慕课网Python3.x开发简单爬虫及完整源码
Python开发简单爬虫
源码网址: http://download.csdn.net/detail/hanchaobiao/9860671
一、爬虫的简介及爬虫技术价值
1.什么是爬虫:
一段自动抓取互联网信息的程序,可以从一个URL出发,访问它所关联的URL,提取我们所需要的数据。也就是说爬虫是自动访问互联网并提取数据的程序。

2.爬虫的价值
将互联网上的数据为我所用,开发出属于自己的网站或APP
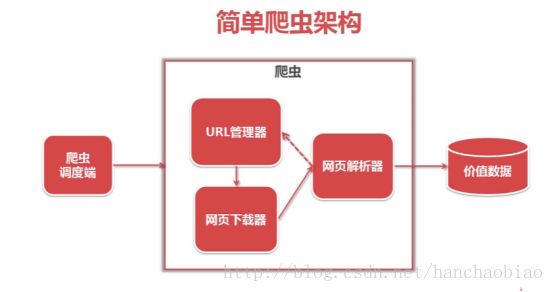
二、简单的网络爬虫流程架
爬虫调度端:用来启动、执行、停止爬虫,或者监视爬虫中的运行情况
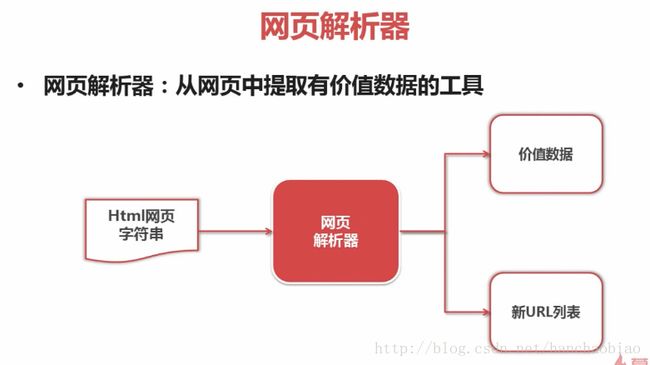
在爬虫程序中有三个模块URL管理器:对将要爬取的URL和已经爬取过的URL这两个数据的管理
网页下载器:将URL管理器里提供的一个URL对应的网页下载下来,存储为一个字符串,这个字符串会传送给网页解析器进行解析
网页解析器:一方面会解析出有价值的数据,另一方面,由于每一个页面都有很多指向其它页面的网页,这些URL被解析出来之后,可以补充进URL管理 器
这三部门就组成了一个简单的爬虫架构,这个架构就能将互联网中所有的网页抓取下来
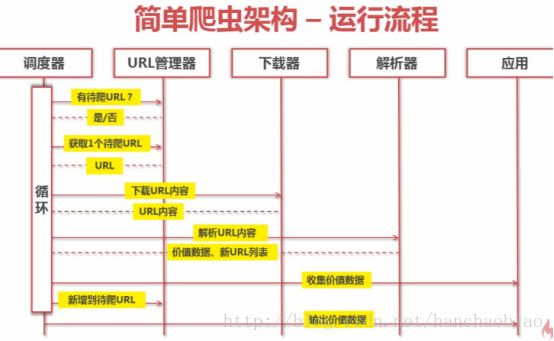
动态执行流程
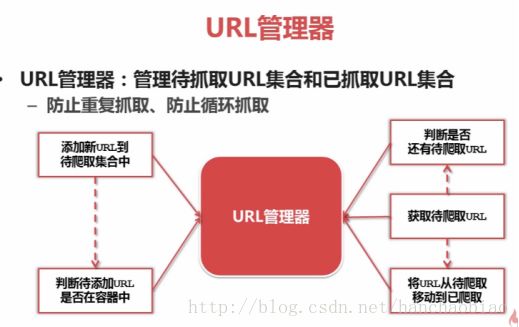
三、URL管理器及三种实现方式
防止重复抓取和循环抓取,最严重情况两个URL相互指向就会形成死循环
三种实现方式
Python内存set集合:set集合支持去重的作用
Mysql:url(访问路径)is_crawled(是否访问)
Redis:使用Redis性能最好,且Redis中也有set类型,可以去重。不懂得同学可以看下Redis的介绍

四、网页下载器和urlib模块
本文使用urllib实现
urllib2是python自带的模块,不需要下载。
urllib2在python3.x中被改为urllib.request
三种实现方式
方法一:
#引入模块
from urllib import request
url = "http://www.baidu.com"
#第一种下载网页的方法
print("第一种方法:")
#request = urllib.urlopen(url) 2.x
response1 = request.urlopen(url)
print("状态码:",response1.getcode())
#获取网页内容
html = response1.read()
#设置编码格式
print(html.decode("utf8"))
#关闭response1
response1.close()方法二:
print("第二种:")
request2 = request.Request(url)
request2.add_header('user-agent','Mozilla/5.0')
response2 = request.urlopen(request2)
print("状态码:",response2.getcode())
#获取网页内容
htm2 = response2.read()
#调整格式
print(htm2.decode("utf8"))
#关闭response1
response2.close()方法三:使用cookie
#第三种方法 使用cookie获取
import http.cookiejar
cookie = http.cookiejar.LWPCookieJar()
opener = request.build_opener(request.HTTPCookieProcessor(cookie))
request.install_opener(opener)
response3 = request.urlopen(url)
print(cookie)
html3 = response3.read()
#将内容格式排列
print(html3.decode("utf8"))
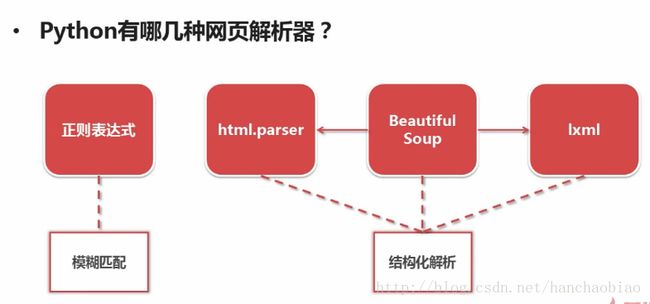
response3.close()五、网页解析器和BeautifulSoup第三方模块
测试是否安装bs4
import bs4
print(bs4)
打印结果:
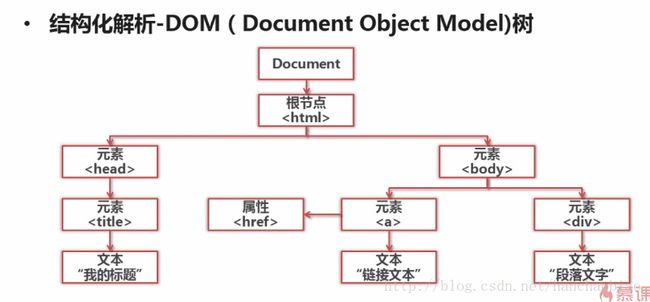
则安装成功 Beautiful Soup 相比其他的html解析有个非常重要的优势。html会被拆解为对象处理。全篇转化为字典和数组。
相比正则解析的爬虫,省略了学习正则的高成本,本文使用python3.x系统自带不需要安装。
使用案例:http://blog.csdn.net/watsy/article/details/14161201
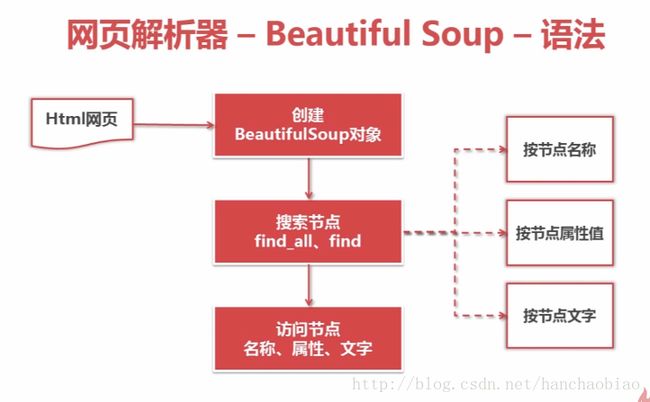
方法介绍

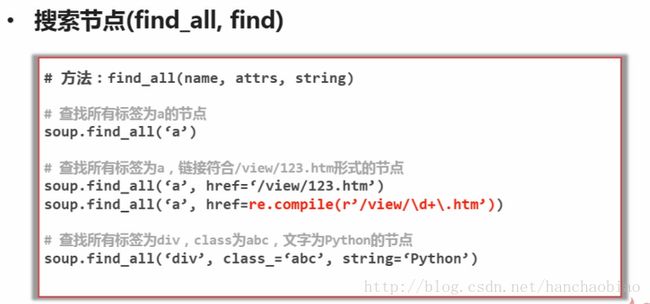

实例测试
html采用官方案例
#引用模块
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""获取所有的链接
print("获取所有的链接")
links = soup.find_all('a') #a标签
for link in links:
print(link.name,link['href'],link.get_text())#获取href=http://example.com/lacie的链接
print("获取lacie链接")
link1 = soup.find('a',href="http://example.com/lacie")
print(link1.name,link1['href'],link1.get_text())print("正则匹配 href中带有“ill”的")
import re #导入re包
link2 = soup.find('a',href=re.compile(r"ill"))
print(link2.name,link2['href'],link2.get_text())print("获取p段落文字")
link3 = soup.find('p',class_="title") #class是关键字 需要加_
print(link3.name,link3.get_text())六、爬虫开发实例(目标爬虫百度百科)

入口:http://baike.baidu.com/item/Python
分析URL格式:防止访问无用路径 http://baike.baidu.com/item/{标题}
数据:抓取百度百科相关Python词条网页的标题和简介
通过审查元素得标题元素为 :class="lemmaWgt-lemmaTitle-title"
简介元素为:class="lemma-summary"
页面编码:UTF-8
作为定向爬虫网站要根据爬虫的内容升级而升级如运行出错可能为百度百科升级,此时则需要重新分析目标
代码集注释:
创建spider_main.py
#创建类
from imooc.baike_spider import url_manager,html_downloader,html_output,html_parser
class spiderMain:
#构造函数 初始化
def __init__(self):
#实例化需引用的对象
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownLoader()
self.output = html_output.HtmlOutPut()
self.parser = html_parser.HtmlParser()
def craw(self,root_url):
#添加一个到url中
self.urls.add_new_url(root_url)
count = 1
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print('craw %d : %s' %(count,new_url))
#下载
html_context = self.downloader.downloade(new_url)
new_urls,new_data = self.parser.parse(new_url,html_context)
print(new_urls)
self.urls.add_new_urls(new_urls)
self.output.collect_data(new_data)
#爬一千个界面
if(count==1000):
break
count+=1
except:
print("craw faile")
self.output.output_html()
#创建main方法
if __name__ == "__main__":
root_url = "http://baike.baidu.com/item/Python"
obj_spider = spiderMain()
obj_spider.craw(root_url)创建url_manager.py
class UrlManager:
'url管理类'
#构造函数初始化set集合
def __init__(self):
self.new_urls = set() #待爬取的url
self.old_urls = set() #已爬取的url
#向管理器中添加一个新的url
def add_new_url(self,root_url):
if(root_url is None):
return
if(root_url not in self.new_urls and root_url not in self.old_urls):
#既不在待爬取的url也不在已爬取的url中,是一个全新的url,因此将其添加到new_urls
self.new_urls.add(root_url)
# 向管理器中添加批量新的url
def add_new_urls(self,urls):
if(urls is None or len(urls) == 0):
return
for url in urls:
self.add_new_url(url) #调用add_new_url()
#判断是否有新的待爬取的url
def has_new_url(self):
return len(self.new_urls) != 0
#获取一个待爬取的url
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
创建html_downloader.py
from urllib import request
from urllib.parse import quote
import string
class HtmlDownLoader:
'下载页面内容'
def downloade(self,new_url):
if(new_url is None):
return None
#解决请求路径中含义中文或特殊字符
url_ = quote(new_url, safe=string.printable);
response = request.urlopen(url_)
if(response.getcode()!=200):
return None #请求失败
html = response.read()
return html.decode("utf8")
创建html_parser.py
from bs4 import BeautifulSoup
import re
from urllib import parse
class HtmlParser:
#page_url 基本url 需拼接部分
def _get_new_urls(self,page_url,soup):
new_urls = set()
#匹配 /item/%E8%87%AA%E7%94%B1%E8%BD%AF%E4%BB%B6
links = soup.find_all('a',href=re.compile(r'/item/\w+'))
for link in links:
new_url = link["href"]
#例如page_url=http://baike.baidu.com/item/Python new_url=/item/史记·2016?fr=navbar
#则使用parse.urljoin(page_url,new_url)后 new_full_url = http://baike.baidu.com/item/史记·2016?fr=navbar
new_full_url = parse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self,page_url,soup):
# Python
red_data = {}
red_data['url'] = page_url
title_node = soup.find('dd',class_="lemmaWgt-lemmaTitle-title").find('h1') #获取标题内容
red_data['title'] = title_node.get_text()
#
summary_node = soup.find('div',class_="lemma-summary")
red_data['summary'] = summary_node.get_text()
return red_data
#new_url路径 html_context界面内容
def parse(self,page_url, html_context):
if(page_url is None or html_context is None):
return
#python3缺省的编码是unicode, 再在from_encoding设置为utf8, 会被忽视掉,去掉【from_encoding = "utf-8"】这一个好了
soup = BeautifulSoup(html_context, "html.parser")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls,new_data
创建html_output.py
class HtmlOutPut:
def __init__(self):
self.datas = [] #存放搜集的数据
def collect_data(self,new_data):
if(new_data is None):
return
self.datas.append(new_data)
def output_html(self):
fout = open('output.html','w',encoding='utf8') #写入文件 防止中文乱码
fout.write('\n')
fout.write('\n')
fout.write('\n')
for data in self.datas:
fout.write('\n')
fout.write('%s \n'%data['url'])
fout.write('%s \n'%data['title'])
fout.write('%s \n'%data['summary'])
fout.write(' \n')
fout.write('
\n')
fout.write('\n')
fout.write('\n')
fout.close()
视频网站:http://www.imooc.com/learn/563
源码网址:http://download.csdn.net/detail/hanchaobiao/9860671