YupDB万亿秒查之六脉神剑(下)
YupDB万亿秒查之六脉神剑(下)
YupDB是面向海量数据背景下的多维度、高融合、企业级实时检索数据库。其具备万亿数据量下实时、多维、秒级检索及分析能力,同时还具备数据安全性及完整性高的特点。
YupDB是如何做到万亿数据秒级查询的呢?下面就来了解一下。
1、读写分离
- - - 在绝大多项目中是存在实时数据入库的。这意味着数据在一边生成一边写入数据库中,同时数据库肩负着响应线上系统的功能。在这种情况下,数据库同时支持数据写于数据读取,在有限的磁盘资源情况下,数据的读取于写入之间会相互争抢IO资源,从而相互之间会受到影响。
- - - YupDB在一定程度上解决了这个问题。在数据入库的同时将数据的写入与查询分离开,将两者分到了不同的磁盘上,以起到读写分离,从而减小两者之间的影响,加快数据的查询效率。
- - -具体分为两种读写分离。
A: HDFS数据的读写分离。
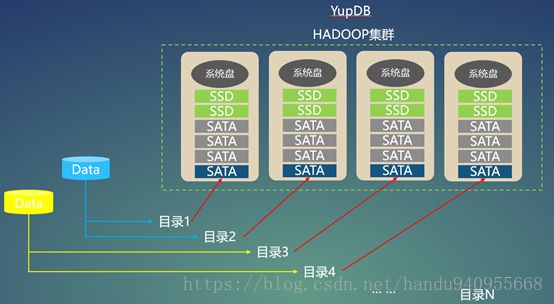
- - - 一个数据再写入HDFS时,会分别写入两个目录。每个目录单份数据副本且指定不同的磁盘存储。这些磁盘用于接收数据和当天数据的查询业务,一天以前的数据全部迁移到其他专制用于查询的磁盘上。以此实现读写分离。
B:索引文件的读写分离。
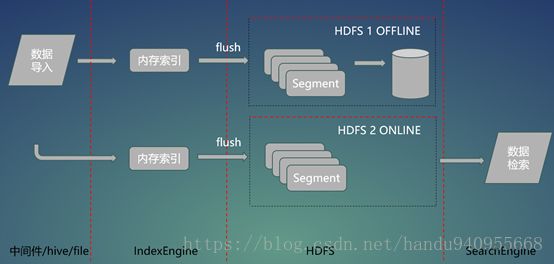
- - - 索引文件的读写分离同样会写两份数据,写入完成以后,一份数据处于在线模式,响应系统的查询请求,另一份数据处于离线模式进行索引合并,当索引合并结束以后,两者功能上进行切换。合并结束的从离线变为在线进行查询响应,另一份处于离线模式进行索引合并。
- - - 以此实现索引的读写分离,加快查询效率。
2、 异步返回。
- - - 在部分业务查询请求中,需要反馈回较大数据量目标数据是一种常见的需求,例如三万、五万。大部分数据库的反馈方式是拿到所有数据以后在进行一次性反回。这种思路在拿到数据后需要进行二次计算的场景时没问题的。但是对于无需进行二次计算,需要快速看到数据(部分数据可接受)的场景并不适合。这种方式需要先拿到所有数据,在返回。YupDB支持异步返回数据,查询命中的数据可以分批次多次返回给用户,每次之返回命中数据的部分。
- - - 这样就不需要等到所有数据拿到后,用户才能看到数据。
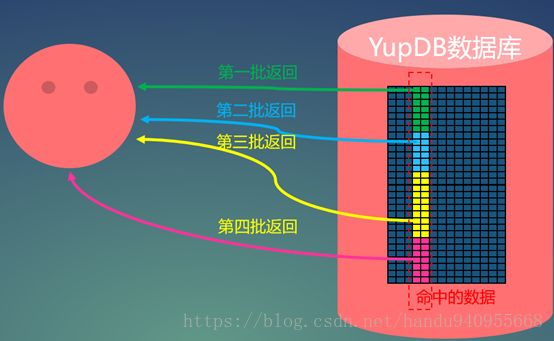
- - - 此场景仅用于可以接受目标数据分批返回的场景。