09#R语言实现决策树分析
决策树是附加概率结果的一个树状的决策图,是直观的运用统计概率分析的图法。机器学习中决策树是一个预测模型,它表示对象属性和对象值之间的一种映射,树中的每一个节点表示对象属性的判断条件,其分支表示符合节点条件的对象。树的叶子节点表示对象所属的预测结果。
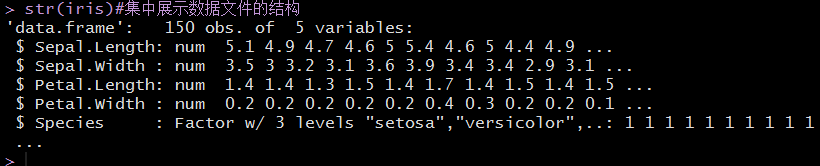
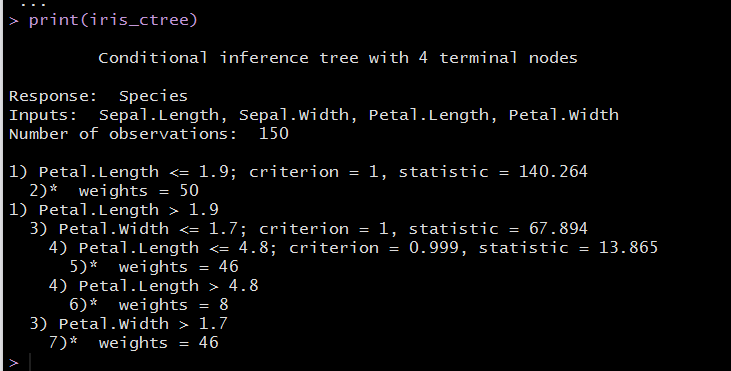
这一节学习使用包party里面的函数ctree()为数据集iris建立一个决策树。属性Sepal.Length(萼片长度)、Sepal.Width(萼片宽度)、Petal.Length(花瓣长度)以及Petal.Width(花瓣宽度)被用来预测鸢尾花的Species(种类)。在这个包里面,函数ctree()建立了一个决策树,predict()预测另外一个数据集。
在建立模型之前,iris(鸢尾花)数据集被分为两个子集:训练集(70%)和测试集(30%)。使用随机种子设置固定的随机数,可以使得随机选取的数据是可重复利用的。
#iris的决策树分析(二)install.packages("party")library("party") #导入数据包
str(iris)#集中展示数据文件的结构
#构建决策树iris_ctree<-ctree(Species ~ Sepal.Length+ Sepal.Width+ Petal.Length+ Petal.Width,data=iris)#查看决策树信息print(iris_ctree)
#构建完的决策树图plot(iris_ctree)

plot(iris_ctree, type="simple")

iris的决策树分析(二)
install.packages("party")library("party") #导入数据包str(iris)#集中展示数据文件的结构#构建决策树iris_ctree<-ctree(Species ~ Sepal.Length+ Sepal.Width+ Petal.Length+ Petal.Width,data=iris)#查看决策树信息print(iris_ctree)#构建完的决策树图plot(iris_ctree)# 决策树案例拟合图plot(iris_ctree, type="simple")
决策树(decision tree) 决策树是使用类似于一棵树的结构来表示类的划分,树的构建可以看成是变量(属性)选择的过程,内部节点表示树选择那几个变量(属性)作为划分,每棵树的叶节点表示为一个类的标号,树的最顶层为根节点。
ID3, C4.5和CART均采用贪心算法,自顶向下递归的分治方式构造,从训练数据集和他们相关联的类标号开始构造树。随着树的构造,训练数据集递归的划分成较小的子集。
算法当中三个重要的参数:D 训练数据集和类标号 ,Attitude_list 描述观测的变量(属性)列表,Attribute_selection_list变量(属性)选择度量,确定一个分裂准侧(splitting criterion),这种分裂准则选择哪些变量(属性)为按类“最好的”进行划分,也确定分枝选择哪些观测的为“最好的划分”。即分裂准则可以确定分裂 变量(属性),也可以确定分裂点(splitting--point),使最后分裂的准则尽可能的“纯”,“纯”表示所有观测都属于同一类,常用的有信息 增益,增益率,Gini指标作为度量。
信息增益:ID3使用信息增益,假定D中类标号变量(属性)具有m个值,定义m个不同的类C(i)(i=1,2---m),C(i,d)是D中C(i)类的元组的集合,|D|和|C(i,D)|分别是D,C(i,D)中的个数。
决策树在构造过程中,由于数据中含有噪声和离群点等异常数据,训练出来的树的分枝会过分拟合数据,处理过分拟合的办法是对树进行剪枝,剪枝后的树更 小,复杂度更低,而且容易理解,常用的剪枝办法有,先剪枝和后剪枝。 R语言中实现决策树的包rpart; 1,生成树:rpart()函数 raprt(formular,data,weight,subset,na.action=na.rpart,method,model=FALSE,x=FALSE,y=TRUE,parms,control,cost,...) fomula :模型格式形如 outcome~ predictor1+ predictor2+ predictor3+ect。 data :数据。 na.action:缺失数据的处理办法,默认为删除因变量缺失的观测而保留自变量缺失的观测。 method:树的末端数据类型选择相应的变量分割方法,连续性method=“anova”,离散型使用method=“class”,,计数型 method=“poisson”,生存分析型method=“exp”。 parms:设置三个参数,先验概率,损失矩阵,分类矩阵的度量方法。 control:控制每个节点上的最小样本量,交叉验证的次数,复杂性参量:cp:complexity pamemeter。 2,剪枝使用 prune(tree,cp,....) tree常是rpart()的结果对象,cp 复杂性参量 3 显示结果的语句 printcp( fit )显示复杂性表 plotcp( fit )画交叉验证结果图 rsq.rpart( fit )R-squared 和 relative error for different splits (2 plots). labels are only appropriate for "anova" method. print( fit )打印结果 summary( fit )基本信息 plot( fit )画决策树 text( fit )给树添加标签 post( fit, file=)保存结果ps,pdf,等格式 # Classification Tree with rpart
library(rpart)
# grow tree
fit <- rpart(Kyphosis ~ Age + Number + Start,
method="class", data=kyphosis)
printcp(fit) # display the results
plotcp(fit) # visualize cross-validation results
summary(fit) # detailed summary of splits
# plot tree
plot(fit, uniform=TRUE,
main="Classification Tree for Kyphosis")
text(fit, use.n=TRUE, all=TRUE, cex=.8)
# create attractive postscript plot of tree
post(fit, file = "G:/dataplay/tree.ps",
title = "Classification Tree for Kyphosis")pfit<- prune(fit, cp= fit$cptable[which.min(fit$cptable[,"xerror"]),"CP"])
# plot the pruned tree
plot(pfit, uniform=TRUE,
main="Pruned Classification Tree for Kyphosis")
text(pfit, use.n=TRUE, all=TRUE, cex=.8)
post(pfit, file = "G:/dataplay/ptree.ps",
title = "Pruned Classification Tree for Kyphosis")