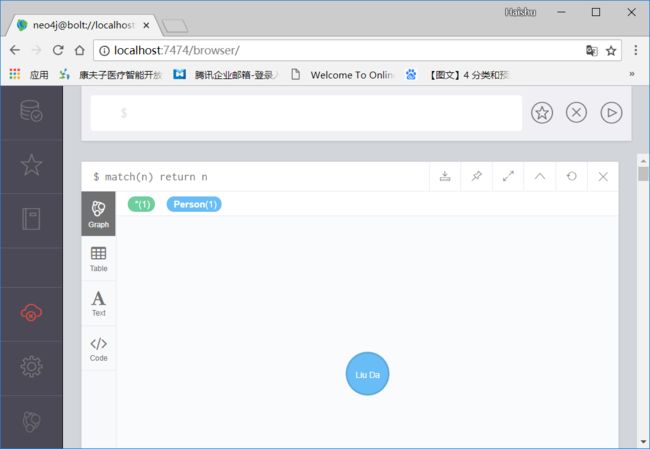
3 删除单节点
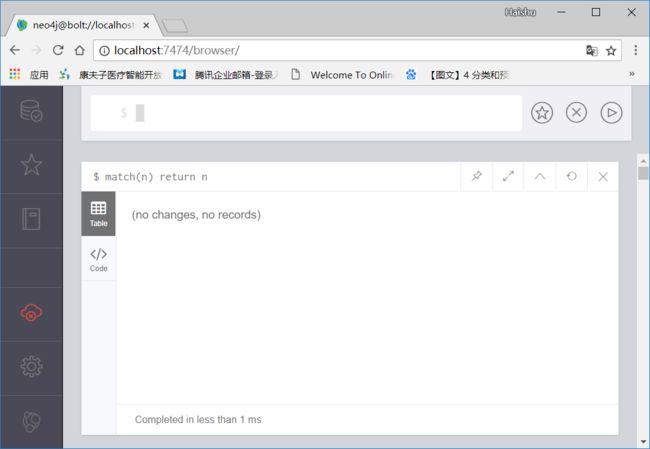
match(p1:Person) detach delete p1
查询数据库中的节点,如果删除成功的话,此时数据库里没有节点
4 创建两个节点并建立关系
create
(p1:Person{name:"Liu Da", age:20}),
(p2:Person{name:"Chen Er", age:22}),
(p1)-[:KNOWS]->(p2)
这里创建了两个节点,并且Liu Da知道Chen Er,但Chen Er不知道Liu Da
查询这两个节点及关系
MATCH (p1: Person)-[KNOWS]-(p2: Person) return p1,KNOWS,p2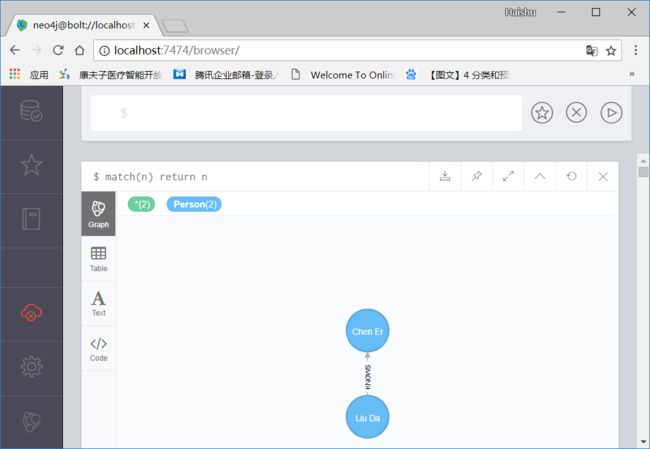
5 删除两个节点和它们的关系
注意,neo4j删除节点时,要求把关系一并删除掉。不能只删除节点,不删除关系。
MATCH (p1: Person)-[KNOWS]-(p2: Person)
DELETE p1, KNOWS, p2
查询所有节点

6 为节点增加属性
create(p1:Person{name:"Liu Da"})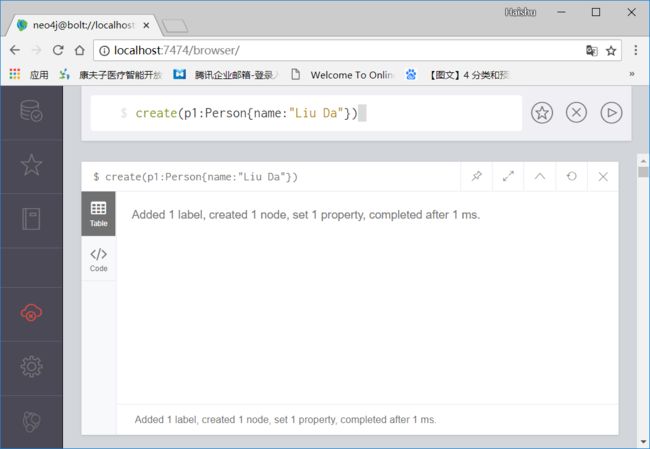
match(p1) set p1.age = 20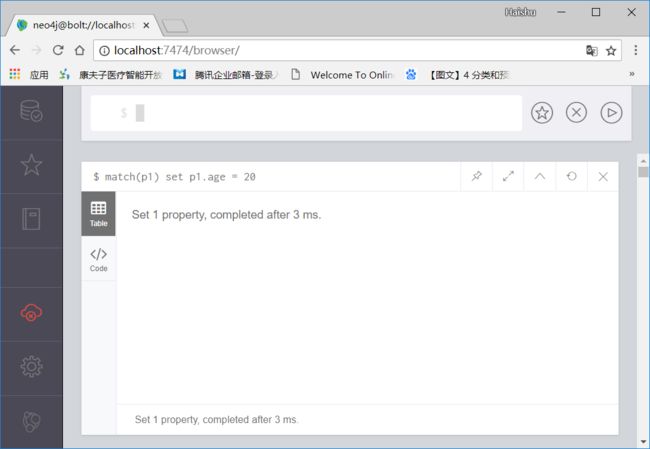

7 修改节点属性
match(p1) set p1.age = 33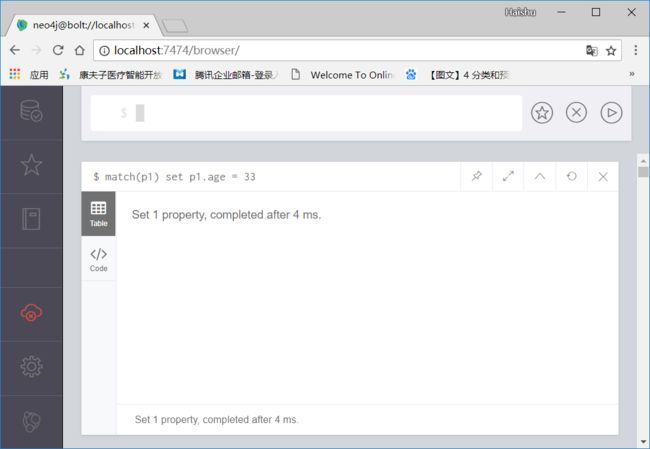
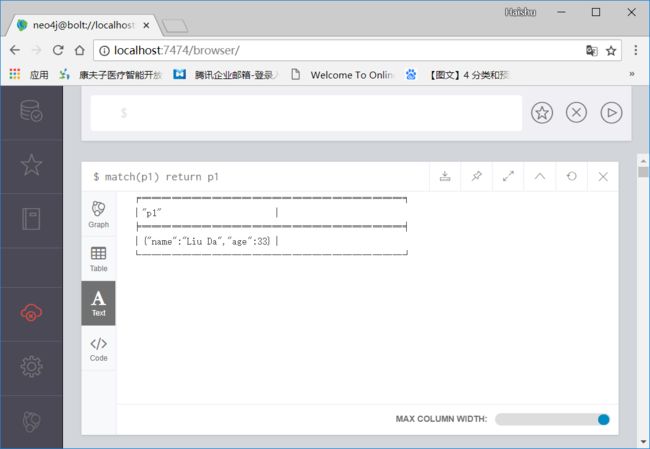
8 查找节点的共有属性
CREATE
(p2:Person { name: "Liu Er", age: 15, learn: "Muay Thai" }),
(p3:Person { name: "Zhang San", age: 25, sex: “Male” }),
(p4:Person { name: "Li Si", age: 30, hobby: "Muay Thai" }),
(p2)-[:KNOWS]->(p3),
(p3)-[:KNOWS]->(p2),
(p3)-[:KNOWS]->(p4)
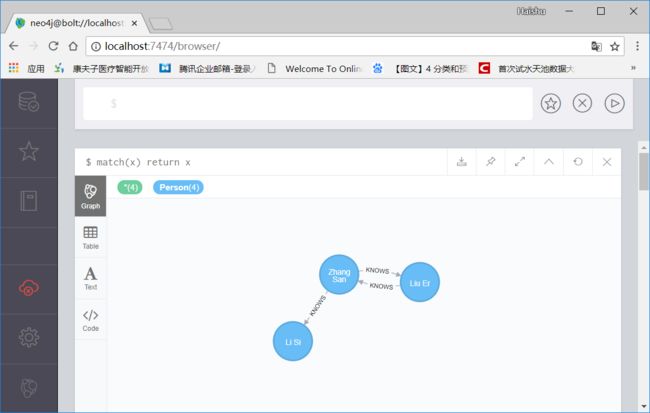
Liu Er和Zhang San互相认识,
Zhang San认识Li Si,
Li Si不认识Zhang San和Liu Er,
Liu Er正在学习泰拳,
Li Si的爱好是泰拳。
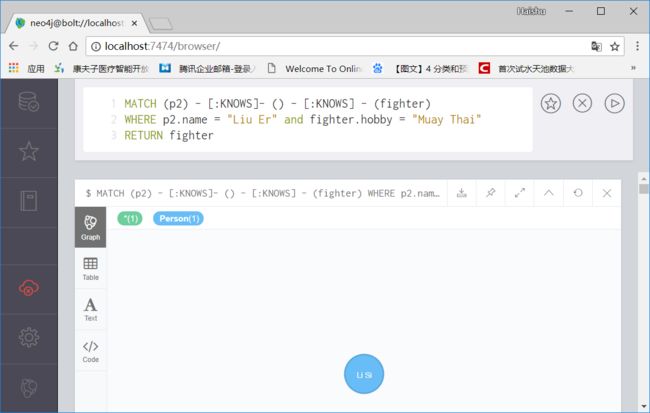
MATCH (x) - [:KNOWS]- () - [:KNOWS] - (fighter)
WHERE x.name = "Liu Er" and fighter.hobby = "Muay Thai"
RETURN fighter这里先找出p2认识的人,因为这个人不是最终要找的人,所以()里不用填写变量名,再通过这个人找出业余爱好为泰拳的人,这个人用变量fighter来表示。
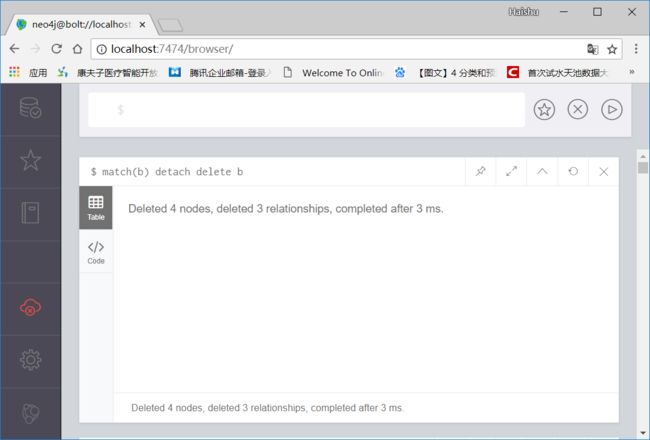
9 删除所有节点
先看数据库里有多少个节点
match(a) return a
删除所有节点和关系
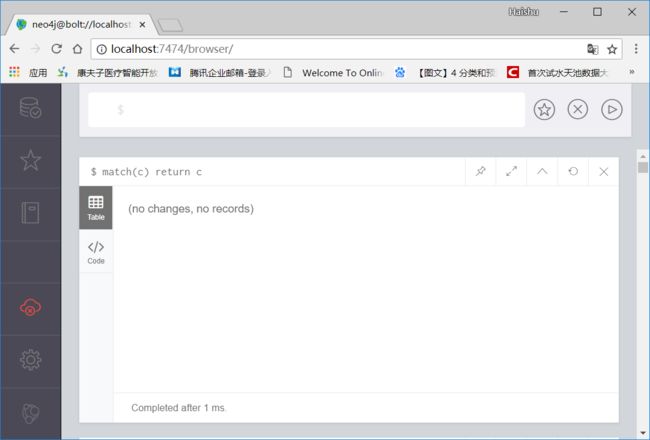
再次查询数据库里的所有节点
10 导入csv数据
从https://pan.baidu.com/s/1QJRS8eyZXQt44wBwNyZ6eQ 下载电影相关的五个csv文件
将五个csv文件放到neo4j的import目录中
利用neo4j的语句,将import中的五个csv文件的数据加载到neo4j数据库中
逐步执行下面的五个Load语句
找到neo4j的安装路径,并在D:\neo4j-community-3.4.0\目录下创建import目录
完整路径如下D:\neo4j-community-3.4.0\import
因为neo4j支持导入csv文件,其默认目录入口是 ...\import
//导入节点 电影类型 == 注意类型转换
LOAD CSV WITH HEADERS FROM "file:///genre.csv" AS line
MERGE (p:Genre{gid:toInteger(line.gid),name:line.gname})
//导入节点 演员信息
LOAD CSV WITH HEADERS FROM 'file:///person.csv' AS line
MERGE (p:Person { pid:toInteger(line.pid),birth:line.birth,
death:line.death,name:line.name,
biography:line.biography,
birthplace:line.birthplace})
// 导入节点 电影信息
LOAD CSV WITH HEADERS FROM "file:///movie.csv" AS line
MERGE (p:Movie{mid:toInteger(line.mid),title:line.title,introduction:line.introduction,
rating:toFloat(line.rating),releasedate:line.releasedate})
// 导入关系 actedin 电影是谁参演的 1对多
LOAD CSV WITH HEADERS FROM "file:///person_to_movie.csv" AS line
match (from:Person{pid:toInteger(line.pid)}),(to:Movie{mid:toInteger(line.mid)})
merge (from)-[r:actedin{pid:toInteger(line.pid),mid:toInteger(line.mid)}]->(to)
//导入关系 电影是什么类型 == 1对多
LOAD CSV WITH HEADERS FROM "file:///movie_to_genre.csv" AS line
match (from:Movie{mid:toInteger(line.mid)}),(to:Genre{gid:toInteger(line.gid)})
merge (from)-[r:is{mid:toInteger(line.mid),gid:toInteger(line.gid)}]->(to)导完之后,可看到数据里多了一些节点和关系
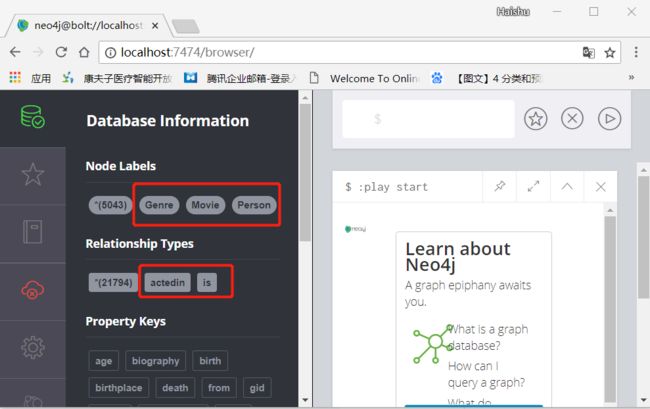
查询“章子怡演了哪些电影”
match(n:Person)-[:actedin]->(m:Movie) where n.name='章子怡' return m.title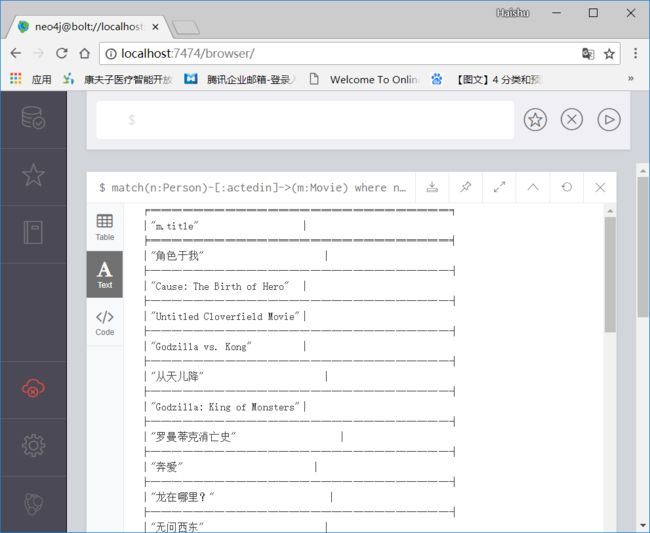
查询一下关系actedin有哪些

加入少儿信息学奥赛QQ群请扫左侧二维码,关注微信公众号请扫右侧二维码
