深度学习表征的不合理有效性——从头开始构建图像搜索服务(二)
摘要:还在为搜索引擎的工作原理感到困惑吗?看完本篇就可以自己动手构建搜图服务了。
接着上篇《深度学习表征的不合理有效性——从头开始构建图像搜索服务(一)》的内容,上次遇到的问题是搜索相似图的时候还是会出现瑕疵,因此本文介绍相关的处理办法。
半监督搜索
解决上文问题的常用方法是,首先使用目标检测模型,检测猫图像,然后对原始图像裁剪之后再进行图像搜索,这样做会很大程度地增加计算开销,如果可能的话,希望能够避免这种开销。
有一种更简单的“hacky”方法,包括重新权衡激活值,这可以通过加载最初丢弃的最后一层权重来完成,并且仅使用与正在寻找的类索引相关联的权重来重新加权嵌入。例如,在下图中,使用Siamese cat类的权重来重新权衡数据集上的激活(用绿色突出显示)。
 加权嵌入
加权嵌入
根据Imagenet,Siamese cat中的284类权衡激活,来研究它是如何工作的。
正在搜索类似的图像todataset / bottle / 2008_000112.jpg使用加权特征:
 图像13
图像13

可以看到,搜索一直偏向于寻找Siamese cat的照片,而不再展示任何的瓶子图像,此外,可能会注意到最后一张照片是一只羊!这就非常有趣了,此时的模型又导致了另外一种不同类型的错误,但模型更适合目前的任务需求。
从上面的结果可以看出,通过宽泛方式搜索类似的图像,或者通过调整模型所训练的特定类别,使得模型向前迈出的了一大步,但由于使用的是在Imagenet上预训练的模型,因此仅限于1000个Imagenet类别。这些类别不能包罗万象,所以希望找到更加灵活的东西。另外,如果我们只是在不提供输入图像的情况下搜索猫呢?
为了做到这一点,使用的不仅仅是简单的技巧,还需利用一个能够理解单词语义能力的模型。
文本-->文本
嵌入文本
下面进入自然语言处理(NLP)世界,可以使用类似的方法来索引和搜索单词。
从GloVe加载了一组预先训练的矢量,这些矢量是通过从维基百科上爬虫并学习该数据集中单词之间的语义关系而获得的。
像之前一样创建一个索引,这次包含所有GloVe向量。之后就可以在嵌入中搜索类似的单词。
例如,搜索said,返回[word,distance]列表:
- ['said', 0.0]
- ['told', 0.688713550567627]
- ['spokesman', 0.7859575152397156]
- ['asked', 0.872875452041626]
- ['noting', 0.9151610732078552]
- ['warned', 0.915908694267273]
- ['referring', 0.9276227951049805]
- ['reporters', 0.9325974583625793]
- ['stressed', 0.9445104002952576]
- ['tuesday', 0.9446316957473755]
这似乎非常合理,大多数单词在含义上与我们的原始单词非常相似,或代表一个合适的概念。最后的结果(tuesday)也表明这个模型存在一些瑕疵,但它会让我们这种方法会让我们开始起步。现在,让我们尝试在模型中既包含单词,又包含图像。
一个大问题
使用嵌入之间的距离作为搜索方法似乎看起来非常合理,大多数单词在含义上与原始单词非常相似,但对单词和图像的表示似乎并不兼容。图像的嵌入大小为4096,而单词的嵌入大小为300,如何使用一个来搜索另一个?此外,即使两个嵌入大小都相同,它们也会以完全不同的方式进行训练,因此图像和相关单词很可能不会发生有随机相同的嵌入。因此,需要训练一个联合模型。
图像<-->文本
现在创建一个混合模型,可以从单词到图像,反之亦然。
在本教程中,将第一次实践自己的模型,模型是从一篇名为DeViSE的优秀论文中汲取灵感。我们的想法是通过重新训练图像模型,并改变其标签的类型来结合这两种表示。
通常,图像分类器被训练为从许多类中选择一个类别(Imagenet为1000类)。以Imagenet为例,转化最后一层为大小1000的一维向量来表示每个类的概率。这意味着模型没有语义理解哪些类与其他类相似,即将猫的图像分类为狗导致与将其分类为飞机的错误是一样的。
对于混合模型,用我们的类别单词向量替换模型的最后一层,这允许模型学习到将图像语义映射到单词语义,这也意味着类似的类将彼此更接近(因为cat的单词向量比airplane更靠近dog)。我们将预测一个大小为300的语义丰富的单词向量,而不是大小为1000的单词向量,通过添加两个全连接层来实现此目的:
- 一个大小为2000的中间层
- 一个大小为300的输出层(GloVe单词向量的大小)
以下是在Imagenet上训练模型时的样子:
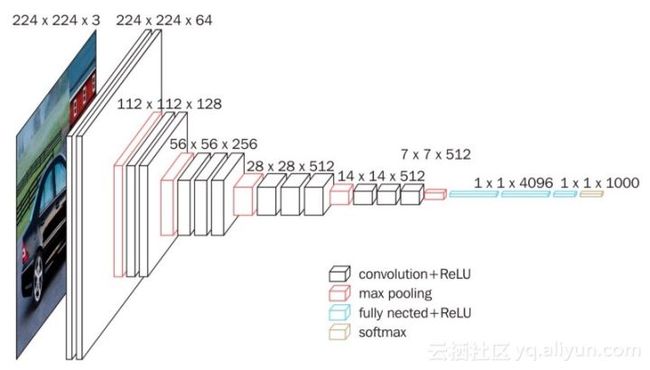
这是修改后模型的样子:
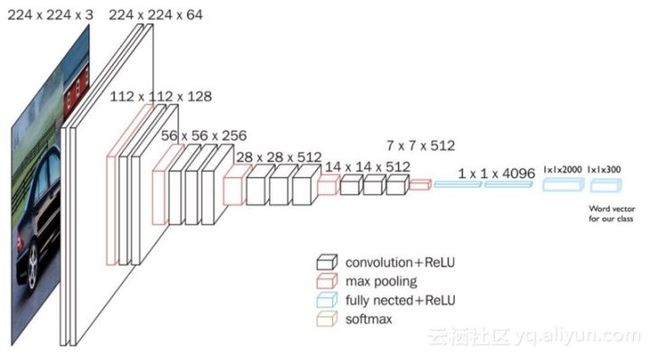
训练模型
在数据集的训练集上重新训练我们的模型,以学习预测与图像标签相关联的单词向量。例如,对于具有类别cat的图像,尝试预测与cat相关联的300长度向量。训练需要一些时间,但这仍然要比Imagenet训练快得多。
与通常的数据集相比,本文使用的训练数据(数据集的80%作为训练集,即800个图像)是微不足道的(Imagenet有一百万张图像)。如果使用传统的类别训练技术,我们不会指望模型在测试集上表现得非常好,并且也不会期望它在全新的例子上有不错的效果。
一旦模型被训练好,就可以从上面获得GloVe单词索引,并通过运行数据集中的所有图像,将其保存到磁盘,构建图像特征的新快速索引。
标注
现在可以轻松地从任何图像中提取标签,只需将我们的图像提供给训练有素的网络,保存出来的大小为300的矢量,并从GloVe中找到英语单词索引中最接近的单词。让我们试试下面这张图片——它的类别标签是瓶子,虽然它包含各种各样的物品。
图像16
以下是生成的标签:
- [6676, 'bottle', 0.3879561722278595]
- [7494, 'bottles', 0.7513495683670044]
- [12780, 'cans', 0.9817070364952087]
- [16883, 'vodka', 0.9828150272369385]
- [16720, 'jar', 1.0084964036941528]
- [12714, 'soda', 1.0182772874832153]
- [23279, 'jars', 1.0454961061477661]
- [3754, 'plastic', 1.0530102252960205]
- [19045, 'whiskey', 1.061428427696228]
- [4769, 'bag', 1.0815287828445435]
是一个非常好的结果,因为大多数标签非常相关。这种方法仍然有提升空间,但它可以很好地掌握图像中的大多数元素。该模型学习提取许多相关标签,甚至从未经过训练的类别中提取到的!
使用文本搜索图像
最重要的是,可以使用联合嵌入,输入任何单词都可以搜索图像数据库。只需要从GloVe获取预先训练好的单词嵌入,并找到具有最相似嵌入的图像即可。
使用最少数据进行广义图像搜索。
首先从搜索dog这个词开始:
 搜索dog术语的结果
搜索dog术语的结果
结果相当不错,但是我们可以从标签上训练的任何分类器中都得到这个!
搜索ocean术语的结果。
模型了解ocean与water类似,并从boat类中返回许多物品。
搜索街道又会发生什么呢?
 搜索“street”的结果
搜索“street”的结果
从图中可以看到,返回的图像来自各种类别(car,dog,bicycle,bus,person),但大多数图像都包含或靠近街道,尽管我们在训练模型时从未使用过这个概念。因为通过预先训练的单词向量,利用外部知识来学习比简单类别在语义上更丰富的图像向量映射,所以模型可以很好地概括为外部概念。
无以言表
英语虽然已经发展了很久,但还不足以为一切都有对应的词。例如,没有英文单词表示“躺在沙发上的猫”,但这是一个对输入搜索引擎完全有效的查询。如果想要同时搜索多个单词,就可以使用一种非常简单的方法,即利用单词向量的算术属性。事实证明,总结两个单词向量通常是非常有效的。因此,如果只是通过使用猫和沙发的平均单词矢量来搜索我们的图像,就可以希望获得非常像猫、像沙发一样的图像、或者在沙发上有猫的图像。
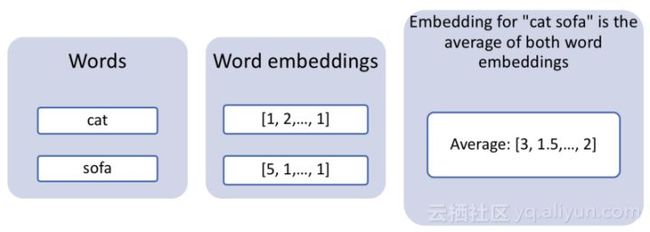 多个单词的组合嵌入
多个单词的组合嵌入
下面使用混合嵌入搜索
 搜索sofa+cat的结果
搜索sofa+cat的结果
从图中可以看到,结果不错。因为大多数图像都包含一些毛茸茸的动物和一个沙发。我们的模型只训练单个单词,也可以处理两个单词的组合,但还没有构建Google Image Search,但对于相对简单的架构来说,本文绝对是有用的。
这种方法实际上可以很自然地扩展到各种域,感兴趣的读者可以应用于各自的领域之中。
结论
希望读者能够发现这篇文章内容的丰富,它揭开了一些基于内容的推荐和语义搜索世界的神秘面纱,感兴趣的读者快上手试试吧。
以上为译文,由阿里云云栖社区组织翻译。
译文链接
文章原标题《The unreasonable effectiveness of Deep Learning Representations》
译者:海棠,审校:Uncle_LLD。
文章为简译,更为详细的内容,请查看原文。