DeepLab v2论文笔记
摘要:
三个贡献和创新点:
- Atrous CNN;准确调节分辨率,扩大感受野,降低计算量
- ASPP;多尺度特征提取,得到全局和局部特征和语境
- Fully Connected CRF;概率图模型,优化边缘效果
简介
图像语义分割主流方法:
FCN [https://arxiv.org/pdf/1605.06211.pdf]
+ https://github.com/vlfeat/matconvnet-fcn [MatConvNet]
+ https://github.com/shelhamer/fcn.berkeleyvision.org [Caffe]
+ https://github.com/MarvinTeichmann/tensorflow-fcn [Tensorflow]
+ https://github.com/aurora95/Keras-FCN [Keras]
+ https://github.com/mzaradzki/neuralnets/tree/master/vgg_segmentation_keras [Keras]
+ https://github.com/k3nt0w/FCN_via_keras [Keras]
+ https://github.com/shekkizh/FCN.tensorflow [Tensorflow]
+ https://github.com/seewalker/tf-pixelwise [Tensorflow]
+ https://github.com/divamgupta/image-segmentation-keras [Keras]
+ https://github.com/ZijunDeng/pytorch-semantic-segmentation [PyTorch]
+ https://github.com/wkentaro/pytorch-fcn [PyTorch]
+ https://github.com/wkentaro/fcn [Chainer]
+ https://github.com/apache/incubator-mxnet/tree/master/example/fcn-xs [MxNet]
+ https://github.com/muyang0320/tf-fcn [Tensorflow]
+ https://github.com/ycszen/pytorch-seg [PyTorch]
+ https://github.com/Kaixhin/FCN-semantic-segmentation [PyTorch]
+ https://github.com/petrama/VGGSegmentation [Tensorflow]
+ https://github.com/simonguist/testing-fcn-for-cityscapes [Caffe]
+ https://github.com/hellochick/semantic-segmentation-tensorflow [Tensorflow]
PSPNet [https://arxiv.org/pdf/1612.01105.pdf,https://hszhao.github.io/projects/pspnet/]
+ https://github.com/hszhao/PSPNet [Caffe]
+ https://github.com/ZijunDeng/pytorch-semantic-segmentation [PyTorch]
+ https://github.com/mitmul/chainer-pspnet [Chainer]
+ https://github.com/Vladkryvoruchko/PSPNet-Keras-tensorflow [Keras/Tensorflow]
+ https://github.com/pudae/tensorflow-pspnet [Tensorflow]
+ https://github.com/hellochick/PSPNet-tensorflow [Tensorflow]
+ https://github.com/hellochick/semantic-segmentation-tensorflow [Tensorflow]
SegNet [https://arxiv.org/pdf/1511.00561.pdf]
+ https://github.com/alexgkendall/caffe-segnet [Caffe]
+ https://github.com/developmentseed/caffe/tree/segnet-multi-gpu [Caffe]
+ https://github.com/preddy5/segnet [Keras]
+ https://github.com/imlab-uiip/keras-segnet [Keras]
+ https://github.com/andreaazzini/segnet [Tensorflow]
+ https://github.com/fedor-chervinskii/segnet-torch [Torch]
+ https://github.com/0bserver07/Keras-SegNet-Basic [Keras]
+ https://github.com/tkuanlun350/Tensorflow-SegNet [Tensorflow]
+ https://github.com/divamgupta/image-segmentation-keras [Keras]
+ https://github.com/ZijunDeng/pytorch-semantic-segmentation [PyTorch]
+ https://github.com/chainer/chainercv/tree/master/examples/segnet [Chainer]
+ https://github.com/ykamikawa/keras-SegNet [Keras]
DeepLab [https://arxiv.org/pdf/1606.00915.pdf]
+ https://bitbucket.org/deeplab/deeplab-public/ [Caffe]
+ https://github.com/cdmh/deeplab-public [Caffe]
+ https://bitbucket.org/aquariusjay/deeplab-public-ver2 [Caffe]
+ https://github.com/TheLegendAli/DeepLab-Context [Caffe]
+ https://github.com/msracver/Deformable-ConvNets/tree/master/deeplab [MXNet]
+ https://github.com/DrSleep/tensorflow-deeplab-resnet [Tensorflow]
+ https://github.com/muyang0320/tensorflow-deeplab-resnet-crf [TensorFlow]
+ https://github.com/isht7/pytorch-deeplab-resnet [PyTorch]
+ https://github.com/bermanmaxim/jaccardSegment [PyTorch]
+ https://github.com/martinkersner/train-DeepLab [Caffe]
+ https://github.com/chenxi116/TF-deeplab [Tensorflow]
RefineNet:[https://arxiv.org/pdf/1611.06612.pdf]
https://github.com/guosheng/refinenet [MatConvNet]
图像语义分割三个挑战和我们的解决方案:
1.传统分类CNN网络中连续的池化和降采样将导致空间分辨率明显下降
解决方法:去掉最后几层的降采样和最大池化,使用上采样滤波器,得到采样率更高的特征(借鉴于信号处理中方法,有效降低噪声扰动)
2.对象多尺度检测问题
常用方法:重新调节尺度并聚合特征图,但计算量大大增加
本文方法:对特征层重采样,得到多尺度的图像文本信息,使用多个并行ACNN进行多尺度采样,称为ASPP
3.以物体为中心的分类,需要保证空间转换不变性
解决方法:跳跃层结构,从多个网络层中抽取高层次特征进行预测;使用全连接条件随机场进行边界预测优化。
本文模型优势:
- 速度:因为有Atrous的优势,处理速度在Titan GPU上达到8FPS,CRF在CPU上0.5s
- 准确率:在多个数据集上达到最优效果。
- 简洁:由DCNN和CRF组成的级联网络
相关工作
1.传统的图像语义分割方法
2.三类基于深度学习的方法:
- bottom-up 先提取proposal,针对其利用CNN进行预测(分割和预测是分开)
- DCNN特征 for dense image labeling(利用全局特征进行像素点预测)
- DCNN+FCN,将最后全连接层替换为FCN,将得到的特征图进行转置卷积和上采样,预测每个像素点的labels
3.在各个数据集比赛中达到最好效果,同时许多排名较高的模型均使用了
Atrous convoluton layer 和 FCN + CRF

4.发展方向: 对于预测结构提供端到端的训练方法; 弱监督分类
方法
i.稠密特征提取的空洞卷积和感受野的扩充
问题:传统DCNN但对于连续的最大池化和降采样导致最后的特征图分辨率严重下降,一般使用FCN,但会带来增加内存和计算时间的问题
解决方法:提出Atrous convolution
Atrous Convolution解释:

- 来源于信号处理,对于输入信号,使用长度为K的滤波器加入r采样率进行采样:
- 对于CNN中如果进行降采样后会出现特征图分辨率降低,而如果改用Atrous,可有效增加特征图分辨率。在最后的特征聚合层,用Atrous代替全连接层。
起初尝试在所有池化层均加入Atrous,增加效果,但计算量太大;改为factor 4和8,保证计算量和准确度。
方法:a.插入空值,保证计算参数不变;b.提取不同尺度的像素信息,插入对应空值,提高感受野的同时能捕捉不同尺度信息。
问题:(rate如何计算?为何Atrous有效?具体如何实现?)
ii.多尺度空间金字塔池化
ASPP从何而来?为何有效?
借鉴SPP网络,多尺度重采样可有效增强特征图效果。


iii.条件随机场预测边界
先前工作主要两方面:a.通过将多个卷积层的输出综合来预估边界;b.用超像素来描述,作为一个简单的定位任务。
本文观点:通过全连接条件随机场来作为识别和定位任务的结合,既能准确定位,还能保证一定的准确率。

分析:传统方法,假设空间相邻节点具有相似性,作为一个弱监督的方法去预测边缘相似节点的labels,可有效消除噪声,让分割边缘更加平滑。而DCNN中不是要让特征图更平滑,而是要发掘特征图中的细节,比如边缘部分的分割效果,这时使用short-range CRF反而会带来不好的效果。
本文使用方法:在不同特征空间使用两个高斯核函数,第一个bilateral kernel定义所有像素的位置和颜色,第二个核函数只定义像素的位置。
作用:第一个核函数对于位置和颜色相似的像素归为相似的标签;第二个核函数仅保证处理平滑度时保证空间相似性。
技巧:使用高维度过滤器算法可大大加速计算过程。
结果
测试数据集:PAS VOL2012,PASCAL-CONTEXT,PASCAL-Person-Part,Cityscapes
比较内容:
1.横向比较:DeepLab和其他算法的mIOU比较,达到state of the art.

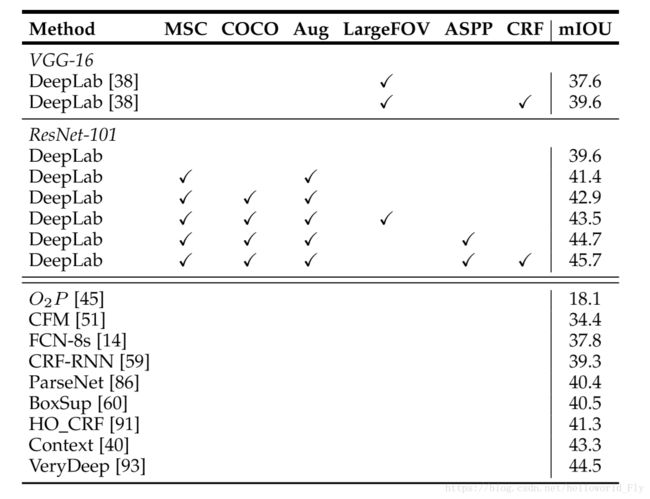

2.纵向比较:初始网络(VGG-16,Res-101),是否加入数据增强,是否扩大感受野,是否加入CRF,是否使用ASPP,


最后分析不好的结果:对于边缘太细的自行车或者椅子,出现错误,主要是因为计算结果置信度太低,可能编码-解码方法有更好的效果,未来研究方向。