OpenFace学习(2):FaceNet+SVM匹配人脸
前言
在前面的博客中(OpenFace学习(1):安装配置及人脸比对),介绍了OpenFace的安装配置,以及一个人脸匹配的demo。其中只是匹配了几张图片中人脸,对每个人脸的特征向量很粗略地采用欧氏距离测量,效果也还不错。本文中将使用SVM来对每个人脸的特征向量进行分类,进行人脸比对。
demo
代码文件有四个:
featrure_extract.py:提取人脸信息,每一张人脸提取为一个128维的特征向量;feature_train.py:训练SVM分类器;feature_classify.py:使用SVM分类人脸特征向量。logs.py:控制台打印日志信息配置。
不说废话了,下面直接上代码。
logs.py
# *_*coding:utf-8 *_*
# author: 许鸿斌
# 邮箱:[email protected]
import logging
import sys
# 获取logger实例,如果参数为空则返回root logger
logger = logging.getLogger('Test')
# 指定logger输出格式
formatter = logging.Formatter('%(asctime)s %(levelname)-8s: %(message)s')
# 文件日志
# file_handler = logging.FileHandler("test.log")
# file_handler.setFormatter(formatter) # 可以通过setFormatter指定输出格式
# 控制台日志
console_handler = logging.StreamHandler(sys.stdout)
console_handler.formatter = formatter # 也可以直接给formatter赋值
# 为logger添加的日志处理器
# logger.addHandler(file_handler)
logger.addHandler(console_handler)
# 指定日志的最低输出级别,默认为WARN级别
logger.setLevel(logging.INFO)featrure_extract.py
# *_*coding:utf-8 *_*
# author: 许鸿斌
# 邮箱:[email protected]
from log import logger
import os
import cv2
import time
import openface
import cPickle
# dlib和openface模型配置
imgDim = 96
dlib_model_dir = '/home/xhb/文档/Packages/openface/models/dlib'
openface_model_dir = '/home/xhb/文档/Packages/openface/models/openface'
# 导入dlib人脸特征点检测器
align = openface.AlignDlib(os.path.join(dlib_model_dir, "shape_predictor_68_face_landmarks.dat"))
# 导入FaceNet
net = openface.TorchNeuralNet(os.path.join(openface_model_dir, 'nn4.small2.v1.t7'), imgDim)
def getRep(imgPath, verbose=False):
logger.info("Processing {}.".format(imgPath))
bgrImg = cv2.imread(imgPath)
if bgrImg is None:
raise Exception("Unable to load image: {}".format(imgPath))
rgbImg = cv2.cvtColor(bgrImg, cv2.COLOR_BGR2RGB)
if verbose:
logger.info("Original size: {}".format(rgbImg.shape))
start = time.time()
faceBoundingBox = align.getLargestFaceBoundingBox(rgbImg)
if faceBoundingBox is None:
raise Exception("Unable to find a face: {}".format(imgPath))
if verbose:
logger.info("Face detection took {} seconds.".format(time.time() - start))
start = time.time()
alignedFace = align.align(imgDim, rgbImg, faceBoundingBox, landmarkIndices=openface.AlignDlib.OUTER_EYES_AND_NOSE)
if alignedFace is None:
raise Exception("Unable to align image: {}".format(imgPath))
if verbose:
logger.info("Face alignment took {} seconds.".format(time.time() - start))
start = time.time()
rep = net.forward(alignedFace)
if verbose:
logger.info("OpenFace forward pass took {} seconds.".format(time.time()-start))
logger.info("Representation:")
logger.info(rep)
return rep
pwd = os.getcwd()
img_dir = os.path.join(pwd, 'training_images')
people_name_list = os.listdir(img_dir)
# logger.info(res)
people_rep_dict = {}
for people_name in people_name_list:
face_dir = os.path.join(img_dir, people_name)
img_name_list = os.listdir(face_dir)
# logger.info(img_path_list)
people_rep_list = []
for img_name in img_name_list:
img_path = os.path.join(face_dir, img_name)
# logger.info('Processing: {}'.format(img_path))
rep = getRep(img_path, verbose=False)
people_rep_list.append(rep)
people_rep_dict[people_name] = people_rep_list
logger.info('Face vectors has been generated!')
# logger.info(people_rep_dict)
rep_dir = os.path.join(pwd, 'representation_vectors')
# 保存生成的特征向量
cPickle.dump(people_rep_dict, open(os.path.join(rep_dir, 'rep.pkl'), 'wb'))
logger.info('Vectors saved in {}'.format(os.path.join(rep_dir, 'rep.pkl')))feature_train.py
# *_*coding:utf-8 *_*
# author: 许鸿斌
# 邮箱:[email protected]
from log import logger
import os
import cPickle
from sklearn.svm import SVC
pwd = os.getcwd()
rep_dir = os.path.join(pwd, 'representation_vectors')
people_rep_dict = cPickle.load(open(os.path.join(rep_dir, 'rep.pkl'), 'rb'))
people_names = people_rep_dict.keys()
logger.info(people_names)
nClasses = len(people_names)
label = 0
vector_list = []
label_list = []
for people_name in people_names:
vectors = people_rep_dict[people_name]
label += 1
for vector in vectors:
vector_list.append(vector)
label_list.append(label)
logger.info('vector_list: {}'.format(len(vector_list)))
logger.info('label_list: {}'.format(len(label_list)))
# linearSVM
logger.info('Start training linear svm classifier.')
clf = SVC(C=1, kernel='linear', probability=True)
clf.fit(vector_list, label_list)
# 保存模型和labels
clf_name = 'classifier_{}.pkl'.format('linear_svm')
logger.info('classifier saved as: {}'.format(os.path.join(pwd, clf_name)))
cPickle.dump(clf, open(os.path.join(pwd, clf_name), 'wb'))
labels_name = 'labels.pkl'
logger.info('labels saved as: {}'.format(os.path.join(pwd, labels_name)))
cPickle.dump(people_names, open(os.path.join(pwd, labels_name), 'wb'))
feature_classify.py
# *_*coding:utf-8 *_*
# author: 许鸿斌
# 邮箱:[email protected]
from log import logger
import os
import cPickle
from sklearn.svm import SVC
import cv2
import time
import openface
import numpy as np
# dlib和openface模型配置
imgDim = 96
dlib_model_dir = '/home/xhb/文档/Packages/openface/models/dlib'
openface_model_dir = '/home/xhb/文档/Packages/openface/models/openface'
# 导入dlib人脸特征点检测器
align = openface.AlignDlib(os.path.join(dlib_model_dir, "shape_predictor_68_face_landmarks.dat"))
# 导入FaceNet
net = openface.TorchNeuralNet(os.path.join(openface_model_dir, 'nn4.small2.v1.t7'), imgDim)
def getRep(imgPath, verbose=False, multiple=False):
logger.info("Processing {}.".format(imgPath))
bgrImg = cv2.imread(imgPath)
if bgrImg is None:
raise Exception("Unable to load image: {}".format(imgPath))
rgbImg = cv2.cvtColor(bgrImg, cv2.COLOR_BGR2RGB)
if verbose:
logger.info("Original size: {}".format(rgbImg.shape))
start = time.time()
if multiple:
faceBoundingBoxs = align.getAllFaceBoundingBoxes(rgbImg)
else:
faceBoundingBox = align.getLargestFaceBoundingBox(rgbImg)
faceBoundingBoxs = [faceBoundingBox]
if len(faceBoundingBoxs) == 0 or (not multiple and faceBoundingBox is None):
raise Exception("Unable to find a face: {}".format(imgPath))
if verbose:
logger.info("Face detection took {} seconds.".format(time.time() - start))
reps = []
for bb in faceBoundingBoxs:
start = time.time()
alignedFace = align.align(imgDim, rgbImg, bb, landmarkIndices=openface.AlignDlib.OUTER_EYES_AND_NOSE)
if alignedFace is None:
raise Exception("Unable to align image: {}".format(imgPath))
if verbose:
logger.info("Face alignment took {} seconds.".format(time.time() - start))
logger.info("This bbox is centered at {}, {}".format(bb.center().x, bb.center().y))
start = time.time()
rep = net.forward(alignedFace)
if verbose:
logger.info("OpenFace forward pass took {} seconds.".format(time.time()-start))
# logger.info("Representation:")
# logger.info(rep)
reps.append((bb.center().x, rep))
sreps = sorted(reps, key=lambda x: x[0])
return sreps
pwd = os.getcwd()
clf_name = 'classifier_{}.pkl'.format('linear_svm')
clf = cPickle.load(open(os.path.join(pwd, clf_name), 'r'))
label_name = 'labels.pkl'
labels = cPickle.load(open(os.path.join(pwd, label_name), 'r'))
# logger.info(clf)
# logger.info(labels)
test_image_path = os.path.join(pwd, 'test_images', 'inesta1.jpg')
reps = getRep(test_image_path, multiple=True)
if len(reps) > 1:
logger.info("List of faces in image from left to right")
for r in reps:
rep = r[1].reshape(1, -1)
bbx = r[0]
start = time.time()
pred = clf.predict_proba(rep).ravel()
for name, prob in zip(labels, pred):
logger.info('Probablity of {} is: {}'.format(name, prob))
max_prob_index = np.argmax(pred)
person_name = labels[max_prob_index]
confidence = pred[max_prob_index]
logger.info("Prediction took {} seconds.".format(time.time() - start))
logger.info("Predict {} @ x={} with {:.2f} confidence.".format(person_name.decode('utf-8'), bbx, confidence))
补充说明
代码部分很简单,大部分看看就能懂了,不多做介绍了。稍微补充几个要注意的地方:
1、收集人脸图片
在代码文件同一个目录下建立一个training_images文件夹,其中对应每个人再建立相应的文件夹:

比如说,我这里就直接建了三个文件夹:inesta、obama、trump。
里面对应的就是收集的若干张图片:


注意图片只能包含单张人脸,因为后面要训练SVM分类这些人脸,多张人脸会造成混淆。
2、模型路径
跟上篇博客中一样,需要自己修改一下对应模型的路径。模型下载链接在上篇博客中已给出,请自行下载:OpenFace学习(1):安装配置及人脸比对。
# dlib和openface模型配置
imgDim = 96
dlib_model_dir = '/home/xhb/文档/Packages/openface/models/dlib'
openface_model_dir = '/home/xhb/文档/Packages/openface/models/openface'
# 导入dlib人脸特征点检测器
align = openface.AlignDlib(os.path.join(dlib_model_dir, "shape_predictor_68_face_landmarks.dat"))
# 导入FaceNet
net = openface.TorchNeuralNet(os.path.join(openface_model_dir, 'nn4.small2.v1.t7'), imgDim)imgDim用这里的默认值就可以了,dlib_model_dir是存放dlib的人脸特征点检测器模型(shape_predictor_68_face_landmarks.dat)的路径,openface_model_dir是存放OpenFace开源的FaceNet网络训练好的模型(nn4.small2.v1.t7)的路径。
运行结果
运行featrure_extract.py,会自动解析training_images文件夹中的图片,并将生成的特征向量和标签保存在rep.pkl文件中。
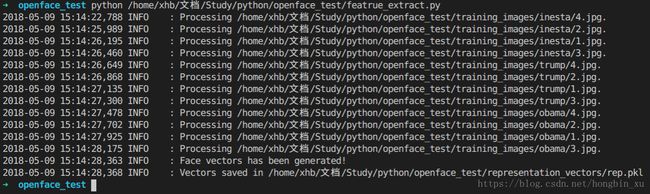
运行feature_train.py,读取rep.pkl中的特征向量,训练SVM分类器。SVM分类器保存在’classifier_linear_svm.pkl’中,标签保存在labels.pkl中。

运行feature_classify.py,对测试图片使用SVM进行分类,给出预测结果。
