吴恩达机器学习:异常检测与协同过滤
这是吴恩达机器学习的最后一课,这次学习的内容是机器学习的常见应用,异常检测与协同过滤。课程中介绍的异常检测主要基于 正态分布,用于检测出偏离正常值的数据。而协同过滤是 推荐系统 的一部分,利用已有用户的评分来给你推荐商品、视频等。
点击 课程视频 你就能不间断地学习 Ng 的课程,关于课程作业的 Python 代码已经放到了 Github 上,点击 课程代码 就能去 Github 查看( 无法访问 Github 的话可以点击 Coding 查看 ),代码中的错误和改进欢迎大家指出。
以下是 Ng 机器学习课程第八周的笔记。
异常检测
通常使用异常检测的情况是在一个含有正常和异常的数据集中,异常样本数目远小于正常样本数目,使得无法从异常数据中提取有效的特征。于是只能通过学习正常数据的分布来识别异常数据。具体来说,我们通过数据学习一个概率模型 p(x) p ( x ) ,并通过一个阈值 ϵ ϵ 来判断数据是否异常。从直观上来理解正常数据虽然由于误差等原因有所偏离,但基本都还在一个区域范围内,而异常数据则会离这个区域比较远( 如下图,红圈里的可以看做异常值 )。
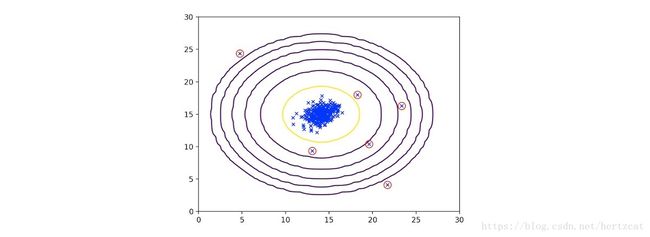
算法
在异常检测中,假设特征是相互独立的而且服从正态分布 xj∼N(μj,δ2j) x j ∼ N ( μ j , δ j 2 ) ,所以:
然后我们只要通过数据计算 μi μ i 和 δi δ i 就可以得到 p(x) p ( x ) 了,于是有如下算法:
- 选择有助于区分异常数据的特征 xi x i
- 分别计算 μ1,...,μn,δ21,...,δ2n μ 1 , . . . , μ n , δ 1 2 , . . . , δ n 2 :
μjδ2j=1m∑i=1mx(i)j=1m∑i=1m(x(i)j−μj)2 μ j = 1 m ∑ i = 1 m x j ( i ) δ j 2 = 1 m ∑ i = 1 m ( x j ( i ) − μ j ) 2- 对于需要检测异常的数据 x x 计算 p(x) p ( x ) ,如果 p(x)<ϵ p ( x ) < ϵ 则判断为异常。
算法在特征比较多时计算效率比较高,而且在通常情况下即使特征不独立也能够得到比较好的结果。如果特征比较少并且特征之间又相互关联的情况,这时候我们可以使用 多元正态分布 来作为模型,此时 p(x) p ( x ) 为:
式中的 Σ Σ 为 协方差矩阵,在之前的课程笔记中有提到。
ϵ ϵ 选择
由于我们的数据有 偏斜类 的问题,所以需要用 查准率 和 召回率 的结合 F1 F 1 指数来评价模型,并选取 F1 F 1 取最大时对应的 ϵ ϵ 作为阈值。
协同过滤
假设我们有 nm n m 部影片,并且有 nu n u 位用户对于其中一些影片的评价 y(i,j) y ( i , j ) ,。
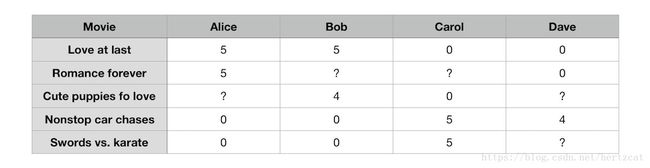
其中用户对有些影片没有打分,我们希望能够估计这些评分并推荐高分的内容给用户。用户 j j 有没有给 i i 电影评分记为 R(i,j) R ( i , j ) 。假设每部电影具有特征向量 x(i) x ( i ) ,对于用户 (1) ( 1 ) ,我们像 线性回归 中那样学习一个 hθ(x)=θ(1)0+θ(1)1x1+θ(1)2x2+⋯+θ(1)nxn h θ ( x ) = θ 0 ( 1 ) + θ 1 ( 1 ) x 1 + θ 2 ( 1 ) x 2 + ⋯ + θ n ( 1 ) x n 来获取用户没有打分的评分。可以看出对于所有用户,评分表可以表示为电影特征矩阵和用户参数矩阵的乘积:
预测的评分 Predicated=XΘT P r e d i c a t e d = X Θ T ,值得注意的是 X,Θ X , Θ 都是未知的,它们都是需要学习的变量。
代价函数
确定了学习模型,下一步就是要设定 代价函数。这次的 代价函数 和之前基本相同,不同的是在计算梯度的时候 X,Θ X , Θ 都需要求。下面直接给出 代价函数:
通过简单的求导可以得到梯度公式:
和之前的学习算法相同,我们只需要实现 代价函数 的部分并计算梯度值,调用 minimize 函数来获取最优解就可以了。有了 X,Θ X , Θ 的值,我们就能够得到预测的评分,通过评分高低就能够进行推荐啦。
课程总结
吴恩达机器学习课程作为对机器学习基本的了解还是不错的。但是课程的内容比较老,像 深度学习、强化学习 等内容都没有涉及,缺乏概率方面的视角,工程方面也只是提了一点点,这些也正是今后需要继续学习的内容。
当驶向 机器学习之海 的时候,感觉心中有一个方向很重要,即便它有多么的不切实际。
So~,第八周的内容就是这些了,谢谢大家耐心阅读。