ELU激活函数的提出(FAST AND ACCURATE DEEP NETWORK LEARNING BY EXPONENTIAL LINEAR UNITS (ELUS))
http://blog.csdn.net/mao_xiao_feng/article/details/53242235?locationNum=9&fps=1
论文下载:
FAST AND ACCURATE DEEP NETWORK LEARNING BY EXPONENTIAL LINEAR UNITS (ELUS)(2016,Djork-Arn´e Clevert, Thomas Unterthiner & Sepp Hochreiter)
一、简介
ELU的表达式:
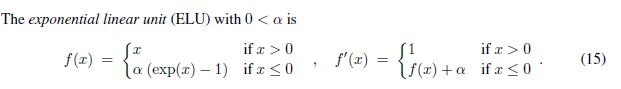
四种激活函数(ELU,LReLU,ReLU,SReLU)比较图:
ELU通过在正值区间取输入x本身减轻了梯度弥散问题(x>0区间导数处处为1),这一点特性这四种激活函数都具备。四者当中只有ReLU的输出值没有负值,所以输出的均值会大于0,当激活值的均值非0时,就会对下一层造成一个bias,如果激活值之间不会相互抵消(即均值非0),会导致下一层的激活单元有bias shift。如此叠加,单元越多时,bias shift就会越大。相比ReLU,ELU可以取到负值,这让单元激活均值可以更接近0,类似于Batch Normalization的效果但是只需要更低的计算复杂度。虽然LReLU和PReLU都也有负值,但是它们不保证在不激活状态下(就是在输入为负的状态下)对噪声鲁棒。反观ELU在输入取较小值时具有软饱和的特性,提升了对噪声的鲁棒性。
二、自然梯度
在描述自然梯度之前,让我们先来看普通梯度,设f(x)=x^2
参数x的变化量和f的变化量可以在一个二维平面坐标系下度量,在这种情形下,可以求得普通的梯度。
但是上述情况基于一个事实:x的变化所引起的f的变化是在一个度量系下的,我们使用了一组正交并且平直坐标系去描述这种变化,数学上把这样的空间称作欧几里德空间,以往我们接触的问题都可以在欧几里德空间下解决(函数优化、求解平面几何等等)
但是在概率分布问题下,欧几里德空间就不好解决了,来举个例子:
在神经网络当中,给定一组数据{x1,x2,x3,……,xN}和一个概率分布模型p(x;W),其中xi={样本zi,标签yi}两部分构成,我们最后要做的就是估计一个W',使得p(x;W')和p(x;W)尽可能的相近。假设对于单个样本x而言,它的概率服从W的一个函数,这个问题是在欧几里德空间可解的
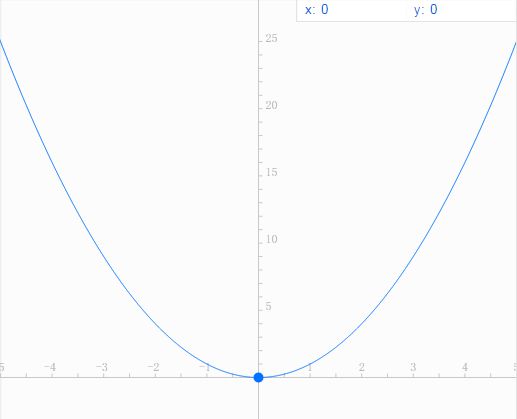
如下图:当我们确定了正态分布的μ和σ时,可以对单个样本给出它的分布函数和概率密度函数
但是我们要求解的并不是这个样本,而是整个数据集的概率分布,这个概率分布随着参数的变化实际上并不能用一个函数来表达,说得更专业一点就是无法在欧几里德空间解这个问题。两个概率分布的距离,在统计学中,是以KL散度来表达的,了解KL散度需要涉及到信息熵和相对熵的问题。http://www.cnblogs.com/hxsyl/p/4910218.html已经给了详细的介绍。
因此可以写出一个分布参数变化前后,相对应的KL散度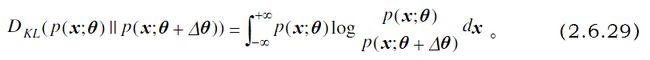
最终问题就变成最小化这个KL散度的问题。(当我们不停的迭代到参数接近模型自身参数的时候,KL散度就达到最小了)
KL散度随着参数变化有最大的变化率,这样决定的梯度,就称为自然梯度了
三、黎曼流形空间
上述KL散度随参数变化的问题,是在黎曼流形空间上的问题。
流形(Manifold)可以理解为受一定约束的某个(一维或多维)变量所有可能状态的集合。其数学定义是:流形是一类拓扑空间,其中每个点都有邻域,而这种邻域与R^n中的单位开球在拓扑上同胚。简单地说,流型从它每个点的邻域来看和 Euclid 空间没有不同;但从总体来看,流形可以是某种“弯曲”的空间,和“平直”的 Euclid 空间不一定相同。三维空间中的球面是流形的一个例子。球面上任何一条经线或纬线是一个子流形。基于球面建立的几何学与 Euclid 几何学是不同的。
事实上,我们不一定要关注流形是什么,我们只需要一个可以表示自然梯度的公式。(以下的推导细节都不重要,你只需要知道最后的形式)

通过这一步,可以进而推导出自然梯度的普通梯度表示:
![]()
最后的公式是我们关注的,它居然和普通梯度仅仅相差了一个矩阵!!
四、fisher信息矩阵
从矩阵的表达形式上来看,它表示了对数似然函数一阶导数的二阶矩。我们希望似然函数的导数更偏离均值,对应的似然函数就越陡峭,这是有利于我们做似然估计的,于是fisher信息又有一种更直观的表达:它对应于我们对于参数估计的准确度,换句话说,就是在一次似然估计中,并不是所有的样本可以全部被这次估计所用,fisher信息,代表了可以用于似然估计的那部分信息。
把所有推理连贯一下:
自然梯度意味着使KL散度变化率最大=>KL散度的变化代表了似然估计的变化=>假设参数的改变,导致了似然函数发生了某一个改变=>这个改变仅仅导致了对于似然估计有用的那部分信息在似然函数里产生的变化。
不看数学的推导,这个公式在实际当中的意义似乎也说得通!
五、ELU的提出
再回到论文,文中提出bias shift就是激活值均值在权重更新的时候的改变(因为普通梯度的更新不会考虑数据的分布)而自然梯度会对这种bias shift进行纠正,如何纠正的,文中用了一个例子以及一系列的数学推导证明了,大致过程就是在原网络上增加了一个bias单元,用自然梯度求解时,发现新增单元会导致fisher信息矩阵上增加一行(用b表示),最终这一行b会影响bias权重和原始权重的更新。
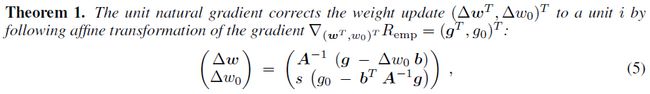
这种影响作者把它称作bias shift correction,它校正了所有的权值更新,去抵消这种bias shift
作者基于这个又提出了一种想法:既然要让激活值的均值不变,是否可以一直让激活函数的均值保持在0,这样就不会发生bias shift,即可以用普通梯度代替自然梯度,最终其效果等同于使用了自然梯度?
最后ELU诞生了,它的形式是
其中α是一个可调整的参数,它控制着ELU负值部分在何时饱和。
ELU实现了两个优点:
1、将前面单元输入的激活值均值控制在0
2、让激活函数的负值部分也可以被使用了(这意思应该是之前的激活函数,负值部分几乎不携带信息,特别是ReLU)
个人观点:不过感觉这种方法其实也是控制层间数据均值不发生偏移,思路和Batch Normalization差不多,只是表达不同罢了。